

A Technical Guide to Haystack AI
Exploring RAG Pipelines for Enhanced NLP Applications

Introduction
Haystack, an open-source framework from deepset, is transforming how we build production-ready large language model (LLM) applications, retrieval-augmented generative (RAG) pipelines, and state-of-the-art search systems. It simplifies creating powerful search and question-answering systems that handle large volumes of text with ease. Traditional search systems often struggle with understanding complex natural language queries. Haystack overcomes this challenge by integrating cutting-edge machine learning models that excel at interpreting and responding to sophisticated queries. Built to be both flexible and user-friendly, Haystack allows developers to experiment with the latest NLP models effortlessly.
Architecture of Haystack AI
Haystack’s architecture is designed to be modular and flexible, allowing developers to build custom pipelines tailored to their specific needs. It is made of two main architectures: components and pipelines. They can also do looping. Components are entities that take a certain number of inputs and produce a certain number of outputs.
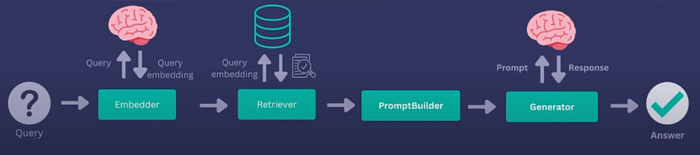
Here’s a brief overview of some of its key components:
- Document Store: The storage system for documents. It can be in-memory or persistent.
- Retriever: Finds relevant documents from the document store based on a query.
- Reader/Generator: Extracts or generates answers from the retrieved documents.
- Pipeline: Connects all components in a sequence to process the input query and generate the final output. Its modular design and pre-built components make it an ideal choice for developing advanced NLP solutions, including RAG pipelines. RAG pipelines blend information retrieval with text generation. They work by first retrieving relevant documents from a storage system and then using these documents to generate accurate and contextually relevant answers. The beauty of Haystack lies in its ability to build customisable pipelines by combining various components like document stores, retrievers, and generators. In this guide, we’ll walk through the process of building a RAG pipeline using Haystack, demonstrating how it can enhance your NLP applications.
Project Overview
The project focuses on providing a hands-on experience with Haystack AI by demonstrating how to create a RAG pipeline that embeds documents, retrieves relevant information, constructs prompts, and generates answers. We chose Google Colab for this project due to its powerful capabilities for running machine learning experiments, including GPU acceleration, which is crucial for processing large NLP models. Colab also makes it easy to share and collaborate on projects.
Setting Up the Environment
To start, we need to install the necessary packages and set up our API keys. Follow these steps in your Google Colab environment:
Step 1: Install the required packages.
!pip install haystack-ai sentence-transformers transformers "huggingface_hub>=0.22.0"Step 2: Set up API keys for Hugging Face and OpenAI.
Getting a Hugging Face API Key:
Go to Hugging Face, sign up/login for a free account. Navigate to your account settings and generate your API key. Copy and paste it when the output of the below code asks for it.
Getting an OpenAI API Key:
Go to OpenAI, sign up/log in, and choose a subscription plan if you already don’t have a paid plan.
Get API Key: After subscribing, generate your API key from your account dashboard. Copy and paste it when the output of the below code asks for it.
import os
from getpass import getpass
if "HF_TOKEN" not in os.environ:
os.environ["HF_TOKEN"] = getpass("Enter Hugging Face API key:")
if "OPENAI_API_KEY" not in os.environ:
os.environ["OPENAI_API_KEY"] = getpass("Enter OpenAI API key:")Creating a Basic Haystack Pipeline
We’ll begin by creating a basic Haystack pipeline with an embedder and a writer component. This involves:
- Initialising the Pipeline and Document Store: Setting up the core components of the pipeline. Here, we initialise a Pipeline and an InMemoryDocumentStore, which will temporarily store our documents.
from haystack import Pipeline
from haystack.document_stores.in_memory import InMemoryDocumentStore
pipeline = Pipeline()
document_store = InMemoryDocumentStore()2. Adding Components to the Pipeline: Incorporating an embedder to process document embeddings and a writer to store these embeddings. We add an Embedder that uses SentenceTransformers to embed documents and a Writer to store these embeddings in the document store.
from haystack.components.embedders import SentenceTransformersDocumentEmbedder
from haystack.components.writers import DocumentWriter
pipeline.add_component("embedder", SentenceTransformersDocumentEmbedder())
pipeline.add_component("writer", DocumentWriter(document_store))3. Connecting the Components: Linking the embedder and writer to ensure proper data flow. We connect the embedder to the writer and display the pipeline structure to ensure everything is connected correctly.
pipeline.connect("embedder", "writer")
pipeline.show()4. Running the Pipeline with Sample Documents: Testing the pipeline with sample data to verify functionality. We run the pipeline with sample documents to embed and store them.
from haystack.dataclasses import Document
pipeline.run({"embedder": {"documents": [Document(content="Sushi is a traditional dish from Japan"),
Document(content="Tacos are popular in Mexico"),
Document(content="Pizza originated in Italy")]}})
pipeline.connect(“embedder”, “writer”)
pipeline.show()Building the RAG Pipeline
Next, we’ll construct a more advanced RAG pipeline. This involves:
- Initialising Components: Setting up components for embedding, retrieving, prompt building, and generating answers. We initialise an embedder for text, an in-memory retriever to find relevant documents, a prompt builder to construct the query prompt, and an OpenAI generator to generate the answer.
from haystack.components.embedders import SentenceTransformersTextEmbedder
from haystack.components.builders import PromptBuilder
from haystack.components.generators import OpenAIGenerator
from haystack.components.retrievers.in_memory import InMemoryEmbeddingRetriever
embedder = SentenceTransformersTextEmbedder()
retriever = InMemoryEmbeddingRetriever(document_store=document_store)2. Defining the Prompt Template: Creating a template that formats how the context and question are presented. The prompt template specifies how the context (retrieved documents) and the question should be formatted.
template = """Given the following context, answer the question.Context:
{% for document in documents %}{{ document.content }}{% endfor %}
Question: {{query}}"""
prompt_builder = PromptBuilder(template=template)
generator = OpenAIGenerator(model="gpt-4") 3. Creating the RAG Pipeline: Assembling all components into a cohesive pipeline and connecting them. We add all components to the RAG pipeline, connect them, and display the pipeline structure.
rag_pipeline = Pipeline()
rag_pipeline.add_component("embedder", embedder)
rag_pipeline.add_component("retriever", retriever)
rag_pipeline.add_component("prompt_builder", prompt_builder)
rag_pipeline.add_component("generator", generator)
rag_pipeline.connect("embedder", "retriever")
rag_pipeline.connect("retriever.documents", "prompt_builder.documents")
rag_pipeline.connect("prompt_builder", "generator")
rag_pipeline.show()4. Running the RAG Pipeline: Executing the pipeline with a sample question to generate an answer based on the retrieved documents.
question = "What is the traditional dish of Japan?"
rag_pipeline.run({"embedder": {"text": question},
"prompt_builder": {"query": question}})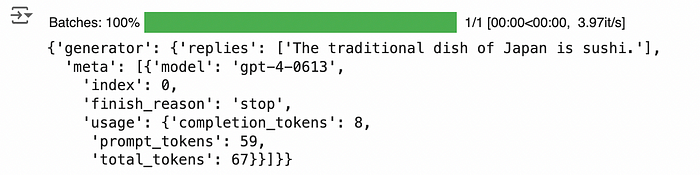
Putting It All Together
When you run the full pipeline with the question “What is the traditional dish of Japan?”, it embeds the query, retrieves relevant documents, constructs a prompt, and generates an answer using GPT-4.
Conclusion
In this article, we explored Haystack AI and how to create a RAG pipeline with it. We covered the installation of necessary packages, the creation of a pipeline, and the construction of a more advanced RAG pipeline. As you experiment further with different components and configurations, you’ll find Haystack AI to be an invaluable tool in developing cutting-edge, production-ready NLP solutions tailored to your specific requirements.
References
- deepset, “Creating Pipelines,” Haystack AI Documentation, [Online]. Available: https://docs.haystack.deepset.ai/docs/creating-pipelines. [Accessed: 22-Jul-2024].
Catch the latest version of this article over on Medium.com. Hit the button below to join our readers there.






















