


Beyond the Benchmark: A Hands-On Evaluation of Claude 3.7 Sonnet
Reasoning, Coding, and Conversation: Evaluating Claude’s Evolution as a Thinking Partner
-

- •

Introduction
In February 2025, Anthropic released Claude 3.7 Sonnet as their advanced reasoning model with a unique hybrid approach to AI assistance. Unlike previous models that offer a single mode of operation, Claude 3.7 introduces several key innovations worth evaluating:
- Dual Functionality: The ability to function as both a standard conversational AI and a dedicated reasoning engine when deeper thinking is required
- Extended Thinking Mode: A self-reflection capability that reportedly improves performance on complex tasks across mathematics, physics, coding, and instruction following
- API Control: For developers, granular control over the “thinking budget” up to 128K tokens, balancing depth and efficiency
- Real-World Application Focus: Design optimisations targeting practical business use cases rather than just benchmark performance
While these features sound promising in Anthropic’s official announcements, this blog post aims to evaluate their actual performance and practical value through systematic testing and direct comparisons.
My testing methodology focuses on three key areas that align with Claude 3.7’s claimed strengths:
- Step-by-step reasoning – Testing how effectively the model tackles problems requiring multi-stage thinking
- Natural conversational ability – Examining the qualitative aspects of dialogue flow and contextual understanding
- Tool use and artifact creation – Evaluating the model’s capabilities in generating and manipulating content
The following graph compares the performance of Claude Sonnet and OpenAI’s models across various benchmarks, including reasoning, coding, instruction following, and math problem-solving.
The results showcase each model’s strengths and weaknesses, with a particular focus on Claude 3.7 Sonnet’s capabilities in extended and non-extended thinking scenarios.
.jpg)
For each capability, I’ll share specific test prompts, example responses, and comparisons with other leading models where possible. Through this structured exploration, I’ll identify where Claude 3.7’s innovations deliver genuine value and where limitations still exist.
Testing the Reasoning Ability
In this section, we’ll evaluate Claude 3.7 Sonnet’s reasoning capabilities using a complex logical deduction problem. According to Anthropic’s benchmarks, Claude 3.7 achieves 78.2% accuracy in graduate-level reasoning tasks without extended thinking, and this improves to 84.8% with extended thinking enabled. Our goal is to verify these claims through direct testing.
The Test Case: The Logic Puzzle Challenge
I’ve designed a multi-constraint logical reasoning problem that requires systematic analysis and deductive reasoning.
Prompt:
A researcher is studying five different treatments (A, B, C, D, and E) for a disease. From previous studies, the following information is known:
1. If treatment A is effective, then treatment B is also effective.
2. Either treatment C is effective or treatment E is effective, but not both.
3. If treatment B is effective, then either treatment D or treatment E is effective, but not both.
4. If treatment D is effective, then treatment A is not effective.
5. Treatment C is effective. Based on these constraints, which treatments are effective and which are not? Please explain your reasoning step by step.Standard vs. Extended Thinking: A Revealing Comparison
I tested Claude 3.7 in both standard mode and with extended thinking enabled. The differences were noticeable and revealing:
In standard mode, Claude organised its response logically and reached a seemingly definite conclusion:
“The only consistent solution is:
A = false (not effective)
B = false (not effective)
C = true (effective)
D = true (effective)
E = false (not effective)”With extended thinking enabled, Claude demonstrated more thorough analysis:
“Definitely effective: Treatment C
Definitely not effective: Treatments A and E
Cannot be uniquely determined: Treatments B and D (though if B is effective, D must also be effective).”Analysis: Where Extended Thinking Makes a Difference
- Extended thinking response: Takes a step-by-step approach, working through the constraints methodically, focusing on definitive conclusions first.
- Non-extended thinking response: Uses a more formal logical notation (representing treatments as variables) and explores multiple possible scenarios.
The non-extended response incorrectly concludes that there’s a single solution with D being effective, when in fact D’s status cannot be uniquely determined when B is not effective.

This test confirms Anthropic’s benchmark claims that extended thinking significantly improves Claude 3.7’s logical reasoning capabilities. The extended thinking response provides a more reliable analysis of the logical problem by avoiding the premature conclusion found in the non-extended thinking response.
Real-World Implications
This capability difference has meaningful implications for practical applications:
- Legal and regulatory analysis: Extended thinking would be valuable for parsing complex legal stipulations with multiple interdependent clauses
- Policy decision making: When evaluating how different policy options interact, the ability to reach complete rather than partial conclusions is crucial
- Business scenario planning: For complex business decisions with multiple constraints, the thoroughness of extended thinking provides more reliable guidance
The extended thinking mode appears to genuinely enhance Claude 3.7’s ability to handle complex reasoning tasks that involve multiple interdependent variables – making it significantly more useful for real-world applications requiring careful logical analysis.
Testing Code Generation and Problem Solving
1. Advanced Visualisation Challenge: 4D Tesseract with Collision Detection
To push the boundaries of Claude 3.7’s coding capabilities, I presented it with a challenging visualisation task that combines advanced mathematics, physics simulation, and interactive graphics:
This task is particularly demanding because it requires:
- Understanding and implementing 4D geometry (tesseract/hypercube)
- Creating a projection from 4D to 3D space for visualisation
- Implementing rotation transformations in 4D
- Collision detection in 4D space
- Real-time animation and interactive graphics
Inside Claude’s Thinking Process

One of the most fascinating aspects of Claude 3.7 is the ability to see its thought process when extended thinking is enabled. Before generating code, Claude methodically broke down the problem:
Claude clearly identified five key components of the challenge:
- Representing a 4D tesseract in JavaScript
- Implementing rotation in 4D space
- Projecting the 4D object into 3D and then to 2D for display
- Simulating a ball bouncing within the constraints
- Detecting collisions between the ball and tesseract boundaries
This structured decomposition of the problem demonstrates Claude’s ability to plan a complex implementation before writing any code.
Claude 3.7 with Extended Thinking: Success on the First Attempt
The results were remarkable. With extended thinking enabled, Claude 3.7 Sonnet correctly implemented the entire visualisation in a single attempt. The code can be found here. Its solution included:
- Proper 4D geometry, mathematics, and projection
- An accurate collision detection algorithm
- Smooth animation of both tesseract rotation and ball movement
- Visual feedback for collisions as specified
- Clean, well-structured, and commented code

The implementation demonstrated Claude’s deep understanding of not just coding syntax, but complex mathematical concepts and their application in visualisation. The code was not only functional but also efficiently organised with appropriate abstractions.
GPT-4o: Struggling with 4D Concepts
For comparison, I presented the identical prompt to GPT-4o, which struggled significantly with the 4D aspects of the challenge. While it attempted to create a visualisation, its approach revealed several fundamental issues:
- Generated code that only displayed a black background
- Failed to properly implement the 4D geometry
- Did not correctly handle the projection from 4D to 3D space
This example perfectly illustrates how Claude 3.7’s extended thinking provides a significant advantage for complex technical implementations requiring deep conceptual understanding and careful planning.
Real-World Development
This performance gap has significant implications for developers working on advanced visualisation projects:
- Research Applications: Proper 4D visualisation is valuable in fields like theoretical physics and data science
- Educational Tools: Creating accurate visualisations of higher-dimensional concepts helps teach advanced mathematics
- Game Development: Complex physics simulations often require sophisticated mathematical modelling
Claude 3.7’s ability to accurately understand and implement advanced mathematical concepts in working code makes it a powerful assistant for developers working on cutting-edge visualisation projects.
2. Algorithm Challenge: Tackling a Hard LeetCode Problem
To test Claude 3.7’s capabilities with complex algorithms, I presented it with LeetCode problem “Maximum Value Sum by Placing Three Rooks I,” a challenging optimization problem that requires sophisticated algorithmic thinking.
Prompt:You are given a m x n 2D array board representing a chessboard, where board[i][j] represents the value of the cell (i, j). Rooks in the same row or column attack each other. You need to place three rooks on the chessboard such that the rooks do not attack each other. Return the maximum sum of the cell values on which the rooks are placed.Claude 3.7’s Performance
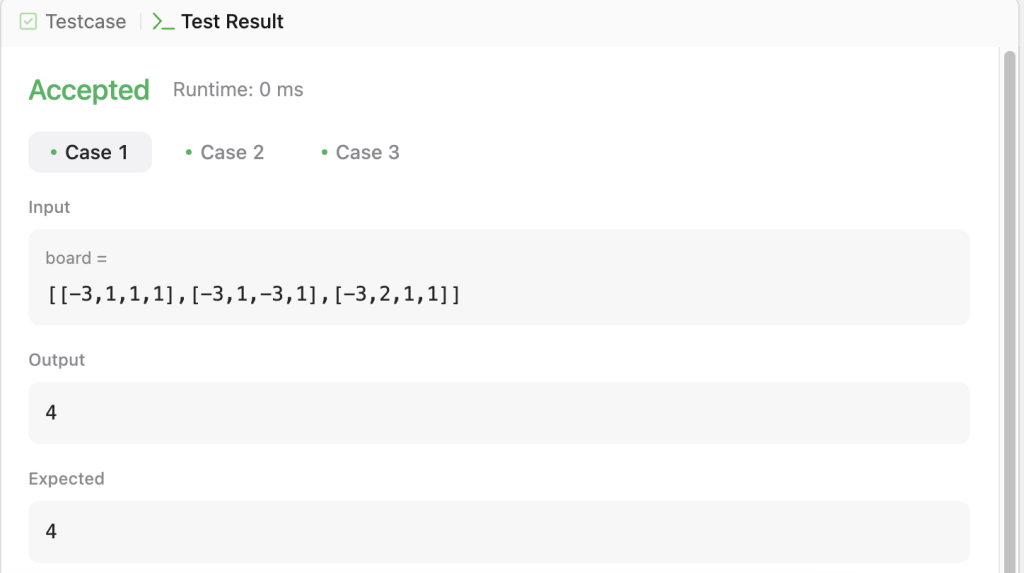
Claude’s approach to this problem was impressive. While its first attempt contained a minor implementation error (a NameError: global name 'Solution' is not defined), it quickly corrected this issue on the second attempt and produced a working solution that correctly implemented the algorithm to find the maximum value sum, handled the constraints effectively (no two rooks in the same row/column), and passed all test cases with the correct output.
The screenshot shows successful execution against a test case with a 3×4 matrix, correctly returning the maximum possible value of 4.
Claude’s solution demonstrated strong algorithmic thinking:
- Approach Selection: It correctly identified that this is a maximum weight bipartite matching problem
- Optimisation: It implemented an efficient solution rather than brute force
- Error Recovery: It quickly identified and fixed its own implementation error
- Edge Case Handling: The solution correctly handled various matrix sizes
What’s particularly notable is Claude’s self-correction capability. When presented with the error in its first solution, it quickly diagnosed the issue and modified its code appropriately without needing specific guidance on what went wrong.
Real-World Implications
This performance demonstrates Claude 3.7’s potential value for software developers working on:
- Algorithm optimisation problems
- Competitive programming challenges
- Technical interview preparation
- Complex data structure implementations
The ability to not only solve hard algorithmic problems but also debug and refine solutions makes Claude 3.7 a potentially powerful assistant for developers tackling complex coding challenges.
Testing Instruction Following and Natural Conversation
For our final set of tests, I wanted to evaluate how well Claude 3.7 Sonnet handles complex instructions and maintains natural conversational flow. According to Anthropic’s benchmarks, Claude 3.7 achieves an impressive 93.2% accuracy in instruction-following tasks, placing it among the top-performing models in this category.
Multi-Part Instruction Test
To assess Claude 3.7’s ability to follow detailed instructions, I designed a challenging multi-part task that required careful attention to several different requirements simultaneously:
Prompt:
This prompt tests the model’s ability to handle multiple constraints, organise information in different requested formats, creative problem-solving within limits and follow specific formatting instructions.


Claude 3.7’s response was impressively comprehensive, addressing all constraints simultaneously. The menu successfully incorporated Mediterranean dishes while accommodating dietary restrictions, and each requested element was clearly organised.
Extended Dialogue: Testing Conversational Depth and Naturalness
To evaluate conversational abilities more thoroughly, I engaged Claude 3.7 in an extended dialogue about the cultural history of Mediterranean cuisine, then gradually introduced personal preferences and hypothetical scenarios. I also shifted between related subtopics while referencing earlier points. Introduced ambiguous pronouns that require understanding the previous context.
Notable Conversational Strengths
The dialogue revealed several impressive capabilities:
Contextual Memory: Claude maintained perfect recall of specific ingredients and regional distinctions mentioned earlier in our 15-message exchange, referencing them appropriately when relevant.
Natural Topic Transitions: When discussing the evolution of Mediterranean cuisine, Claude smoothly transitioned between historical periods, cultural influences, and modern adaptations without abrupt shifts or repetition.
Balanced Initiative: Claude demonstrated a good balance between answering questions and introducing relevant new aspects of the topic, creating a genuinely interactive conversation rather than just responding reactively.



This test demonstrated Claude’s ability to shift conversational tone appropriately based on context cues, moving between informative, collaborative, and reflective modes as the conversation evolved.
Strengths and Practical Applications
Throughout our testing of Claude 3.7 Sonnet, several clear strengths emerged. Understanding them is essential for effectively leveraging this model in real-world applications.
Key Strengths of Claude 3.7 from the testing:
- Complex Reasoning Tasks
- Excels in multi-step logical problems
- Extended thinking mode provides significant improvements for problems requiring systematic analysis
- Advanced Technical Implementation
- Impressive capabilities with mathematical visualisations and algorithms
- Strong code generation with sophisticated concepts
- Self-correction abilities when implementations have minor issues
- Comprehensive Instruction Following
- Consistently addresses all components of multi-part requests
- Delivers information in requested formats with high reliability
- Natural Conversation
- Maintains context across extended exchanges
- Balances information delivery with conversational engagement
Practical Applications
Based on our testing, Claude 3.7 Sonnet appears particularly well-suited for:
- Software Development Assistance Claude 3.7 excels at algorithm implementation and optimisation, especially for complex problems requiring systematic thinking. Its ability to debug and improve existing code is particularly valuable when tackling sophisticated technical issues.
- Complex Research Support Researchers can leverage Claude 3.7 for synthesising and summarising literature across disciplines, condensing large volumes of information into coherent analyses. The model shows a remarkable ability in exploring the logical implications of research findings through extended thinking, identifying potential consequences that might not be immediately apparent.
- Content Development with Constraints Content creators working under specific requirements will appreciate Claude’s ability to develop material that adheres to multiple constraints simultaneously while maintaining coherence and quality. This proves especially valuable when creating comprehensive plans and structured information that must balance creativity with specific guidelines.
Catch the latest version of this article over on Medium.com. Hit the button below to join our readers there.





















