


Breaking the Transformer Monopoly: Liquid Foundation Models Redefine SOTA
How Non-GPT Architectures Are Surpassing Leading Transformer-Based Large Language Models
-

- •

Introduction
In the era of large models, the Transformer architecture, introduced in Google’s groundbreaking 2017 paper “Attention Is All You Need,” has become the mainstream.
However, Liquid AI, a startup founded by former researchers from MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL), is taking a different path.
Liquid AI aims to “explore methods to surpass the foundational models of Generative Pre-trained Transformers (GPT).”
To achieve this goal, Liquid AI has launched its first batch of multimodal AI models: Liquid Foundation Models (LFM). These are next-generation generative AI models built from first principles, with their 1B, 3B, and 40B LFMs achieving SOTA performance across various scales while maintaining smaller memory footprints and more efficient inference.
Maxime Labonne, Head of Training at Liquid AI, expressed on X that LFM is the proudest release of his career, highlighting that the core advantage of LFMs is their ability to outperform Transformer-based models while using less memory.
Some claim that LFMs are the “end of Transformers,” with others praising them as game-changers. There are even suggestions that “it might be time to move on from Transformers, as this new architecture looks promising.”
You can now experience LFM models for free:
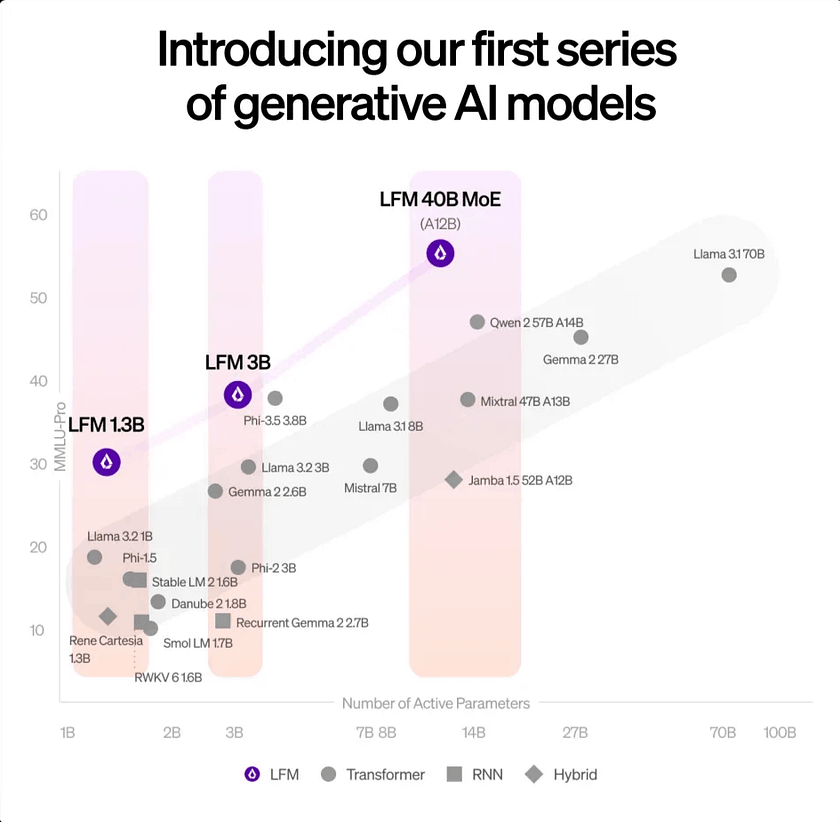
Liquid AI Releases Three Models
The LFM series comes in three different sizes and variants:
- Dense LFM 1.3B (smallest), ideal for highly resource-constrained environments.
- Dense LFM 3B, optimised for edge deployment.
- LFM 40.3B MoE model (largest, similar to Mistral’s mixture of experts model), designed for handling more complex tasks.
SOTA Performance
LFM-1B outperforms models of similar size. In various benchmarks, LFM-1B scores the highest, making it the most advanced model at its scale. This marks the first significant outperformance of a Transformer-based model by a non-GPT architecture. For instance, LFM 1.3B surpasses Meta’s Llama 3.2–1.2B and Microsoft’s Phi-1.5 in third-party benchmarks.
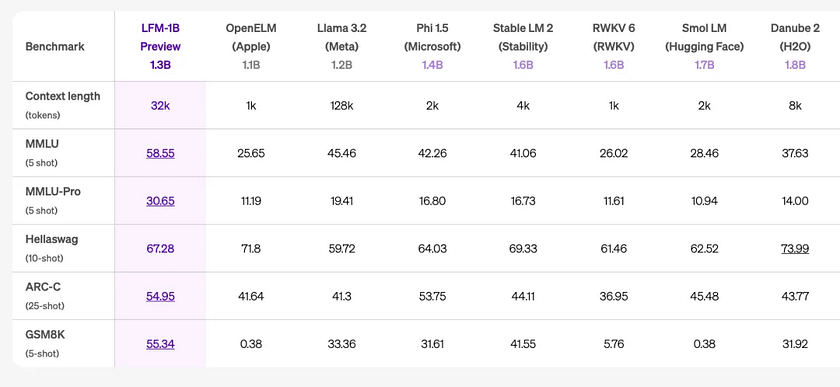
LFM-3B achieves incredible performance, ranking first when compared to 3B Transformer models, hybrid models, and RNN models. It also matches the performance of Phi-3.5-mini in several benchmarks while being 18.4% smaller. This makes LFM-3B an ideal choice for mobile and other edge text applications.

LFM-40B strikes a new balance between model size and output quality. It can activate 12B parameters at runtime, delivering performance comparable to larger models. The MoE architecture enables higher throughput and allows deployment on more cost-effective hardware.
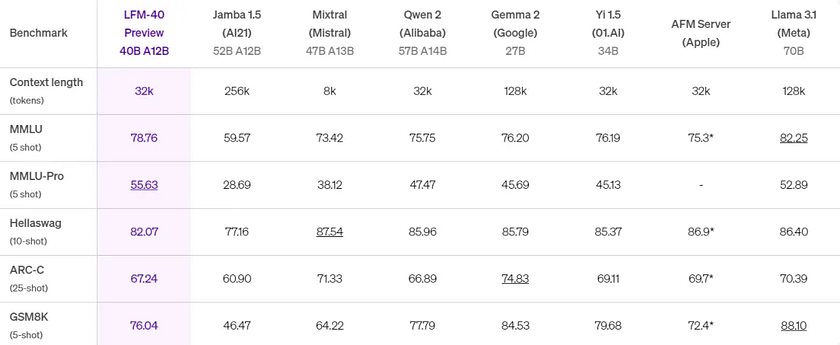
Memory Efficiency
Compared to Transformer architectures, LFMs use less memory, especially for long inputs, as the KV cache in Transformer-based LLMs grows linearly with sequence length. By efficiently compressing inputs, LFMs can handle longer sequences on the same hardware. Among 3B-class models, LFMs require the least amount of memory. For instance, LFM-3B requires only 16 GB of memory, whereas Meta’s Llama-3.2–3B requires over 48 GB.
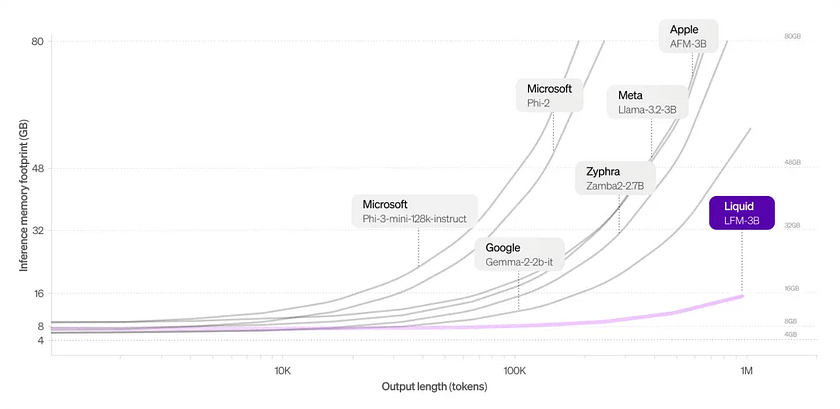
The LFM-3B model outperforms Google’s Gemma-2, Microsoft’s Phi-3, and Meta’s Llama-3.2 in inference memory utilisation, especially as token length increases.
LFM Truly Utilises Context Length
One of the standout features of LFM is its efficient memory usage. Compared to Transformer architectures, LFMs use less memory, particularly for long inputs, where the KV cache in Transformer-based LLMs grows linearly with sequence length.
In the preview version, the team optimised the model to provide a top-tier 32k token context length, directly surpassing the efficiency boundaries at this scale. Subsequent RULER benchmarks confirmed this achievement.
The table below compares the performance of several models at different context lengths.
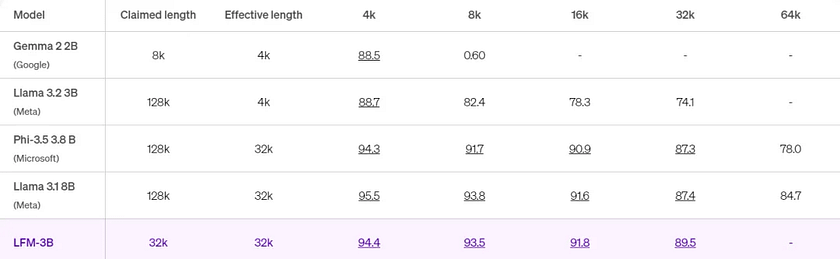
A context length is considered “effective” when it scores above 85.6 points.
Clearly, LFM has advanced the Pareto frontier(a concept in optimisation that states that a set of points where no single point can be improved on one objective without worsening another objective) of large-scale AI models through new algorithmic developments designed by the Liquid AI team. These algorithms enhance the model’s knowledge capacity, multi-step reasoning capabilities, and contextual memory, while also enabling efficient training and inference.
Liquid AI has laid the foundation for a new design space of computational units, allowing for customisation based on different model and hardware requirements.
This efficient context window enables long-context tasks on edge devices for the first time. For developers, it unlocks new applications such as document analysis and summarisation, more meaningful interactions with context-aware chatbots, and improved Retrieval-Augmented Generation (RAG) performance.
These models are competitive not only in raw performance benchmarks but also in operational efficiency, making them ideal for a variety of use cases, from enterprise-level applications in financial services, biotechnology, and consumer electronics to deployments on edge devices.
Users can access them through platforms like Lambda Chat or Perplexity AI.
However, the team acknowledges that LFMs have several areas where they are less proficient:
- Zero-shot learning for coding tasks
- Precise numerical computations
- Up-to-date information
- Counting occurrences of “r” in “Strawberry”
Additionally, human preference optimisation methods have not been widely applied to LFM models yet.
Currently, LFMs excel in areas such as:
- General and specialised knowledge
- Mathematical and logical reasoning
- Efficient and effective long-context tasks
- Primarily English, with support for Spanish, French, German, Chinese, Arabic, Japanese, and Korean
How Liquid Surpasses Generative Pre-trained Transformers (GPT)
Liquid employs a hybrid computational unit deeply rooted in the theories of dynamical systems, signal processing, and numerical linear algebra. The result is the development of a general-purpose AI model capable of modelling any type of sequential data, including video, audio, text, time series, and signals, to train their new LFM.
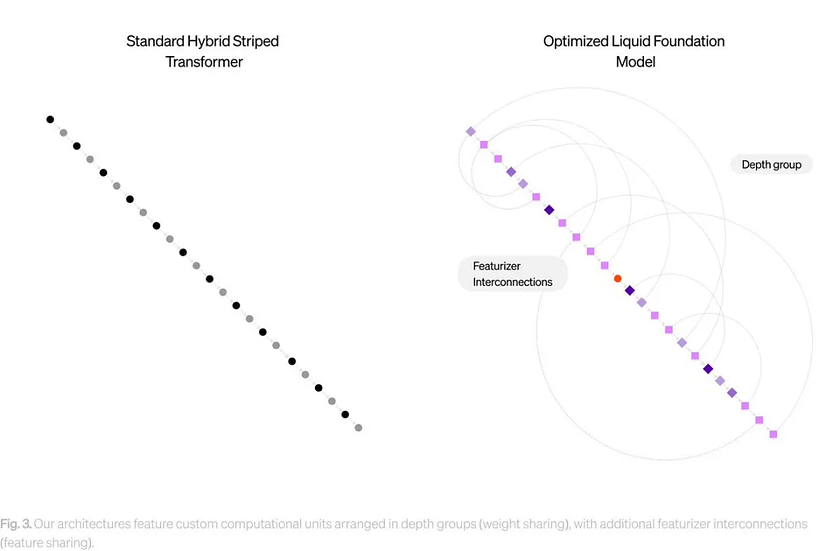
As early as last year, Liquid AI used a method called Liquid Neural Networks (LNN). Unlike traditional deep learning models that require thousands of neurons to perform complex tasks, LNN demonstrated that fewer neurons, combined with innovative mathematical formulations, can achieve the same results.
Liquid AI’s new models retain this core advantage of adaptability, allowing real-time adjustments during inference without the computational overhead associated with traditional models. They can efficiently handle up to 1 million tokens while minimising memory usage.
For example, in terms of inference memory usage, the LFM-3B model outperforms popular models like Google’s Gemma-2, Microsoft’s Phi-3, and Meta’s Llama-3.2, especially as token length increases.

While other models experience a sharp increase in memory usage when handling long contexts, the LFM-3B occupies significantly less space, making it ideal for applications requiring extensive sequential data processing, such as document analysis or chatbots.
Liquid AI has built its foundational model as a general-purpose model across multiple data modalities, including audio, video, and text.
With this multimodal capability, Liquid aims to address various industry-specific challenges, from financial services to biotechnology and consumer electronics.
Liquid AI is optimising its models for products from several hardware manufacturers, including NVIDIA, AMD, Apple, Qualcomm, and Cerebras.
Liquid AI is inviting early users and developers to test their new models and provide feedback. Although the models are not yet perfect, the company plans to use this feedback to make improvements. They will hold an official launch event at MIT on October 23, 2024.
To maintain transparency and drive scientific progress, the company plans to publish a series of technical blog posts before the launch. They also encourage users to engage in red teaming to explore the model’s limits and help improve future versions.
The LFM introduced by Liquid AI combines high performance with efficient memory usage, offering a compelling alternative to traditional Transformer-based models. This positions Liquid AI as a potential major player in the foundational model space.
Understanding the Principles of Liquid Neural Networks
Liquid Neural Networks (LNN) is a novel architecture proposed by the team, which makes artificial “neurons” or nodes used for data transformation more efficient and adaptive. Unlike traditional deep learning models that require thousands of neurons to perform complex tasks, LNN achieves the same results with fewer neurons by combining innovative mathematical formulations.
Liquid Time-constant Networks
Interestingly, Daniela Rus, the director of MIT CSAIL, mentioned that the inspiration for Liquid Neural Networks originated from the neural structure of nematodes.
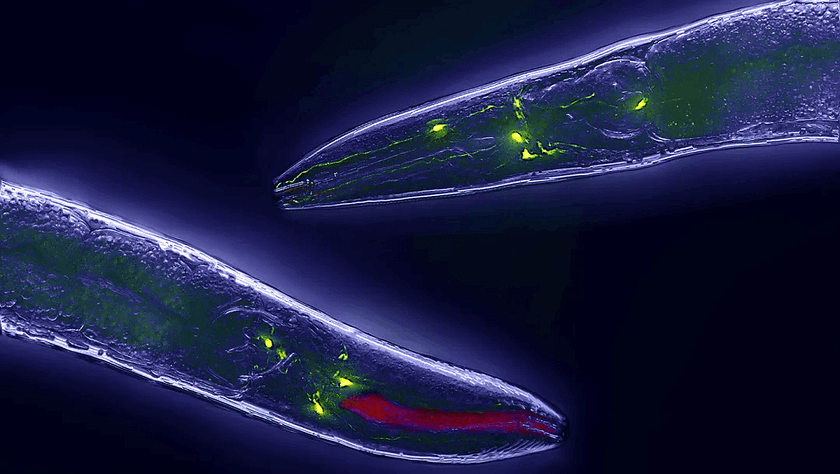
Caenorhabditis elegans is also the only organism for which the connectome has been fully mapped (as of 2019). Despite its simple brain, it surpasses any current AI system in learning and adapting to its environment.
Caenorhabditis elegans measures just 1 millimetre in length and possesses only 302 neurons and 96 muscles, yet it exhibits complex intelligent behaviours such as sensing, escaping, foraging, and mating.
It is the simplest intelligent life form and serves as the smallest model for achieving general artificial intelligence through simulations of biological neural mechanisms.
In recent years, researchers have been leveraging findings from nematode neural studies for computational biomimicry. By studying how the nematode brain functions, Daniela Rus and her team designed a “Liquid Time-constant Network”:
A continuous-time model composed of multiple simple dynamical systems that regulate each other through nonlinear gates.
If standard neural networks are like layers of evenly spaced dams, each equipped with many valves (weights), through which computational flow must pass and collect before moving to the next layer, then Liquid Neural Networks eliminate the need for dams, as each neuron is controlled by differential equations (ODEs).
These networks feature variable time constants, with outputs derived by solving differential equations. Studies have shown that they outperform traditional models in terms of stability, expressive power, and time-series prediction.
Subsequently, Daniela Rus and her team proposed an approximation method using closed-form solutions to efficiently simulate interactions between neurons and synapses (Closed-form continuous-time neural networks). This not only significantly improved computing speed but also demonstrated better scalability, excelling in time-series modelling and surpassing many advanced recurrent neural network models.
The Liquid AI team has claimed that this architecture is suitable for analysing any phenomena that fluctuate over time, including video processing, autonomous driving, brain and heart monitoring, financial transactions (stock quotes), and weather forecasting.
Besides their fluid-like flexibility, Liquid Neural Networks are much smaller in scale compared to generative AI models with billions of parameters.
For example, the LFM 1.3B, which can be deployed in highly resource-constrained environments, has only 1.3 billion parameters (similar to the largest version of GPT-2 at 1.5 billion), while maintaining lower memory usage and more efficient inference, allowing it to run on various robotic hardware platforms.
Additionally, due to their small size and simple architecture, Liquid Neural Networks offer advantages in interpretability.
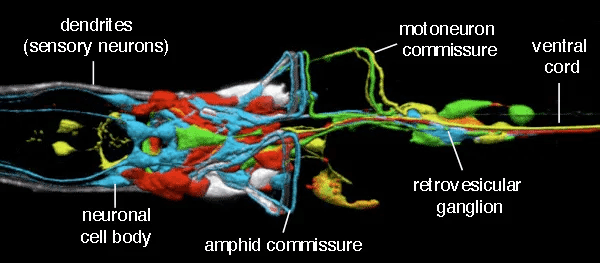
As a brain-inspired system, Liquid Neural Networks (LNN) retain adaptability and robustness to change even after training.

Through theoretical analysis and experimentation, the team demonstrated that this system:
- Is a universal approximator.
- Is a powerful continuous-time machine learning system for handling sequential data.
- Has extremely high parameter efficiency in learning new skills.
- Exhibits causality and interpretability.
- When linearised, can efficiently model ultra-long-term dependencies in sequential data.

The team developed a class of nonlinear neural differential equation sequence models and extended them to graph structures.
They also expanded and optimised continuous-time models using hybrid numerical methods and time-parallel schemes, achieving SOTA performance in control and prediction tasks.
Additionally, they released one of the most comprehensive open-source libraries for neural differential equations, which is widely used in various applications for diffusion-based generative modelling and prediction tasks.

Notably, the team introduced the first efficient parallel-scan-based linear state space architecture and a SOTA time series state space model based on rational functions.
Additionally, they were the first to propose a generative state space architecture for time series and a state space architecture suitable for video processing.

The team introduced a new neural operator framework that outperformed various methods, including Fourier neural operators, in solving differential equations and prediction tasks.

The team co-invented a series of deep signal processing architectures capable of effectively extending to long contexts, such as Hyena, HyenaDNA, and StripedHyena.
Among them, Evo, based on StripedHyena, is an innovative foundational model for DNA. It not only generalises across DNA, RNA, and proteins but also enables the design of new CRISPR systems.
Notably, they are the first team to extend language models using deep signal processing and state space layers.
They conducted the most extensive analysis to date of scaling laws for models surpassing the Transformer architecture and proposed new model variants that outperform existing open-source alternatives.

The team spearheaded the development of many leading open-source LLM fine-tuning and merging techniques.
Finally, the team’s research made significant contributions across multiple fields: pioneering work in graph neural networks and geometric deep learning models; defining new metrics for the interpretability of neural networks; and developing SOTA dataset distillation algorithms.

In fact, there are dozens of related research papers available. For those interested, more information can be found on the official blog.

Blog: https://www.liquid.ai/blog/liquid-neural-networks-research
A New Model Architecture
Building on previous research, the team developed a novel foundational model design space focused on different modalities and hardware requirements.
The goal is clear — explore methods to build foundational models that surpass generative pre-trained Transformers (GPT).
Through LFM, the team has put new principles and methods developed over the past months into practice to guide model design:
1. LFM Consists of Structured Operational Units
The model is constructed from a set of computational units, forming the basic components of these architectures within a new design space.
The Liquid system and its components maximise knowledge capacity and reasoning ability while achieving higher training efficiency, reducing memory consumption during inference, and enhancing modelling performance across video, audio, text, time series, and signal data.
2. LFM Architecture is Controllable
The design of the model informs strategies for scaling, inference, alignment, and model analysis.
By applying classical signal processing analysis methods, the team can deeply analyse the dynamic characteristics of LFM and thoroughly explore its behavioural features, including model outputs and internal mechanisms.
3. LFM is Adaptively Capable of Serving as a Foundation for AI of Various Scales
The model architecture can be automatically optimised to fit specific hardware platforms (such as Apple, Qualcomm, Cerebras, and AMD) or to meet specific parameter requirements and inference cache size constraints.
A New Design Space
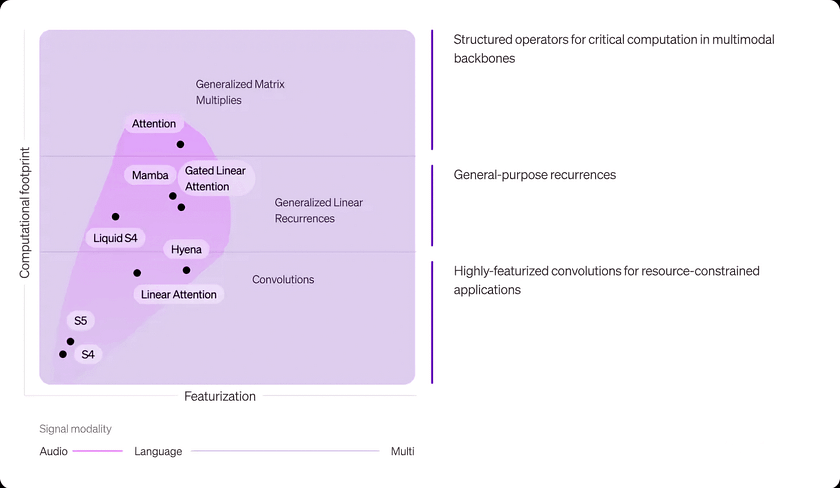
Specifically, the Liquid design space is primarily defined by two dimensions: characterisation of the architecture and its core operators, and computational complexity.
- Characterisation refers to the process of transforming input data (such as text, audio, images, and video) into a structured set of features or vectors. These features or vectors are used to adaptively modulate the model’s internal computational processes. For example, compared to language and multi-modal data, audio and time series data typically require less characterisation processing in operators due to their lower information density.
- Another key dimension is the computational complexity of the operators, which refers to the computational resources required to complete operations. By exploring and refining the design space of structured adaptive operators, the team can maximise model performance while controlling computational demands.
At its core, LFM is constructed from a series of computational units. These units can be represented as adaptive linear operators, whose behaviour is dynamically determined by the input data.
The LFM design framework unifies and encompasses a wide range of computational units found in deep learning, providing a methodological foundation for systematically exploring model architecture space.
Specifically, model construction can be guided by improving the following three key aspects:
- Token Mixing Structure: How the operator mixes embeddings in the input sequence
- Channel Mixing Structure: How the channel dimensions are mixed
- Characterisation: Responsible for adjusting computation based on the input context
Advancing the Pareto Frontier of Large-Scale AI Models
To achieve these groundbreaking results, the team optimised the entire process from pre-training preparation to post-training processing, while also upgrading the relevant computing hardware and software systems.
1. Knowledge Reserve
At any given model scale, it can exhibit broad and deep information processing capabilities across various fields and tasks.
Through improved model architecture and the adoption of new pre-training, in-training optimisation, and post-training strategies, LFM is able to compete with larger models on tasks that require a rich knowledge reserve.
2. Multi-Step Reasoning
This capability refers to the skill of breaking down complex problems and applying rigorous logical thinking.
By distilling and optimising system 2 tasks at critical stages of training, the team endowed the model with more advanced cognitive functions and strong analytical abilities, even with limited computational resources and compact model architecture.
3. Long Context Recall
It is important to note that a model’s maximum input size is not the same as its effective context length.
The team specifically trained large language models to maximise their memory and information retrieval capabilities, as well as their ability to learn and reason based on context across all possible input length ranges.
4. Inference Efficiency
Memory usage in transformer-based models increases sharply when processing long inputs, making them unsuitable for deployment on resource-constrained edge devices.
In contrast, LFM features nearly constant inference time and memory complexity. This means that even as the input context length increases, it does not significantly affect text generation speed or increase the required memory amount.
5. Training Efficiency
Training GPT-like foundational models requires significant computational resources. However, LFM is more efficient when training on long-context data.
Introduction to the Liquid AI Team
This startup, publicly competing with OpenAI and other large language model companies, was incubated by MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL) and founded in March 2023.
In December 2023, the company secured $37.5 million in seed funding, reaching a valuation of $300 million.
Investors include GitHub co-founder Tom Preston-Werner, Shopify co-founder Tobias Lütke, and Red Hat co-founder Bob Young, among others.
MIT CSAIL Director Daniela Rus, a renowned roboticist and computer scientist, and the first female director of the lab, is one of the company’s founders.
In addition to Daniela Rus, the other three co-founders of Liquid AI were postdoctoral researchers at MIT CSAIL.
Co-founder and CEO Ramin Hasani was a chief AI scientist at Vanguard, one of the largest fund management companies in the US, before conducting postdoctoral research at MIT CSAIL.
Co-founder and CTO Mathias Lechner collaborated with Hasani on research about the neural structure of nematodes during his studies at TU Vienna.
Co-founder and Chief Scientist Alexander Amini was previously a doctoral student under Daniela Rus.
In 2017, Daniela Rus recruited Hasani and Lechner to MIT CSAIL, and Rus, along with her doctoral student Amini, also joined the research on liquid neural networks.

Liquid: Creating Best-in-Class Systems at Every Scale
According to Liquid AI’s official blog, the first-generation Liquid Foundational Model (LFM) is a new generation of generative AI models built from fundamental principles. Our mission is to create best-in-class, intelligent, and efficient systems at every scale — systems designed to handle large amounts of sequential multi-modal data, achieve advanced reasoning, and make reliable decisions.
The unique fusion of LFM’s computational units with dynamical systems theory, signal processing, and numerical linear algebra allows us to leverage decades of theoretical advancements in these fields as we pursue intelligence at every scale. The name “Liquid” reflects the company’s roots in the field of dynamic and adaptive learning systems.
Daniela Rus points out that generative AI has significant limitations in terms of safety, interpretability, and computational power, making it difficult to apply to robotics problems, especially in mobile robotics.
Inspired by the neural structure of the research community’s “frequent subject,” the nematode C. elegans, Daniela Rus and her postdoctoral researchers developed a new type of flexible neural network, known as liquid neural networks.
Conclusion
In conclusion, Liquid AI’s innovative Liquid Foundation Models (LFM) represent a significant leap beyond traditional Transformer-based architectures like GPT. By focusing on efficiency, memory utilisation, and multimodal capabilities, LFM models offer a compelling alternative for handling large-scale AI tasks across various domains. Their ability to process long contexts, operate with reduced computational resources and maintain high-performance positions Liquid AI as a pioneering force in the AI landscape. With a foundation in liquid neural networks, Liquid AI continues to push the boundaries of model scalability and efficiency, aiming to redefine the future of AI.
References
- Liquid.ai. (2024). From Liquid Neural Networks to Liquid Foundation Models | Liquid AI. https://www.liquid.ai/blog/liquid-neural-networks-research
- X (formerly Twitter). (2025c). https://x.com/maximelabonne/status/1840770427292958749.
- X (formerly Twitter). (2025d). https://x.com/LiquidAI_/status/1840768716784697688.
- Staff, V. (2024). The tireless teammate: How agentic AI is reshaping development teams. https://venturebeat.com/ai/the-tireless-teammate-how-agentic-ai-is-reshaping-development-teams/.
Catch the latest version of this article over on Medium.com. Hit the button below to join our readers there.






















