


Exploring Aya Vision: Cohere's Multimodal Model and Its Comparison with GPT
-

- •

Introduction
Vision-enabled AI models have rapidly evolved to become essential tools across numerous applications, from content moderation to image analysis and multimodal reasoning. Cohere's recent entry into this space with their Aya Vision model promises to deliver competitive capabilities in the increasingly crowded market of multimodal AI systems.
In this blog post, I'll share my hands-on experience testing Aya Vision (32B model) against GPT-4o, focusing on several key areas critical for real-world applications. Rather than relying on marketing claims or theoretical specifications, this analysis is based on direct testing with identical prompts and images across both models.
What is Aya Vision?
Aya Vision, part of Cohere’s Aya family, aims to make generative AI accessible across languages and modalities. It’s available in two sizes—8 billion parameters (Aya Vision 8B) and 32 billion parameters (Aya Vision 32B)—and is optimised for vision-language tasks. As an open-weight model, it’s freely accessible for non-commercial research via platforms like Hugging Face and Kaggle. You can also access it using their Playground platform. Supporting 23 languages and covering half the world’s population, Aya Vision is designed for tasks like image captioning, visual question answering, text generation, and translation, making it a versatile tool for global applications.
Testing Methodology
My testing approach involved challenging both models with identical images and prompts across several categories:
- Technical Code Analysis: Evaluating how well each model can interpret and explain programming code in images
- Basic Image Recognition: Testing fundamental object identification capabilities
- Visual Reasoning: Assessing the ability to make accurate inferences about visual information
- OCR and Text Interpretation: Examining how effectively the models can read and understand text in images
- Object Counting: Testing precision in counting and identifying multiple objects
- Multilingual Capabilities: Assessing ability to recognise and translate non-English text
Test Results
1. Technical Code Analysis: Flutter Code Snippet
The Challenge: Both models were presented with a Flutter (Dart) code snippet and asked to analyse it.
Prompt: Analyse the code snippet shown in this image.
Image used:
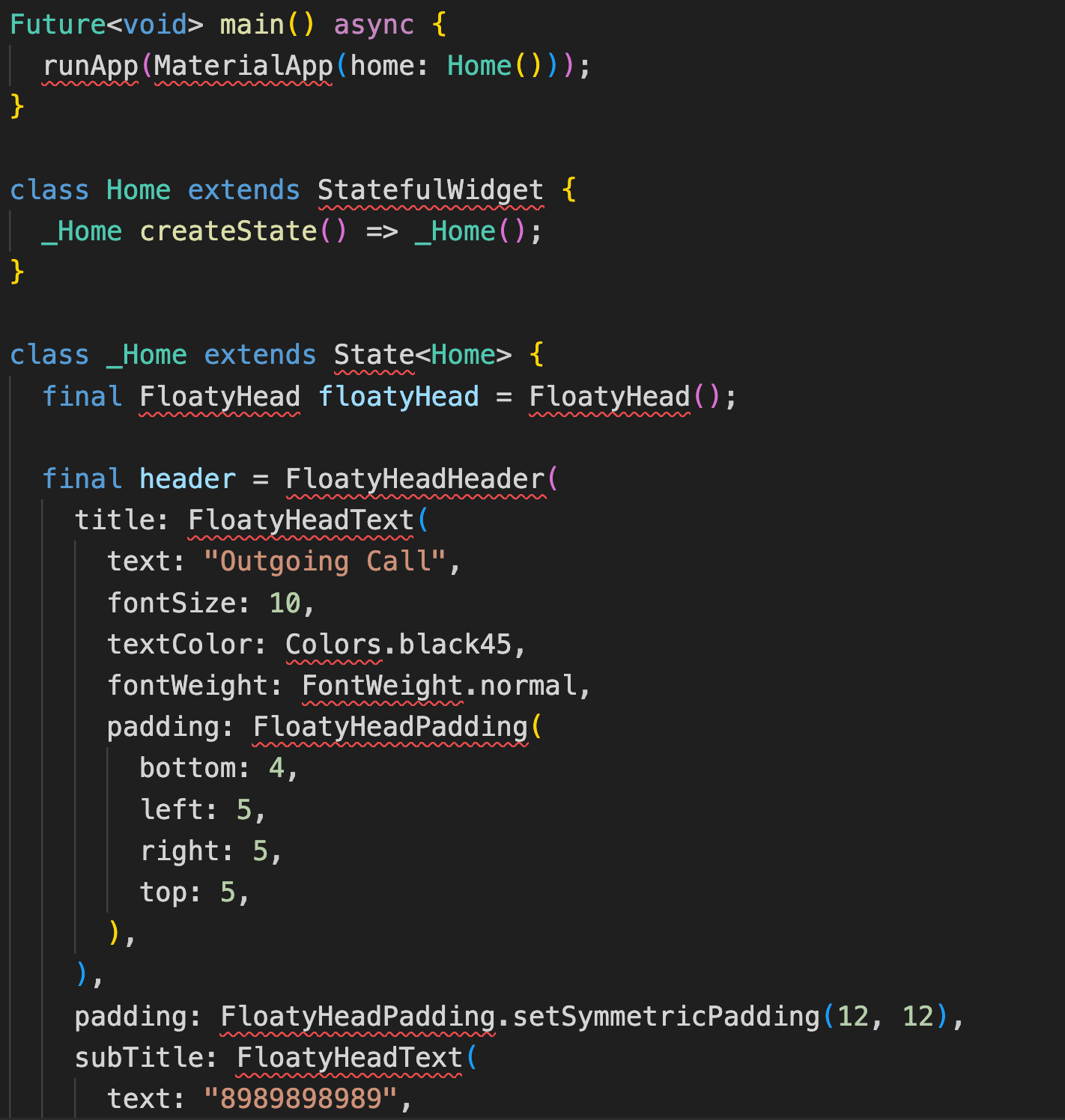
GPT-4V's Response:
- ✅ Correctly identified the language as Dart/Flutter
- ✅ Accurately recognised key components (FloatyHead, MaterialApp, StatefulWidget)
- ✅ Correctly inferred the likely purpose (floating window/outgoing call notification)
- ✅ Noted the red squiggly lines indicating possible errors
- ✅ Provided practical suggestions for fixing the code
- ✅ Used a well-structured, developer-friendly format
Aya Vision's Response:

- ❌ Incorrectly identified the language as TypeScript
- ❌ Misinterpreted Flutter-specific components as React/Angular
- ❌ Created fictitious explanations about non-existent components (e.g., "sync" function)
- ❌ Mentioned JSX-like syntax which isn't present in the actual code
- ❌ Made up components that don't exist in the code ("PaddedText", "View")
- ❌ Exhibited significant hallucination, inventing content not present in the image
Analysis: In this test, GPT-4V demonstrated significantly superior technical understanding and accuracy. Aya Vision's response included substantial hallucinations, raising serious concerns about its reliability for technical use cases.
2. Basic Image Recognition: Eyeglasses
The Challenge: Both models were shown an image of transparent eyeglasses on a white surface and asked to describe what they saw.
Prompt: Describe what you see in this image
Image used:

GPT-4V's Response:

- ✅ Correctly identified eyeglasses
- ✅ Noted the translucent/light-colored frame
- ✅ Described the retro, oversized design
- ✅ Mentioned metallic elements on the temples
- ✅ Kept the description accurate and concise
Aya Vision's Response:
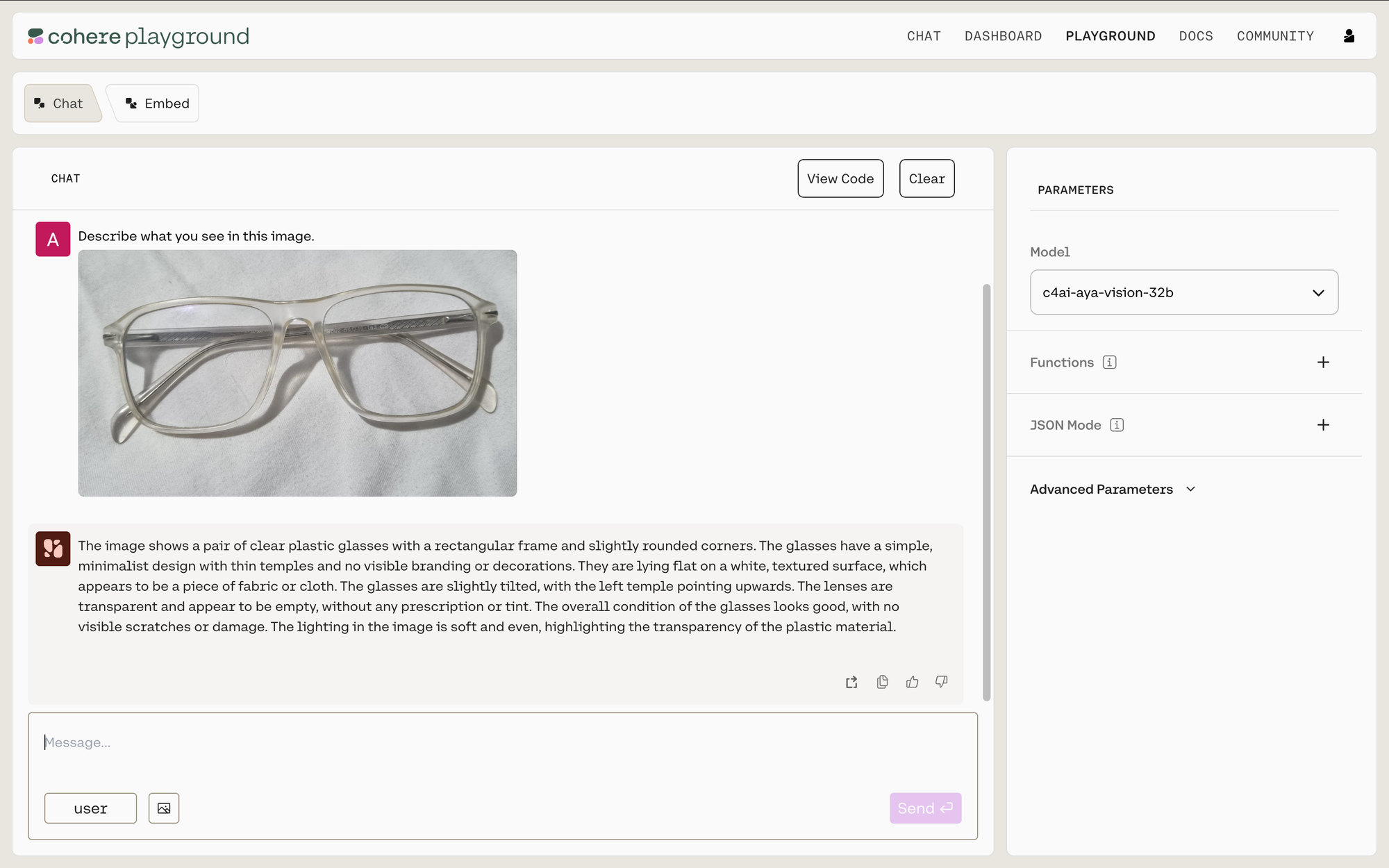
- ✅ Correctly identified clear plastic glasses
- ✅ Described the rectangular frame with rounded corners
- ✅ Noted the minimalist design
- ✅ Mentioned the white, textured surface underneath
- ✅ Provided accurate details about the glasses' condition
Analysis: Both models performed well on this basic image recognition task, with similarly accurate descriptions. This suggests that for straightforward object identification, both models have comparable capabilities.
3. Visual Reasoning: Food Identification
The Challenge: Both models were shown an image of "mushroom buns" in a bamboo steamer basket and asked to identify the dish.
Prompt: Can you guess what dish is in the image?
Image used:

GPT-4V's Response:
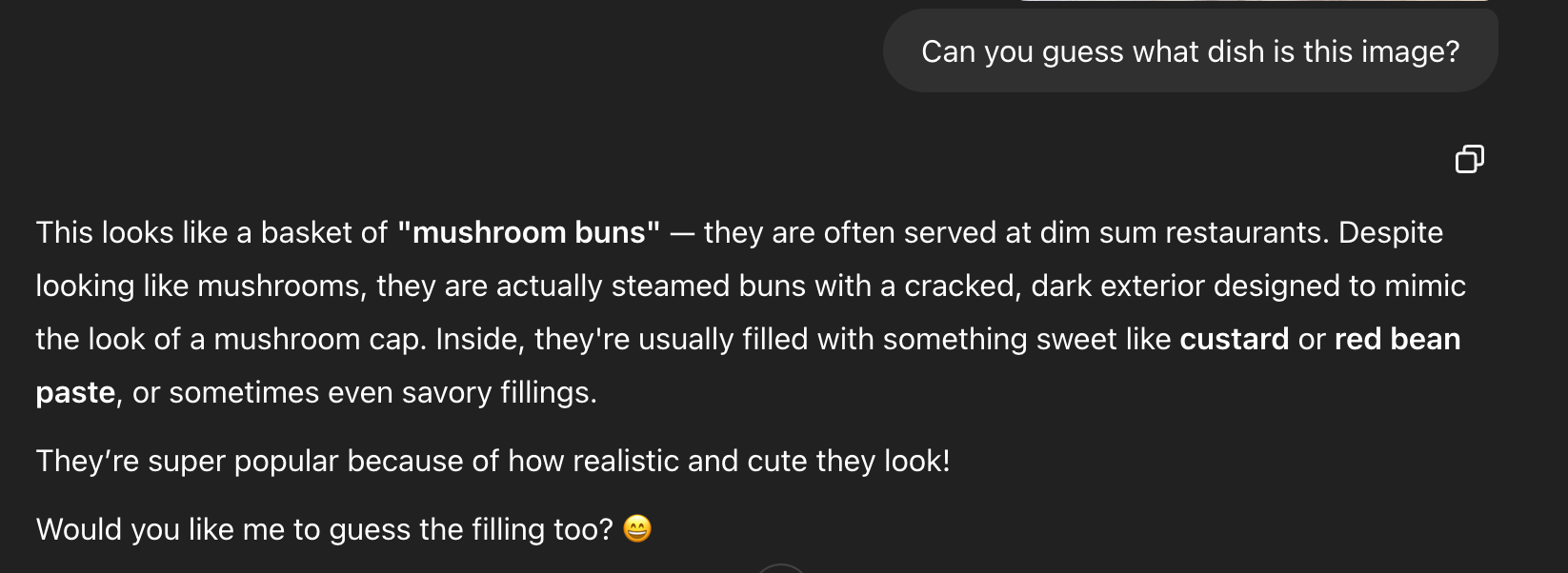
- ✅ Correctly identified the dish as "mushroom buns" served at dim sum restaurants
- ✅ Explained that they're steamed buns designed to look like mushrooms
- ✅ Noted that they typically contain sweet fillings like custard or red bean paste
- ✅ Recognised the intentional design mimicking mushroom caps
- ✅ Showed cultural knowledge about the dish's popularity
Aya Vision's Response:

- ❌ Incorrectly identified the dish as "char siu bao" (barbecued pork buns)
- ❌ Made incorrect assumptions about the filling being barbecued pork
- ❌ Provided irrelevant information about caramelisation
- ✅ Correctly identified the bamboo steamer and dim sum connection
Analysis: This test revealed significant differences in visual reasoning capabilities. GPT-4V correctly identified the uniquely designed mushroom buns, while Aya Vision misidentified them as a different dim sum dish entirely, demonstrating less refined visual reasoning.
4. Text Interpretation: Career Document
The Challenge: Both models were presented with a text-heavy image containing a "Career Episode" document and asked to summarise the key points.
Prompt: Summarise the key points from the text in this image.
Image used:

GPT-4V's Response:

- ✅ Extracted precise details (Flutter Developer Intern at STAGE, July 2022- June 2023)
- ✅ Correctly identified the company's focus (Indian regional content, OTT platform)
- ✅ Listed specific technical accomplishments (Navigation 1.0 to 2.0 migration, Sound Null Safety implementation)
- ✅ Captured challenges faced (limited Flutter resources, remote work communication)
- ✅ Organised information in a clear, structured format
- ✅ Maintained factual accuracy throughout
Aya Vision's Response:

- ❌ Failed to extract specific dates and company details
- ❌ Made vague generalisations about "full-stack application for producing Indian regional content"
- ❌ Incorrectly framed the document as if it were hypothetical, not a real experience
- ❌ Referenced non-existent elements ("Sound-Null Safety platform" rather than the concept)
- ❌ Missed key technical accomplishments and specific challenges
- ❌ Created a generic summary with poor factual fidelity to the original text
Analysis: GPT-4V demonstrated superior ability to extract, organise, and faithfully represent text information from the image, while Aya Vision provided a vague summary with multiple factual errors and omissions.
5. Object Counting: Urban Scene with Cars
The Challenge: Both models were shown an image of a street scene with multiple vehicles and asked to count the cars.
Prompt: How many cars do you see in this image?
Image:

GPT-4V's Response:
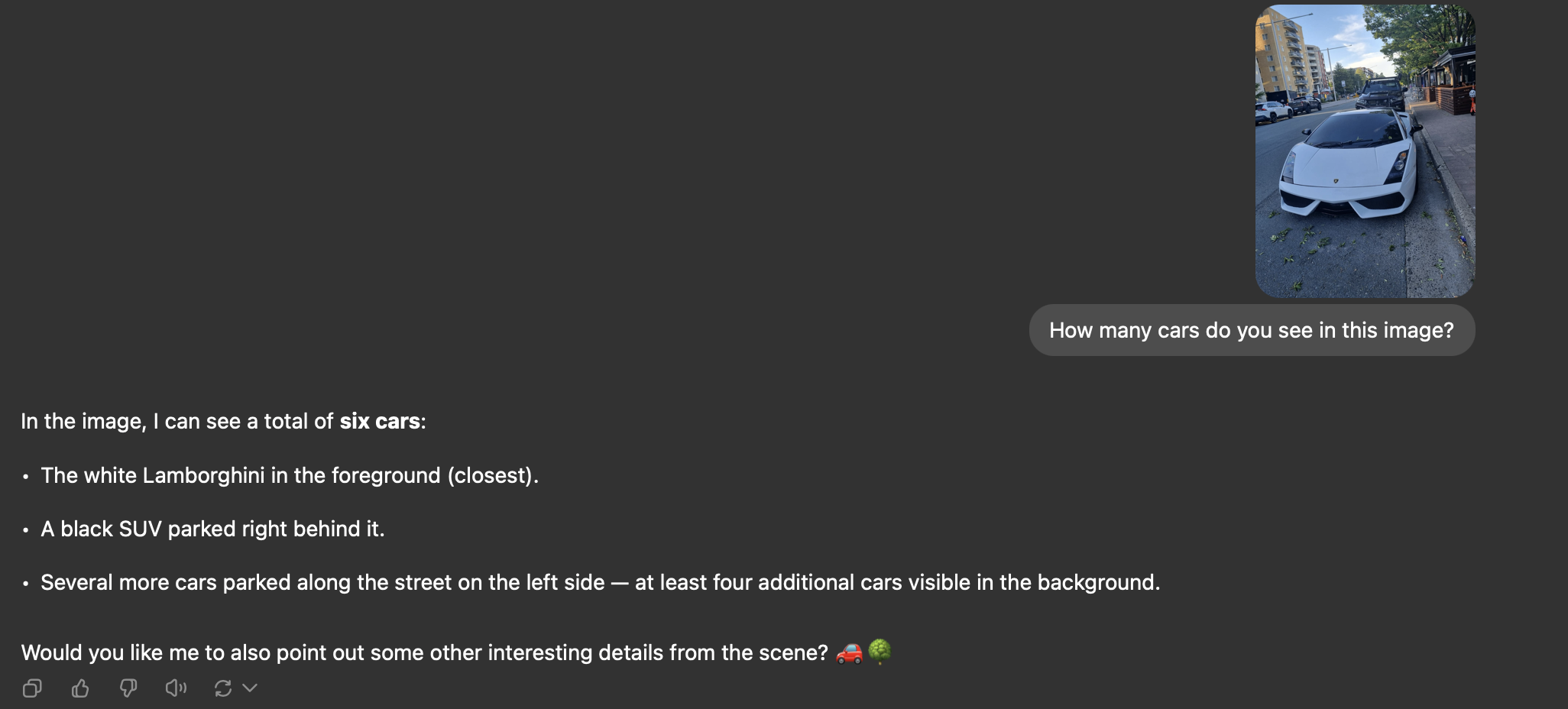
- ✅ Identified a total of six cars in the image
- ✅ Correctly recognised the white Lamborghini in the foreground
- ✅ Noted the black SUV parked behind it
- ✅ Identified approximately four additional cars in the background
- ✅ Demonstrated ability to detect partially visible vehicles at distance
Aya Vision's Response:
- ❌ Incorrectly counted only three cars
- ❌ Failed to identify the black SUV directly behind the Lamborghini
- ❌ Misidentified vehicle types (called the white Lamborghini a "sports car" and mentioned a "white SUV" that wasn't present)
- ❌ Missed multiple vehicles visible in the background
- ❌ Created a fictional scenario with "a car driving on the road" (all cars were parked)
Analysis: This test revealed Aya Vision's limitations in accurate visual counting and identification, even with clearly visible objects. GPT-4V demonstrated superior ability to detect, count, and correctly identify vehicles throughout the scene.
6. Multilingual Capabilities: Non-English Text Recognition
The Challenge: Both models were presented with images containing non-English text (Hindi and Chinese) and asked to translate the content.
Prompt: Translate the text in the attached image to English
Image used:

GPT-4V's Response:
- ✅ Successfully recognized Hindi text ("नमस्ते, आप कैसे हैं")
- ✅ Correctly translated it to English ("Hello, how are you?")
- ✅ Also demonstrated ability to recognise and translate Chinese characters
Aya Vision's Response:
- ❌ Failed to recognise Hindi text
- ❌ Unable to provide translation, and instead gave a gibberish result
- ❌ Similarly failed with Chinese character recognition
- ❌ Demonstrated significant limitation in multilingual OCR capabilities
Analysis: This test highlighted a critical limitation in Aya Vision's ability to process non-English text in images, while GPT-4V demonstrated strong multilingual OCR capabilities, successfully translating both Hindi and Chinese characters.
| Prompt Type | Prompt Description | Aya Vision 32B Response | ChatGPT Response | Analysis |
| Code Analysis | Analyze a Flutter code snippet for a floating header UI | Incorrectly identified as TypeScript, missed Flutter specifics | Correctly identified as Flutter, detailed analysis, suggested fixes | ChatGPT was accurate and insightful; Aya Vision failed to recognize Flutter. |
| Image Identification | Guess the dish in the image (steamed buns) | Misidentified as char siu bao (barbecued pork buns) | Correctly identified as mushroom buns, added context | ChatGPT was accurate; Aya Vision misinterpreted the dish. |
| Visual Question Answering | How many cars are in this image? | Counted 3 cars, missed the SUV behind the Lamborghini | Counted 6 cars, including background vehicles | ChatGPT was more accurate; Aya Vision undercounted. |
| Text Summarization | Summarize a career episode text | Misinterpreted context, missed key details | Accurate summary, captured key points | ChatGPT was precise; Aya Vision was vague and incorrect. |
| Multilingual Translation | Translate Hindi text in an image to English | Failed to translate Hindi and Chinese text from images | Correctly translated Hindi to "Hello, how are you?" | ChatGPT succeeded; Aya Vision failed despite its multilingual focus. |
Conclusion
While Cohere's Aya Vision model demonstrates competence in basic image recognition tasks, it currently lags behind GPT-4V in technical accuracy, hallucination control, visual reasoning capabilities, and multilingual text recognition. The significant hallucinations observed in technical contexts and counting tasks, combined with limited multilingual support, raise concerns about its reliability for professional applications requiring precision.
For users considering which vision model to implement, these findings suggest that GPT-4V currently offers more reliable performance across diverse use cases, particularly those requiring technical understanding, multilingual support, or faithful representation of image content.
As the field of multimodal AI continues to evolve rapidly, it will be interesting to see how Cohere refines Aya Vision in future iterations to address these challenges.





















