

Exploring Diffusion Models
How Diffusion Models Transform AI Image Generation

Introduction
In recent years, artificial intelligence (AI) has made significant advancements in generating images from text descriptions, a capability once thought to be science fiction. Among the various techniques driving this progress, diffusion models have emerged as a particularly powerful approach. But what exactly is a diffusion model in AI? Let’s break it down in simpler terms and understand it using the concepts of Stable Diffusion model in particular.
What is a Diffusion Model?
A diffusion model is a type of generative model that creates images by progressively refining random noise. The process is inspired by thermodynamic diffusion, where particles spread out over time. In the context of AI, diffusion models start with an image filled with random noise and iteratively remove the noise to reveal a clear and coherent picture. Stable Diffusion is a cutting-edge deep learning model introduced in 2022, designed for generating images from text descriptions using diffusion techniques. The model excels at creating detailed images based on text prompts and can also perform tasks like inpainting(filling in missing or corrupted parts of an image), outpainting(extending an image beyond its original boundaries), and text-guided image-to-image translations(modifying an image based on textual descriptions).
The architecture of Stable Diffusion Models
Stable Diffusion consists of 3 parts described below:
Variational Autoencoder (VAE)
This compresses the image from pixel space to a smaller, more manageable latent space, capturing the essential features of the image. The Variational Autoencoder (VAE) model consists of two main components: an encoder and a decoder. A 512 x 512 x 3 image is transformed by the encoder during latent diffusion training into a low dimensional latent representation of an image, say 64 x 64 x 4, for the forward diffusion process. These tiny encoded representations of images are referred to as latents. Every time we train these latents, we add an increasing amount of noise. The U-Net model receives this encoded latent representation of images as input. In this case, 48 times less memory is needed to turn an image of shape (3, 512, 512) into a latent of shape (4, 64, 64). When compared to pixel-space diffusion models, this results in lower memory and compute needs. The latent representation is converted back into a picture by the decoder. Using the VAE decoder, we turn the denoised latents produced by the reverse diffusion process into pictures. The denoised image can be transformed into actual images during inference by simply using the VAE decoder.
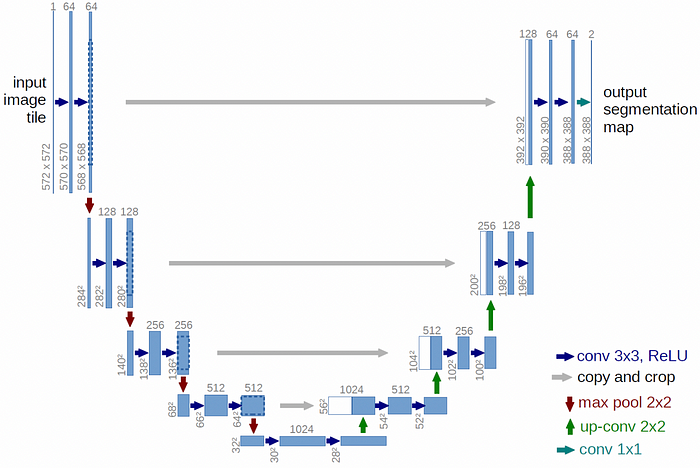
U-Net
A neural network that performs the denoising task, transforming the noisy latent representation back into a clean image. Denoised image representation of noisy latents is predicted by U-Net. In this case, one UNet produces noise in the latents as its output, while another Unet receives noisy latents as input. By using this, we can subtract the noise from the noisy latents and obtain true latents.
Text Encoder (optional)
For text-to-image generation, a pre trained text encoder like CLIP is used to transform text prompts into embeddings that guide the image generation process. When we train UNet for its denoising process, this serves as advice for noisy latents. A sequence of input tokens is mapped to a sequence of latent text embeddings by the text encoder, which is often a straightforward transformer-based encoder. Instead of training a fresh text encoder, Stable Diffusion takes advantage of CLIP, which is previously learned. The supplied text is converted into embeddings by the text encoder. The encoded text embeddings guide the U-Net model during its denoising steps, ensuring the noise is reduced in a way that aligns with the semantic content of the text, ultimately resulting in the generation of the final image.
When everything is considered, the model operates as shown in the below figure during the inference process:
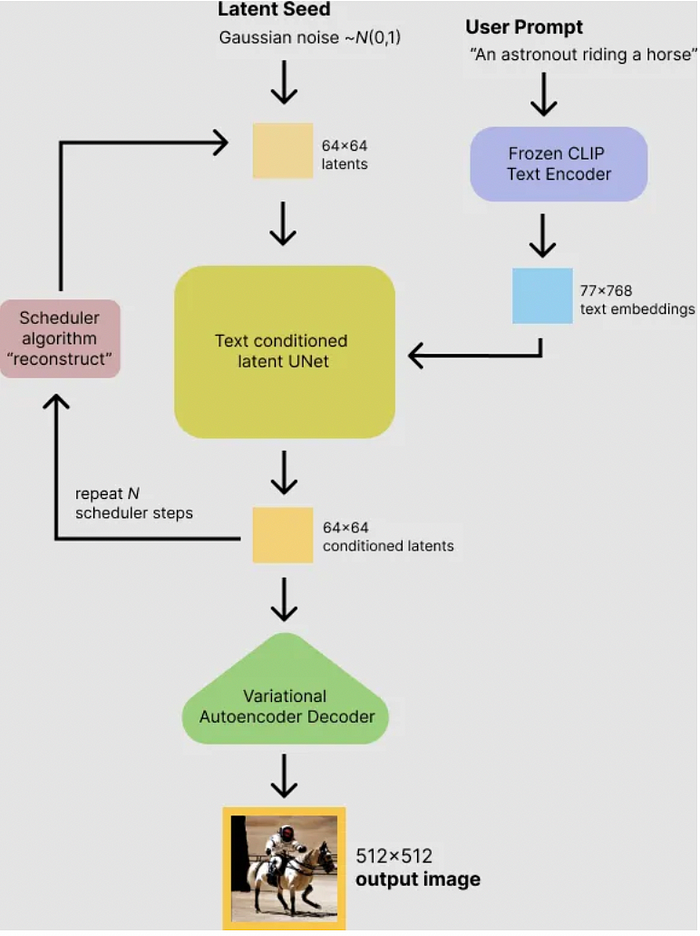
How Stable Diffusion Models Work
1. The Forward Diffusion Process
The forward diffusion process involves gradually adding noise to an image over a series of time steps until the image is almost entirely noise. This process can be thought of as taking a clear image and progressively degrading it by adding random noise.
2. The Reverse Diffusion Process
The reverse diffusion process is where the magic happens. The model learns to reverse the noise-adding process, starting from pure noise and iteratively denoising the image to generate a realistic output. This is achieved through a neural network, often a U-Net, that is trained to predict and remove the noise added in each step of the forward process.
The model is trained using a loss function that measures the difference between the predicted noise and the actual noise added during the forward process. Over time, the model becomes adept at predicting the noise, enabling it to generate high-quality images from random noise.
3. Denoising Images with U-Net
The U-Net architecture plays a crucial role in the denoising process. U-Net is a type of convolutional neural network (CNN) that is particularly effective for image-to-image translation tasks. It consists of an encoder that compresses the input image into a lower-dimensional representation and a decoder that reconstructs the image from this representation. Skipping connections between the encoder and decoder layers helps preserve spatial information, which is essential for generating detailed images.
4. Noise Prediction and Removal
At each time step of the reverse diffusion process, the U-Net model predicts the noise present in the current noisy image. This predicted noise is then subtracted from the noisy image to obtain a slightly denoised version. This process is repeated iteratively, with the model progressively refining the image until the noise is entirely removed and a clear image is produced.
5. Sampling in Inference and Training
During inference, the reverse diffusion process starts with pure noise and iteratively refines it into a coherent image. The number of steps in this process can be adjusted, with more steps typically resulting in higher-quality images but at the cost of increased computational time.
During training, the model learns to predict the noise at each time step by minimising the loss function, which measures the difference between the predicted noise and the actual noise. This training process requires a large dataset of images and significant computational resources.

Applications of Stable Diffusion Models
There are many applications of Diffusion Models, a few of them are listed below:
Text-to-Image Generation
One of the most popular applications of diffusion models is generating images from text descriptions. Models like Stable Diffusion can create detailed and high-quality images based on simple text prompts, opening up new possibilities in art, design, and content creation.
Image Inpainting and Outpainting
Diffusion models are also used for inpainting and outpainting. These techniques are valuable for editing and restoring images, as well as for creating expansive scenes from smaller visuals.
Image-to-Image Translation
Another exciting application is image-to-image translation, where diffusion models modify an existing image based on a text prompt or another image. This can include style transfer, enhancing image details, or even transforming a photo into a different artistic style.
Advancements in Diffusion Models
Stable Diffusion
Stable Diffusion is developed by Stability AI. It stands out for its ability to run on consumer-grade hardware with modest GPU requirements, making it accessible to a wider audience. The model’s architecture includes improvements like latent diffusion, which enhances computational efficiency without compromising image quality.
ControlNet
ControlNet is an advanced architecture designed to enhance the control over diffusion models. It duplicates the weights of neural network blocks into “locked” and “trainable” copies, allowing for fine-tuning on small datasets without compromising the original model. This ensures that the model can adapt to new conditions while preserving its integrity.
Conclusion
In conclusion, diffusion models represent a significant leap forward in AI capabilities, particularly in the area of image generation and manipulation. Stable Diffusion Model is a notable advancement in the field of diffusion models. By harnessing the power of gradual noise reduction and sophisticated neural networks like U-Net, these models not only produce high-fidelity images but also push the boundaries of what AI can achieve in creative and practical applications. Looking ahead, future advancements in diffusion models are likely to focus on enhancing their scalability, efficiency, and applicability across diverse domains. Research efforts will continue to refine these models, making them more accessible and capable of generating even more realistic and contextually relevant content. Moreover, integrating diffusion models with other AI techniques such as reinforcement learning and multimodal learning could unlock new possibilities in interactive and adaptive content creation.
References
- Wikipedia contributors, 2024. Stable diffusion. Wikipedia, The Free Encyclopedia, [online] Available at: https://en.wikipedia.org/wiki/Stable_Diffusion [Accessed 16 July 2024].
Catch the latest version of this article over on Medium.com. Hit the button below to join our readers there.






















