


Gemini 2.5 Pro
Hands-On with Gemini 2.5 Pro: Exploring Google’s New Frontier in AI
- •

Introduction
The AI landscape is evolving at breakneck speed, and Google is firmly in the race with its Gemini family of models. The latest iteration, Gemini 2.5 Pro, recently became available in preview, promising significant advancements in reasoning, coding, multimodality, and an enormous context window. To better understand the practical capabilities of this cutting-edge model, this post explores Gemini 2.5 Pro’s advertised strengths and puts them to the test using a range of real-world prompts.
What Is Gemini 2.5 Pro Advertised to Be?
Based on Google’s announcements and technical details, Gemini 2.5 Pro aims to push boundaries in several key areas:
Massive Context Window: The headline feature is its ability to process up to 1 million tokens of input context. This is a huge leap, potentially allowing for the analysis of entire codebases, lengthy books, or hours of video content in a single prompt. The benchmark data shows strong performance on the MRCR long context benchmark (94.5% at 128k avg, 83.1% at 1M pointwise), significantly outperforming comparisons.
Enhanced Reasoning and Performance: Google claims state-of-the-art results in key math and science benchmarks. The provided data shows Gemini 2.5 Pro edging out or competing closely with strong OpenAI models on benchmarks like GPQA Diamond (84.0%), AIME 2025 (86.7%), and AIME 2024 (92.0%). It also shows a significant lead in factuality on SimpleQA (52.9% vs 13.8%).
Multi-Modality: Gemini 2.5 Pro’s high scores on MMMU (81.7%) and Vibe-Eval (69.4%) reflect its strength in native multimodality—understanding and reasoning across text, images, audio, and video. MMMU tests subject-level reasoning with mixed media, while Vibe-Eval focuses on real-world visual understanding. The model’s ability to interpret varied inputs is a key differentiator. It also supports 35+ languages, enabling strong multilingual performance for global applications.
Accessing Gemini 2.5 Pro
Let’s address how you might get your hands on Gemini 2.5 Pro. Access is primarily available through Google AI Studio and Vertex AI, as detailed below.
Google AI Studio: This web-based interface is often the first place Google makes new models available for developers and enthusiasts to try. You typically need a Google account. AI Studio allows text-based interaction and often supports multimodal inputs (like uploading files or videos). You can also generate API keys here to use the model programmatically. Access it at https://aistudio.google.com/.
Vertex AI (Google Cloud): For more integrated enterprise or developer workflows, Gemini 2.5 Pro is available via Google Cloud’s Vertex AI platform. This requires a Google Cloud account and project setup. Access here might also be in preview and subject to specific terms.
Exploring and Testing the Model
Now, let’s move beyond the spec sheet and see how Gemini 2.5 Pro performs in practice. Google AI Studio was used throughout this blog to interact with the model. For comparison, similar prompts were run through OpenAI’s best models to gauge relative performance.
Test Area 1: Can It Really Digest and Reason Over Vast Amounts of Information?
A dense 112-page report from 2024 on Victoria’s Climate Science was uploaded.
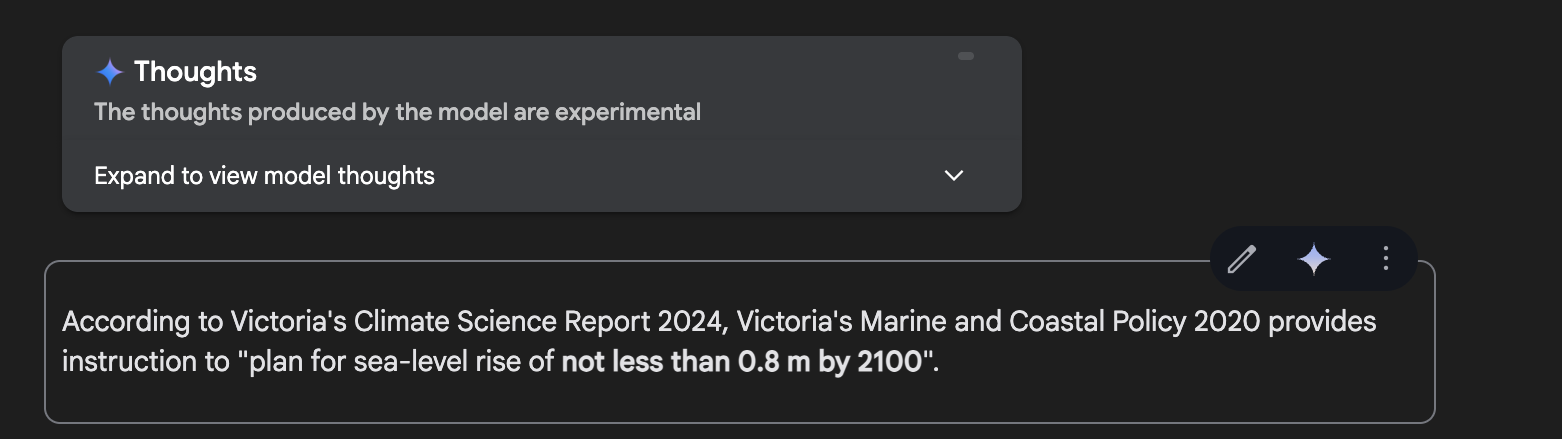
Prompt 1: "Based on the Victoria Climate Science Report 2024, what minimum sea-level rise by 2100 does the Victoria Marine and Coastal Policy 2020 require planners to prepare for?"Gemini 2.5 Pro Response
OpenAI 4o Response

Gemini 2.5 Pro was able to identify the specific part deep within the document almost instantly, giving it a slight edge. OpenAI’s model also performed well, accurately identifying the relevant content—highlighting impressive capabilities from both models in this area.
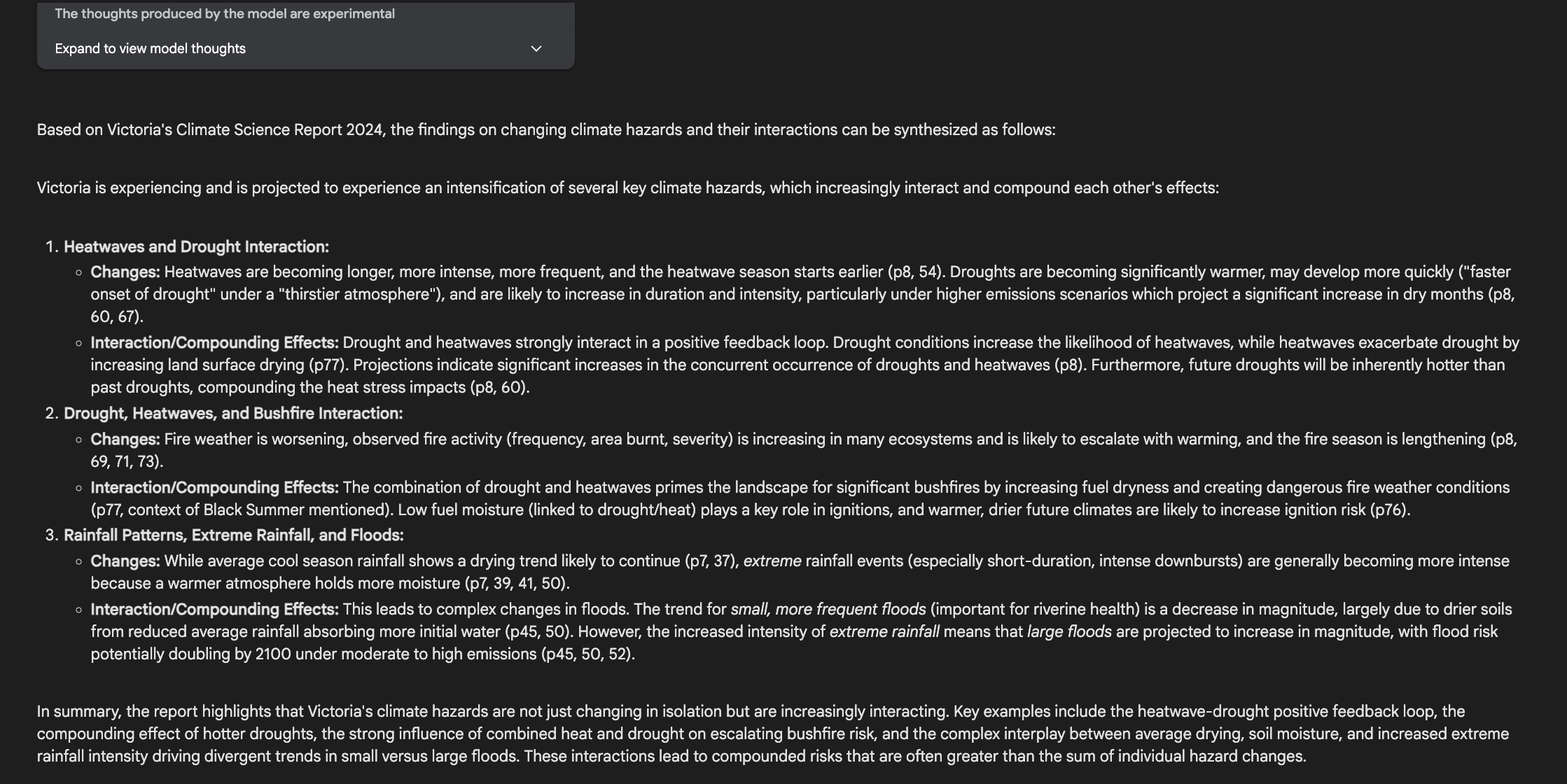
Prompt 2 (Synthesis Across the Document): “Synthesize the report’s findings on how different climate hazards discussed (like heatwaves, drought, extreme rainfall/floods, and bushfires) are projected to change in Victoria and interact with each other. Mention specific examples of these interactions or compounding effects highlighted in the document.”Why Test This Synthesis?
- Requires Cross-Referencing: The AI cannot answer this by looking at just one section. It needs to pull information from the individual hazard sections (Floods 4.1, Heatwaves 4.2, Drought 4.3, Bushfire 4.4) and potentially connect it to the general climate change trends (Sections 1, 2, 3).
- Focuses on Interactions: The core of the question is about how these hazards influence each other or occur concurrently, creating compounded risks (e.g., how drought and heatwaves affect bushfire risk, how extreme rain falls on dry catchments).
- Asks for Specific Examples: It requires the AI to identify concrete examples mentioned in the text (like concurrent drought and heatwaves, warmer droughts, increased large flood magnitude despite smaller floods decreasing, drought/heat influence on bushfires) rather than just giving a generic summary of each hazard projection.
Gemini 2.5 Pro Response
OpenAI Response

Both summaries generated by Gemini and OpenAI were comprehensive and accurately reflected the points made throughout the paper.
Test Area 2: Reasoning and Problem Solving
Prompt: A 6-digit number has the following properties: It’s divisible by 11. When you move the first digit to the end, the new number is exactly 3 times the original. What is this number?Gemini 2.5 Pro Response:

Gemini demonstrated strong step-by-step reasoning to arrive at the correct answer. It solved the problem analytically by applying number properties and constraints, rather than brute-forcing. The solution included mathematical logic, which showcased the model’s capability in structured reasoning.
When tested against OpenAI 4o, this model approached the problem using Python code that brute-forced all 6-digit numbers (from 100000 to 999999), checking which ones satisfied both conditions. While this is a valid approach computationally, it lacks mathematical insight and reasoning. Even so, it produced an incorrect final answer.
When tested using OpenAI advanced reasoning model O4-mini-high, it gave the below result:

It produced the same correct answer as Gemini 2.5 Pro. However, instead of walking through the reasoning steps, it presented the solution first and then verified that it satisfied both conditions. While the answer was correct, the lack of transparent reasoning limits its usefulness for assessing problem-solving capability.
Test Area 3: Coding Abilities
Prompt (LeetCode Hard):
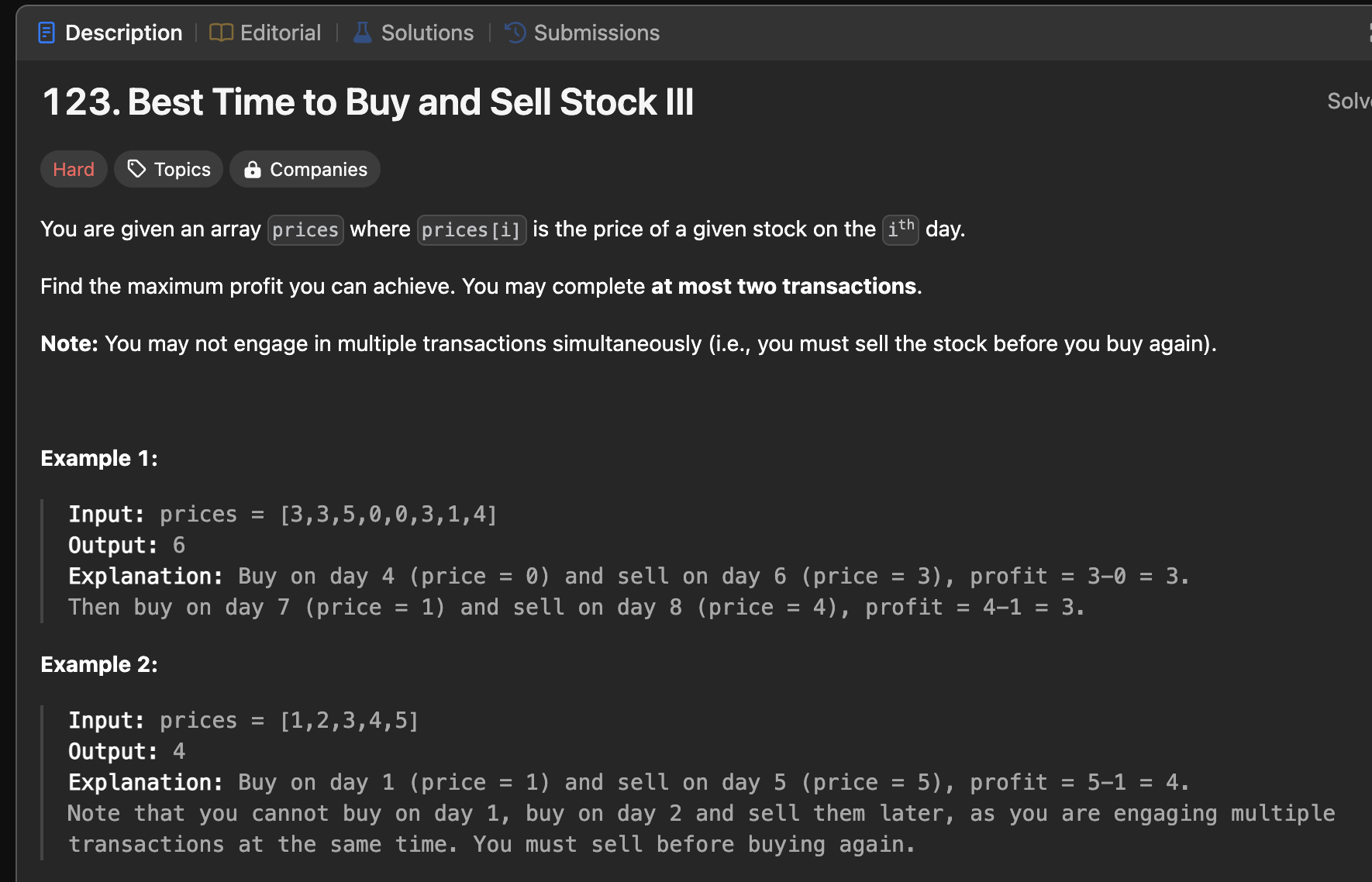
Coding abilities were evaluated using the above question. Both Gemini and the OpenAI advanced reasoning model successfully generated correct solutions. Gemini took approximately 100 seconds and produced a solution that outperformed 76.92% of submissions in terms of time complexity. In contrast, OpenAI’s O4-mini-high responded in just 4 seconds and generated a solution with the same performance benchmark, also beating 76.92% of participants on complexity.
Test Area 4: Multi-Modality
Both Gemini 2.5 Pro and OpenAI’s latest models support image understanding, but their capabilities diverge when it comes to video.
Gemini 2.5 Pro stands out for its integrated multi-modal support. Users can upload video files directly or provide YouTube links for the model to process. It can analyze, summarize, transcribe, and even translate video content—all within the same interface. This makes Gemini highly practical for real-world multimedia tasks involving both static and dynamic visual data.
On the other hand, OpenAI’s models, while capable with images, don’t natively support video input within ChatGPT. OpenAI’s video-related work, like Sora, is focused on generating video from text prompts, not analyzing existing video content. Moreover, Sora is not yet integrated into the main ChatGPT interface and operates as a separate model.
Conclusion
Gemini 2.5 Pro clearly marks a significant step forward in AI capability, especially in long-context reasoning, problem solving, and native multimodal understanding. Its performance in digesting extensive documents, solving logic-based tasks with clear rationale, and handling both static and dynamic media positions it as a versatile tool for developers, researchers, and enterprises alike. While OpenAI models remain highly competitive, particularly in speed and coding efficiency, Gemini’s edge in transparent reasoning and integrated video comprehension sets it apart. As these models continue to evolve, Gemini 2.5 Pro stands as a strong contender at the forefront of the next generation of AI.
References
- OpenAI (2025b). OpenAI. https://openai.com/.
- OpenAI (2025a). DALL·E 3. https://openai.com/index/dall-e-3/.
- LeetCode (2021). LeetCode – The World’s Leading Online Programming Learning Platform. https://leetcode.com/.
- Google.com. (2024). Google AI Studio. https://aistudio.google.com/prompts/new_chat.
- Victoria’s Climate Science Report 2024. (n.d.). https://www.climatechange.vic.gov.au/victorias-changing-climate/Victorias-Climate-Science-Report-2024.pdf.





















