


GR-2: A Generative Video-Language-Action Model for Robot Manipulation
Let’s explore GR-2 together.
-

- •

Introduction
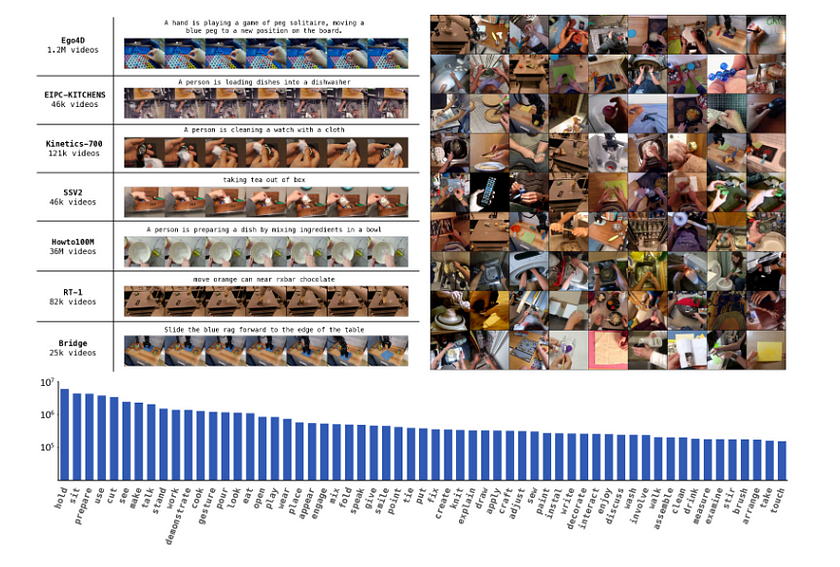
GR-2 is a cutting-edge generative model designed for versatile and generalisable robot manipulation, developed by the Robotics Research Team at ByteDance Research. It represents a significant step forward in robotics, enabling robots to execute a wide range of manipulation tasks in various environments. GR-2 leverages video generation and action prediction to empower robots with strong generalisation capabilities, allowing them to perform complex tasks even in unseen scenarios.
At its core, GR-2 aims to solve one of the key challenges in modern robotics: how to make robots adapt to diverse tasks and environments with minimal retraining. Traditionally, robots require task-specific programming, which limits their flexibility in real-world applications. GR-2 addresses this by training on a massive dataset of internet videos, capturing the dynamics of the world and translating that knowledge into robotic actions. By pre-training on 38 million video clips and over 50 billion tokens, followed by fine-tuning on robot trajectories, GR-2 can generalise across a wide range of tasks and environments, achieving a high success rate in complex manipulation scenarios.
Training Process
GR-2’s training process is divided into two key stages:
- Pre-training on Video Generation: The first stage involves training GR-2 to predict future states in videos, capturing the temporal dynamics and semantics from large-scale video datasets. This training is essential for GR-2 to learn how objects interact and how environments evolve over time. The dataset used for pre-training is highly diverse, consisting of human activities in contexts like households, workplaces, and outdoor environments. The model learns to generate the next video frame based on a given textual description and the current frame, providing it with a strong foundation for subsequent robot learning.
- Fine-tuning on Robot Data: In the second stage, GR-2 is fine-tuned using robot trajectory data to predict both action trajectories and corresponding video sequences. Unlike the video data used in pre-training, robot data often involves multiple camera angles and viewpoints, which GR-2 is designed to handle gracefully. This fine-tuning stage optimises the model to generate accurate action trajectories in Cartesian space, allowing robots to perform tasks precisely. The model’s Whole-Body Control (WBC) algorithm ensures that the robot follows the planned trajectories smoothly, incorporating real-time motion tracking and trajectory optimisation.
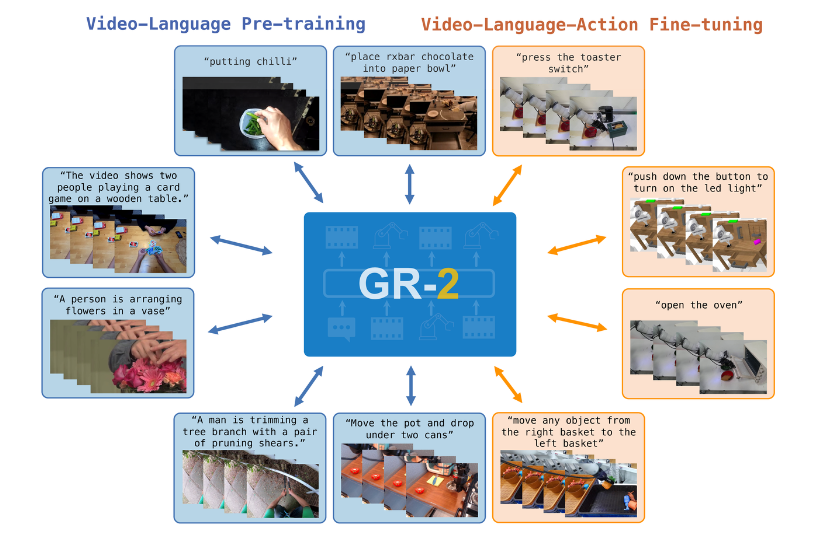
By first conducting pre-training on video generation, the GR-2 model can fully leverage the general knowledge obtained from large-scale video data, significantly reducing the need for extensive robot-specific data. After completing video generation pre-training, the model learns how to predict future visual states. During fine-tuning, these visual predictions aid the model in more effectively planning the robot’s action sequences. Since the model already possesses the ability to anticipate environmental changes, it can swiftly generate accurate action trajectories during real-world operations, ensuring smoother and more efficient execution of robotic tasks.
Benchmark Test Results
GR-2 was evaluated across multiple benchmarks to demonstrate its capability:
Multi-task Learning
Multi-task Learning: GR-2 was tested on 105 different manipulation tasks, achieving an average success rate of 97.7%. These tasks involved a variety of complex operations such as picking, placing, uncapping, pressing, and more. GR-2 excelled even in challenging settings like environments with distractors, unseen backgrounds, and unseen tasks. This high performance highlights its ability to handle real-world variability and adapt to new situations with minimal additional training.
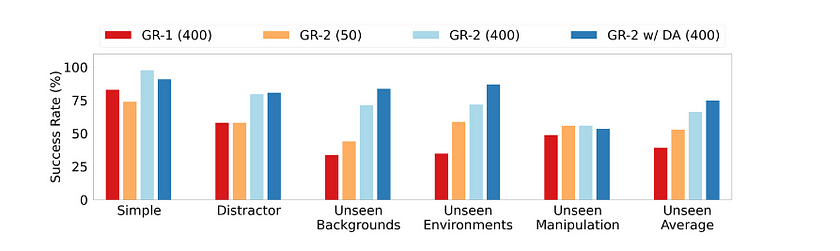

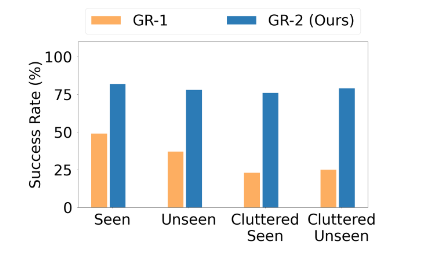
End-to-End Bin-Picking
End-to-End Bin-Picking: In an industrial context, GR-2 was tested on a bin-picking task involving 122 objects, 55 of which were seen during training and 67 unseen. GR-2 outperformed its predecessor GR-1 by a large margin, maintaining a success rate comparable between seen and unseen objects. It also managed cluttered environments without significant degradation in performance, showcasing its potential for practical applications in industries like logistics and manufacturing.

CALVIN Benchmark
CALVIN Benchmark: GR-2 established a new state-of-the-art on the CALVIN benchmark, a simulation environment designed for long-horizon, language-conditioned robot manipulation tasks. GR-2 outperformed five leading models, including RT-1 and HULC, in terms of success rates and average task completion length. It demonstrated the ability to complete sequences of tasks in a row, further proving its versatility and efficiency.

CALVIN Benchmark: The CALVIN Benchmark consists of 34 different manipulation tasks, where the robot needs to execute these tasks sequentially after receiving language instructions. These tasks involve complex multi-step operations, with the core evaluation focusing on:
- Language-conditioned manipulation: Whether the robot can understand and execute tasks based on natural language instructions.
- Long-horizon task sequences: The robot needs to maintain accurate operations across multiple tasks while understanding and handling a continuous chain of tasks.
- Generalisation ability to tasks: Whether the robot can efficiently complete tasks in previously unseen environments and with unfamiliar instructions.
Thus, the CALVIN Benchmark is a comprehensive standard used to assess a robot’s ability in task generalisation, long-horizon task handling, and complex task planning under language-conditioned manipulation.
Auto-Regressive Video Generation
A unique aspect of GR-2 is its use of auto-regressive video generation to aid in action prediction. By generating future video frames, the model can act as a planner, simulating how a task will unfold before executing it. This capability allows GR-2 to improve action accuracy by ensuring that predicted trajectories align with expected visual outcomes. In experiments, the generated videos closely matched real-world rollouts, indicating that the model can effectively “replay” the predicted action based on the generated visual trajectory. This iterative improvement of video generation translates directly into more accurate and reliable action prediction.
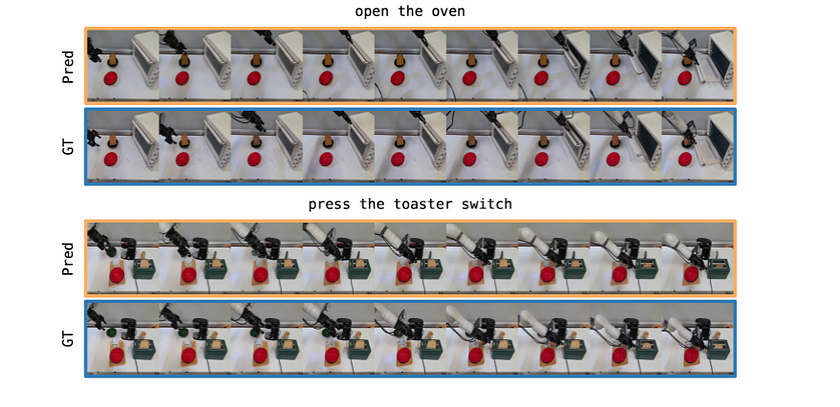
In this image, Pred and GT represent the following:
- Pred: This stands for Predicted, referring to the video sequence predicted by the GR-2 model. It shows how the model anticipates future actions and corresponding visual outputs based on the input. For example, in this figure, the model predicts the robot’s actions for tasks such as “open the oven” and “press the toaster switch.”
- GT: This stands for Ground Truth, representing the actual video frames of the robot performing these tasks in real life. This is the real data of how the robot executed these tasks in reality.
The purpose is to demonstrate how well the model’s predictions (Pred) align with real-world execution (GT), showcasing GR-2’s ability to predict actions through auto-regressive video generation. This highlights the model’s accuracy in forecasting future visual states.
Real-World Application and Performance
1. Accurate grasping capability
The GR-2 model excels in precise object manipulation, including highly accurate grasping capabilities. It can effortlessly handle tasks such as grasping cylindrical glass bottles or even very thin items, ensuring reliable performance even with challenging objects that require careful handling. This makes it a powerful tool for intricate and precise robotic tasks in various real-world applications.




2. Accurate grasping capability
The GR-2 model is also capable of assisting humans with a wide range of everyday tasks, from preparing breakfast to making coffee. Its advanced capabilities allow it to perform complex activities with precision, making it an ideal solution for automating routine tasks and supporting daily activities with ease.


3. Sorting tasks
The GR-2 model can also perform sorting tasks with high efficiency. For example, it can sort fruits on a table and place them into different bowls as needed. This ability to organise and classify objects makes GR-2 a versatile tool for managing sorting tasks in both everyday and industrial scenarios.


In the past, many AI models primarily focused on large language models (LLMs) or image generation capabilities, with their influence largely confined to the digital realm, limited to interactions within computers or operating systems. They lacked the ability to directly affect the physical world. However, with this model, they are taking a significant step forward. GR-2 goes beyond the boundaries of traditional AI by bridging the gap between digital intelligence and real-world action. This model not only excels in understanding and generating language, but also has the capability to manipulate and interact with the physical environment.
In the future, this could pave the way for AI-driven generalist robots, capable of not only engaging in conversation with humans but also solving real-world problems — whether it’s managing tasks in a household or assisting in industrial operations. This vision, once confined to science fiction films, could soon become a reality. GR-2 represents a glimpse of what the future of AI holds: a world where intelligent robots enhance our lives in both virtual and physical spaces. This is not just an advancement in robotics; it’s a fundamental shift in how AI can impact and transform the world around us.
Conclusion
GR-2 represents a significant leap forward in the field of robotics, combining cutting-edge video generation and action prediction to enable robots to interact with and manipulate the physical world in complex ways. Its ability to generalise across tasks, environments, and unseen scenarios — combined with its precise handling of objects and real-world tasks — makes it a powerful and versatile tool for both industrial and everyday applications. From accurate grasping to sorting tasks, GR-2 demonstrates remarkable adaptability and efficiency, bringing us closer to the future of AI-driven robots capable of performing a wide range of human tasks. This model not only extends the capabilities of traditional AI models but also bridges the gap between digital intelligence and physical action, offering a glimpse into a future where intelligent robots can work alongside humans to solve real-world problems.
References
- Cheang, C.L., Chen, G., Jing, Y., Kong, T., Li, H., Li. Y., Liu, Y., Wu, H., Xu, J., Yang, Y., Zhang, H., Zhu, M. (2024). GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation. DOI: 10.48550/arXiv.2410.06158.
Catch the latest version of this article over on Medium.com. Hit the button below to join our readers there.






















