


How OpenAI’s O1 Series Stands Out Redefining AI Reasoning
Exploring whether OpenAI’s O1 models represent a true breakthrough in AI reasoning or just incremental progress
-

- •

Introduction
OpenAI’s recently released O1 series models signify a significant step forward in the field of artificial intelligence, particularly in complex reasoning. The O1 model series not only handles more intricate problems but also introduces human-like thought processes, elevating the model’s reasoning capabilities to new heights. In this article, we will delve into the core features of the O1 series models.
The O1 series models from OpenAI include two main versions, each designed to meet different needs:
- O1-preview: This is the preview version of O1, specifically designed for complex reasoning tasks. It excels in handling high-difficulty scientific, mathematical, and programming problems.
- O1-mini: This version focuses on speed and cost optimisation, making it suitable for reasoning tasks that do not require extensive world knowledge, offering a more efficient and cost-effective reasoning experience.
The O1 series models use reinforcement learning training, allowing them to generate internal thought chains before answering questions, thereby improving reasoning accuracy and the ability to solve complex problems. Compared to previous models, O1 features a more robust self-correction mechanism and adaptability.
Core Features
The O1 series models showcase groundbreaking advancements in several areas:
- Powerful Reasoning Abilities: Whether in science, mathematics, or programming, O1 excels at solving complex problems that previous models could not handle.
- Chain-of-Thought Reasoning: Before providing an answer, the model simulates human thought processes, creating a long chain of reasoning paths, making the reasoning process more logical and coherent.
- Self-Correction Mechanism: O1 can identify its own errors and try different strategies to improve its responses, enhancing task completion success rates.
- Performance Improvement: The performance of O1 significantly improves with increased training and reasoning time, especially on high-complexity tasks.
- Enhanced Security: O1 excels in detecting prohibited content and resisting “jailbreak” attacks, making it more secure than previous models.
Performance
The O1 series models have achieved remarkable results in multiple benchmark tests:
- Ranked in the top 89% in the Codeforces programming competition.
- Entered the top 500 in the American Invitational Mathematics Examination (AIME), demonstrating strong mathematical reasoning abilities.
- Outperformed human PhD levels in the GPQA (General Physics, Biology, Chemistry) benchmark tests, showcasing its advantage in academic reasoning.
Application Scenarios
The powerful reasoning capabilities of the O1 series models make them highly promising in various fields. Here are some typical application scenarios:
- Medical Research: O1 can assist scientists in annotating complex cell sequencing data, accelerating the progress of medical research.
- Physics: O1 can be used to generate complex quantum optics formulas, advancing cutting-edge physics research.
- Software Development: Developers can use O1 to easily build and execute multi-step workflows, improving development efficiency and accuracy.
Technical Principles
The exceptional performance of the O1 series models is based on advanced technical foundations:
- Large-Scale Reinforcement Learning Algorithms: Through reinforcement learning, O1 gradually mastered how to use “chain-of-thought” reasoning, enhancing its ability to handle complex reasoning tasks.
- Extended Reasoning Time: By extending the computation time during the reasoning stage and increasing the number of samples, O1 can improve the accuracy of answering complex questions.
- Post-Training Optimization: O1 further optimised self-reasoning and logical checking functions during the post-training stage, ensuring the reliability and accuracy of its answers.
Limitations
Despite the impressive performance in many areas, the O1 series models have some limitations:
- High Cost: Compared to the previous GPT-4o models, the input and output costs of O1 are three and four times higher, respectively, limiting its economic viability for large-scale applications.
- Slower Speed: O1 may require more than 10 seconds to respond when handling complex problems.
- Functional Limitations: Currently, the O1 series lacks web browsing, file uploading, and image processing capabilities, which may limit its use in certain scenarios.
The O1 series models demonstrate OpenAI’s latest advancements in the field of complex reasoning. While there is still room for improvement, the breakthroughs in reasoning capabilities, performance, and application scenarios undoubtedly lay a solid foundation for the future of artificial intelligence technology.
Significant Progress
Compared to GPT-4o, the o1-preview model has improved its ability to solve mathematical and programming problems by over 5 times, while the yet-to-be-released o1 model has achieved an improvement of over 8 times! The success rate in solving PhD-level scientific problems has surpassed that of human experts. Its performance in physics and chemistry competitions exceeds that of human PhDs. In the International Mathematical Olympiad (IMO) qualification exam, GPT-4o only correctly solved 13% of the problems, whereas the reasoning model scored 83%. In programming competitions, the model’s abilities on Codeforces have surpassed 89% of human participants. It appears that o1 exceeds the highest human capabilities in various fields, including science, making it easy to understand Altman’s previous confidence in achieving AGI.
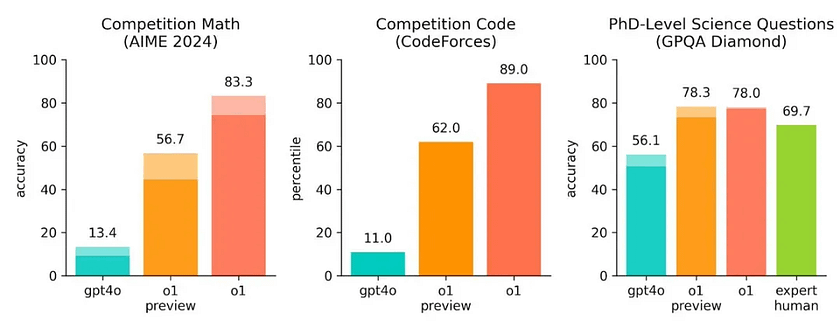
The o1 model has made significant improvements over GPT-4o on challenging reasoning benchmarks.
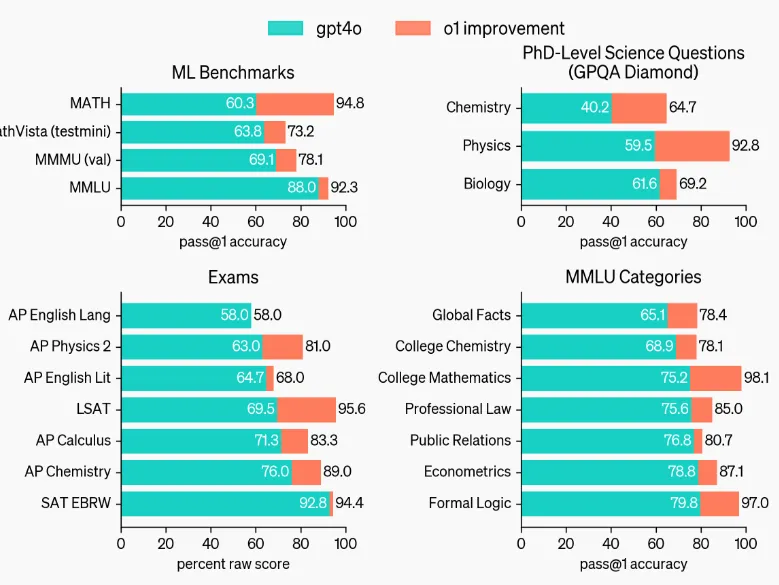
The o1 model has shown improvements over GPT-4o across a wide range of benchmarks, including 54 out of 57 MMLU subcategories, with 7 of these illustrated for demonstration.
In many reasoning-intensive benchmarks, the performance of the o1 model is comparable to that of human experts. Recent cutting-edge models have performed so well on MATH and GSM8K that these benchmarks are no longer effective at distinguishing between models. Consequently, OpenAI evaluated mathematical performance on the AIME, an exam designed to test the brightest high school math students in the United States.
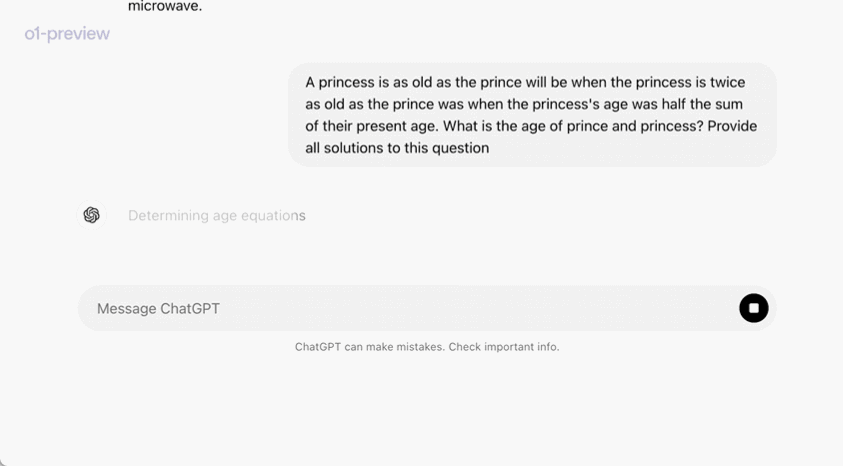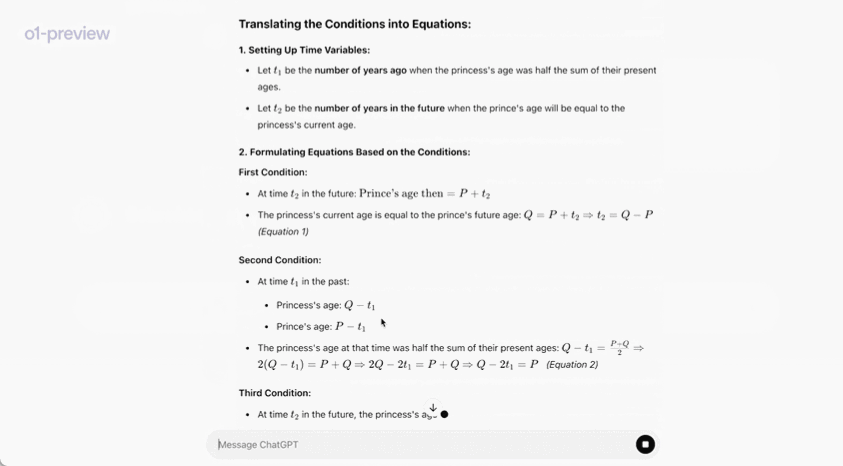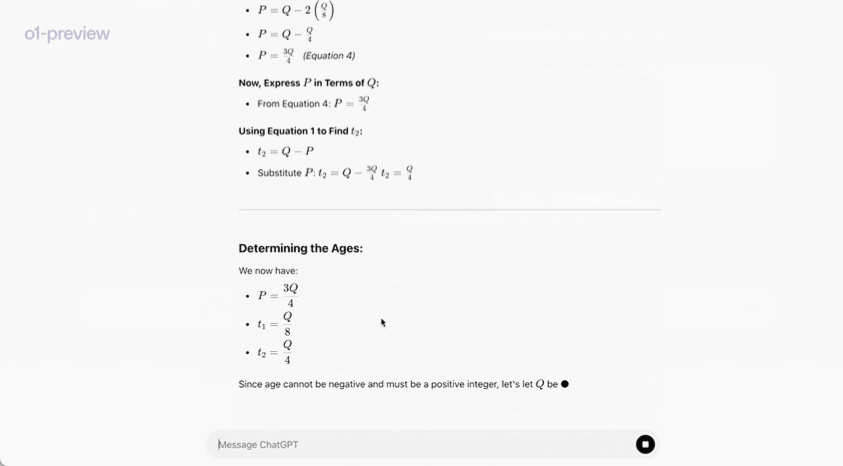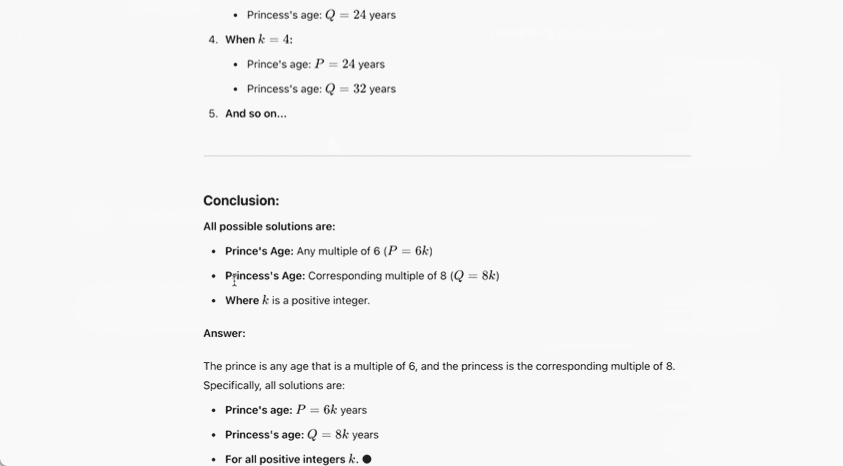
In an official demonstration, o1-preview solved a very difficult reasoning problem: When the princess’s age is twice the prince’s age, the princess’s age is the same as the prince’s, and the princess’s age is half the sum of their current ages. What are the ages of the prince and the princess?
In the 2024 AIME exam, GPT-4o managed to solve only 12% (1.8/15) of the problems on average, whereas o1 achieved an average of 74% (11.1/15) with just a single sample per problem, 83% (12.5/15) with consensus across 64 samples, and 93% (13.9/15) when using a learned scoring function to rerank 1000 samples. A score of 13.9 would place o1 in the top 500 nationwide and above the cutoff for the USA Mathematical Olympiad.
OpenAI also evaluated o1 on the GPQA Diamond benchmark, a challenging intelligence benchmark designed to test expertise in chemistry, physics, and biology. To compare the model with humans, OpenAI hired PhD-level experts to answer the GPQA Diamond benchmark questions.
The results showed that o1 outperformed human experts, becoming the first model to do so on this benchmark.
These results do not imply that o1 is more capable than PhDs in all respects — just that the model is better at solving some problems that PhDs are expected to solve. On several other ML benchmarks, o1 achieved new state-of-the-art (SOTA) results.
With visual perception enabled, o1 scored 78.2% on the MMMU benchmark, becoming the first model to match human expert performance. Additionally, o1 outperformed GPT-4o in 54 out of 57 MMLU subcategories.
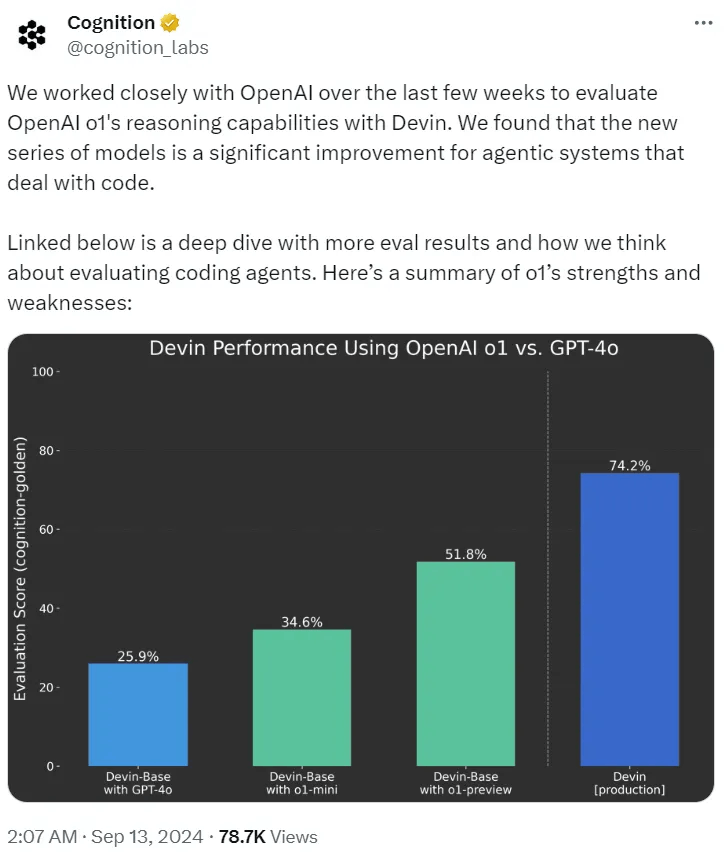
Cognition AI, the developer of the first AI software engineer Devin, stated that it has been closely collaborating with OpenAI over the past few weeks, using Devin to assess o1’s reasoning capabilities. The findings revealed that compared to GPT-4o, the o1 series models represent a significant advancement for intelligent systems dealing with code.
In practice, it is evident that the reasoning process of the new model differs significantly from before. We can now see a Show chain of thought boxes that can be toggled on and off, revealing the entire thought process. Much like the extended contemplation humans undergo before answering difficult questions, o1 breaks down problems through deliberate thinking, tackling each subtask methodically and repeatedly reflecting on them, identifying and correcting errors. When one approach fails, it tries another, significantly enhancing the model’s reasoning capabilities. Similar to the dual-process theory of the human brain, ChatGPT has evolved from relying solely on System 1 (fast, automatic, intuitive, prone to errors) to being capable of utilising System 2 thinking (slow, deliberate, conscious, reliable). This evolution enables it to solve problems that were previously unsolvable.
With simple prompts, users might not notice much of a difference, but when faced with tricky math or coding problems, the distinction becomes apparent. More importantly, the path for future development is now becoming clear.
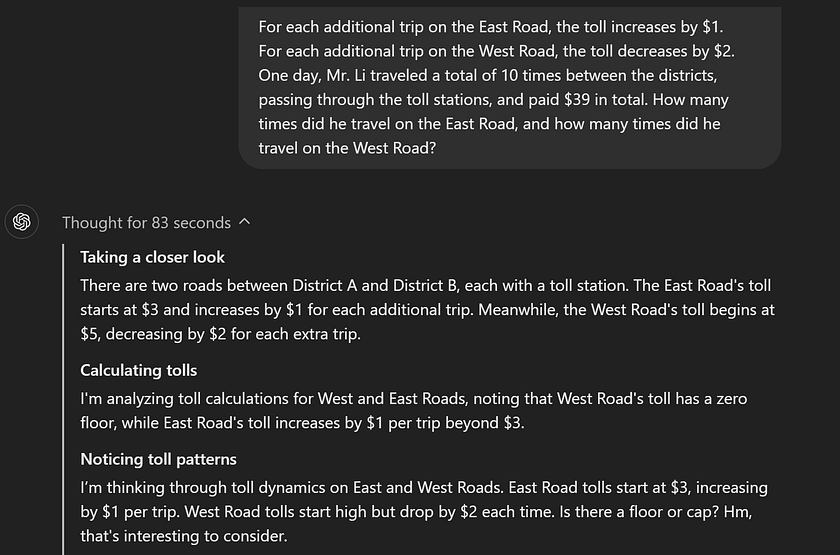
Coding Performance
After initialising and further training its programming skills based on o1, OpenAI developed a highly powerful programming model (o1-ioi). This model scored 213 points on the 2024 International Olympiad in Informatics (IOI) problems, placing it in the top 49% of participants. The model faced the same conditions as human contestants in the 2024 IOI: solving six high-difficulty algorithmic problems within 10 hours and being limited to 50 submissions per problem.
For each problem, this specialized o1 model samples many candidate solutions and then submits 50 of them based on a test-time selection strategy. The selection criteria include performance on IOI public test cases, model-generated test cases, and a learned scoring function.
Research indicates that this strategy is effective. If a solution were submitted randomly, the average score would be only 156 points. This suggests that under the competition conditions, this strategy is worth at least 60 points.
OpenAI found that relaxing the submission constraints significantly boosts the model’s performance. If each problem allows 10,000 submissions, even without using the aforementioned test-time selection strategy, the model can achieve 362.14 points — enough to earn a gold medal.
Finally, OpenAI simulated a competitive programming contest hosted by Codeforces to demonstrate the model’s coding skills. The evaluation closely followed the contest rules, allowing 10 code submissions. GPT-4o’s Elo rating was 808, placing it in the top 11% among human competitors. The model significantly outperformed GPT-4o and o1 — it achieved an Elo rating of 1807, surpassing 93% of competitors.
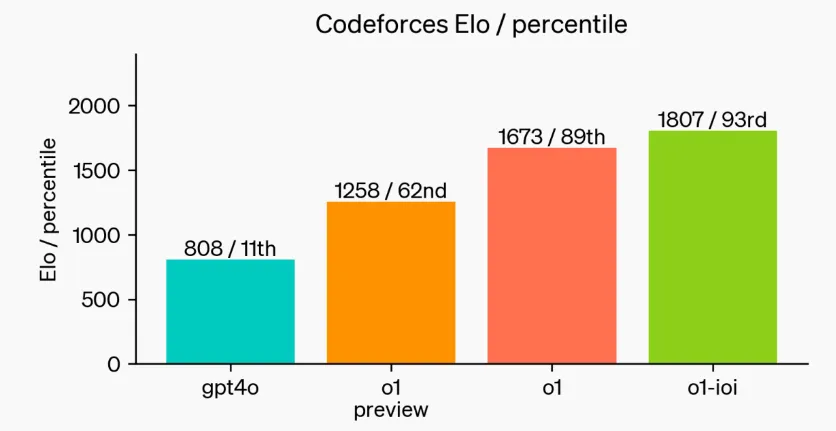
Further fine-tuning for programming competitions enhanced the capabilities of o1, allowing it to rank in the top 49% under the rules of the 2024 International Olympiad in Informatics (IOI).
The following official example vividly demonstrates the programming capabilities of o1-preview: with just a single prompt, it was able to write a fully functional game.

Human Preference Evaluation
Beyond exams and academic benchmarks, OpenAI also assessed human preferences for o1-preview and GPT-4o on challenging open-ended prompts in various domains.
In this evaluation, human raters anonymously reviewed responses to prompts from both o1-preview and GPT-4o, voting for their preferred answers. In categories requiring strong reasoning abilities, like data analysis, programming, and mathematics, o1-preview was significantly more favoured than GPT-4o. However, o1-preview was less preferred for some natural language tasks, indicating that it might not be suitable for all use cases.
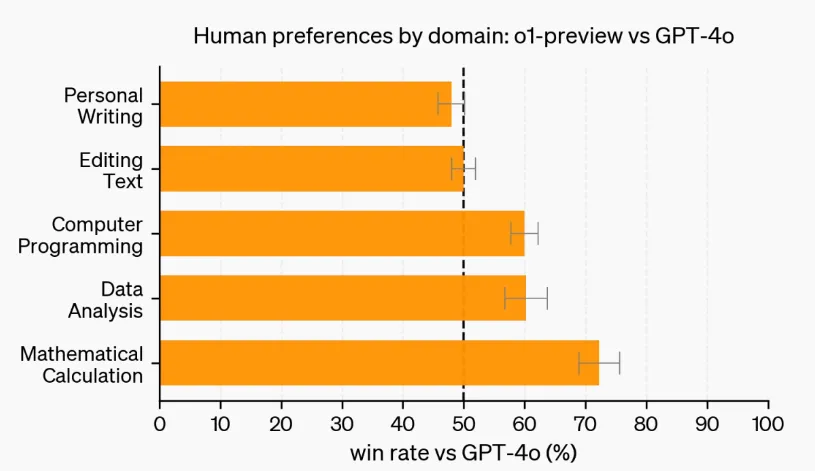
In domains requiring stronger reasoning abilities, people showed a preference for o1-preview.
Safety
Chain-of-Thought (CoT) reasoning offers new perspectives for safety and alignment. OpenAI found that integrating model behavior strategies into the reasoning model’s chain of thought can efficiently and robustly instill human values and principles. By teaching the model its own safety rules and how to reason through them in context, OpenAI discovered direct evidence that reasoning abilities contribute to model robustness: o1-preview showed significant improvements in critical jailbreak evaluations and the most stringent internal benchmarks used to assess the model’s safety refusal boundaries.
OpenAI believes that using CoT can bring substantial progress to safety and alignment because 1) it allows for clear observation of the model’s thought process, and 2) the model’s reasoning about safety rules is more robust in out-of-distribution scenarios.
To stress-test their improvements, OpenAI conducted a series of safety tests and red-teaming exercises according to their safety readiness framework before deployment. The results indicated that CoT reasoning contributed to enhanced capabilities throughout the evaluation process. Notably, OpenAI observed intriguing instances of reward hacking.
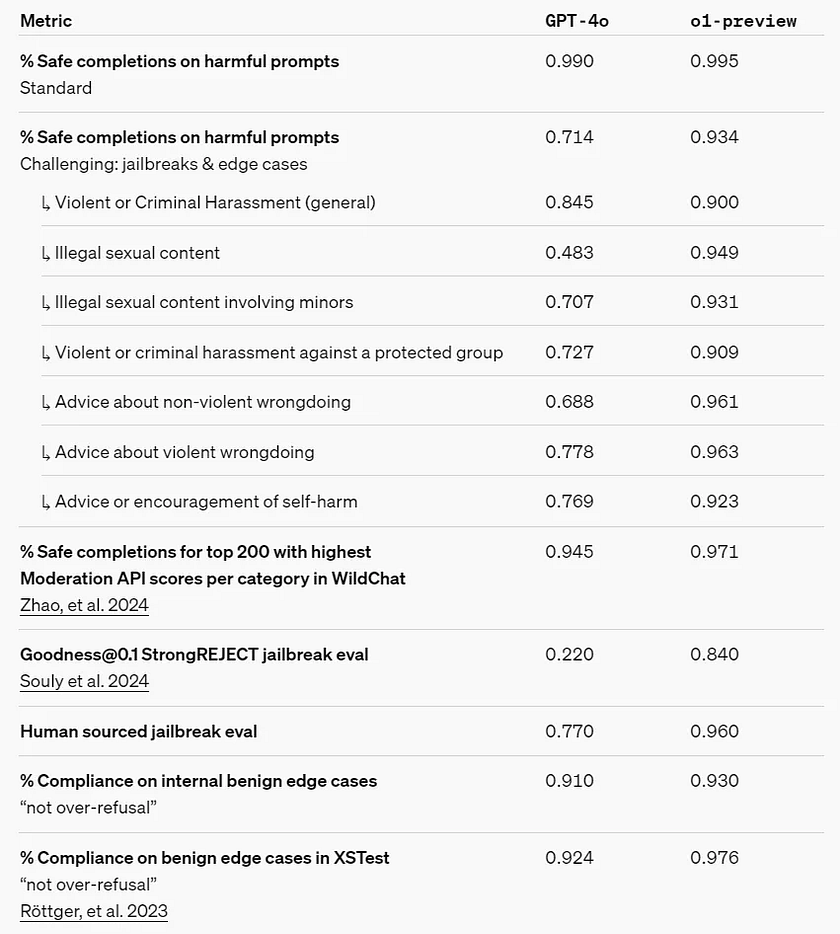
Safety Readiness Framework Link: https://openai.com/safety/
OpenAI o1-mini
o1 is a series of models. OpenAI has also released a mini version, OpenAI o1-mini. The company defined the differences between the preview and mini versions in their blog: “To provide developers with more efficient solutions, we also introduce OpenAI o1-mini, a faster and cheaper reasoning model that excels particularly in programming.” Overall, the cost of o1-mini is 80% lower than that of o1-preview.
Since large language models like o1 are pre-trained on extensive text datasets, they possess broad-world knowledge but may be costly and slow for practical applications.
In contrast, o1-mini is a smaller model optimised for STEM reasoning during pre-training. After being trained using the same high-computation Reinforcement Learning (RL) pipeline as o1, o1-mini achieves comparable performance on many useful reasoning tasks while significantly improving cost efficiency.
For example, in benchmarks that require intelligence and reasoning, o1-mini performs well compared to o1-preview and o1. However, it performs less effectively on tasks that require non-STEM factual knowledge.
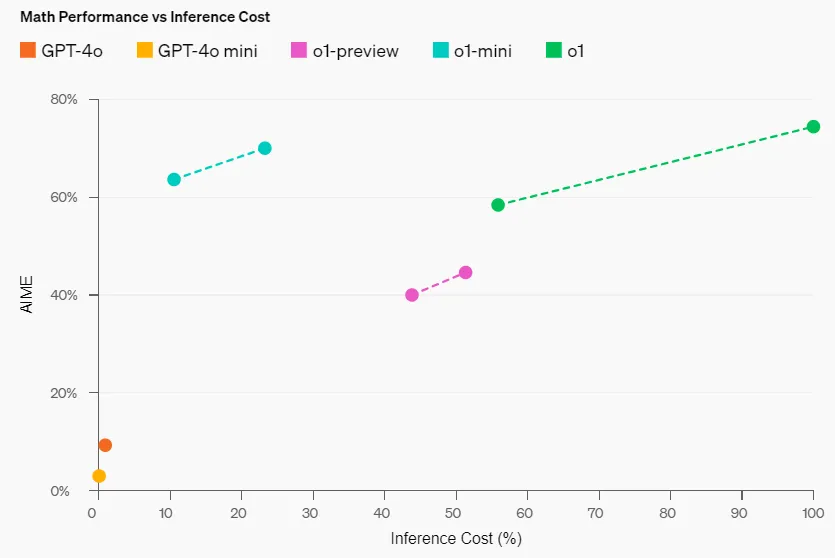
Mathematical Ability: In the high school AIME math competition, o1-mini (70.0%) is almost on par with o1 (74.4%), but at a much lower cost, and it outperforms o1-preview (44.6%). The score of o1-mini (about 11 out of 15 problems) places it approximately among the top 500 high school students in the United States.
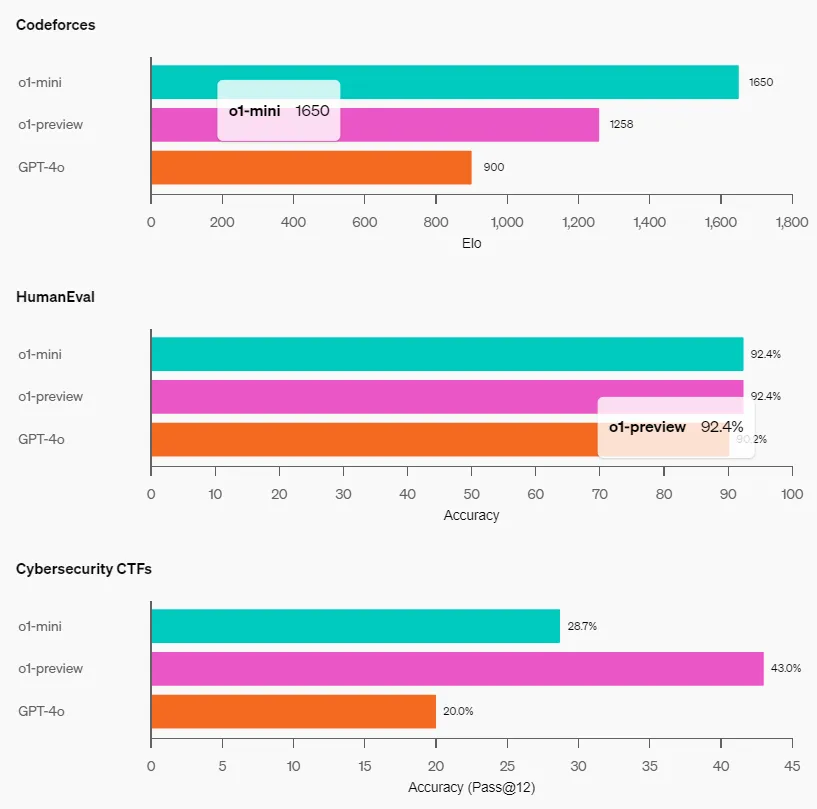
Coding Ability: On the Codeforces competition website, o1-mini has an Elo score of 1650, closely matching o1 (1673) and surpassing o1-preview (1258). Additionally, o1-mini performs well on the HumanEval coding benchmark and high school Capture the Flag (CTF) cybersecurity challenges.
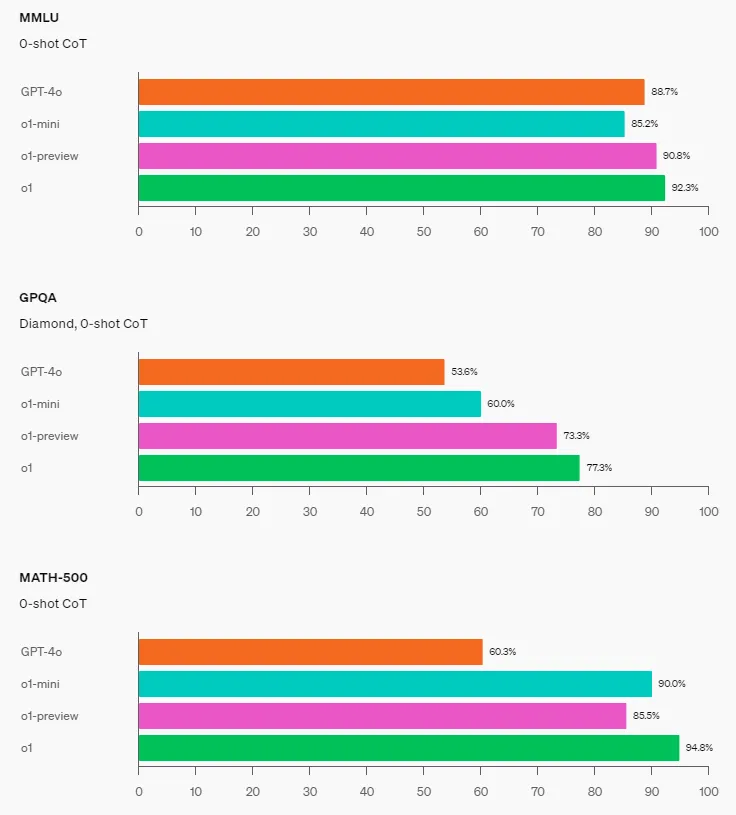
STEM: On certain academic benchmarks requiring reasoning, such as GPQA (Science) and MATH-500, o1-mini outperforms GPT-4o. However, o1-mini performs worse than GPT-4o on tasks like MMLU and lags behind o1-preview on the GPQA benchmark due to its lack of broad world knowledge.
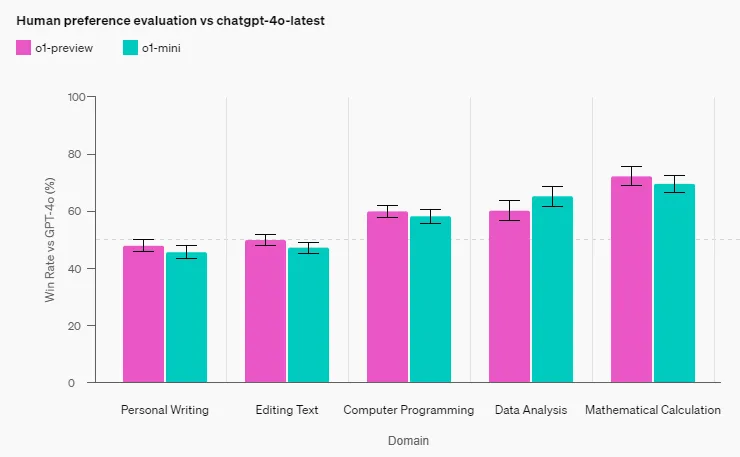
Human Preference Evaluation: OpenAI had human raters compare o1-mini and GPT-4o on challenging open-ended prompts across various domains. Similar to o1-preview, o1-mini was preferred over GPT-4o in reasoning-intensive fields; however, in language-centric areas, o1-mini was not preferred over GPT-4o.
In terms of speed, OpenAI compared GPT-4o, o1-mini, and o1-preview on a word reasoning problem. The results showed that GPT-4o answered incorrectly, while both o1-mini and o1-preview answered correctly, with o1-mini arriving at the answer approximately 3–5 times faster.

Behind these exciting advancements in capabilities, a series of long-speculated technical developments have also been validated.
Chain of Thought (CoT)
Chain of Thought (CoT) is a technique discovered by researchers that enables large models to “think” through difficult problems, significantly improving their accuracy on reasoning tasks. This approach has been refined over the past two years in several seminal papers.
The paper “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, NeurIPS2022” proposed that by manually adding examples of thought processes (Manual CoT) into the prompts before asking LLMs questions, LLMs can significantly improve their performance on reasoning tasks.
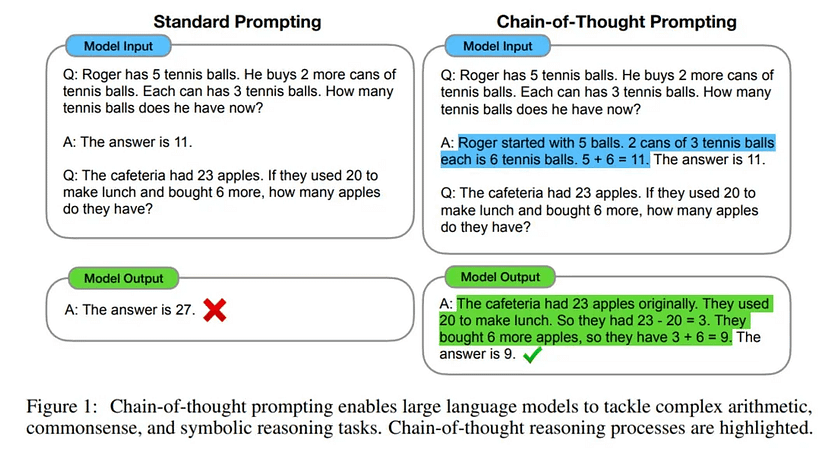
The paper “Large Language Models are Zero-Shot Reasoners, NeurIPS2022” introduced the idea of using prompts like “Let’s think step by step” to encourage the model to generate its own reasoning process (Zero-shot CoT). This approach has also led to the creation of other well-known prompts such as “Let’s take it step by step”.

The paper “Automatic Chain of Thought Prompting in Large Language Models, ICLR2023” can be seen as a combination of the two previous approaches. It first uses the prompt “Let’s think step by step” to generate a reasoning process, and then incorporates these processes into the prompt to guide the model’s reasoning. This method eliminates the need for manual writing while maintaining reliability.
Following these developments, CoT has undergone numerous iterations, but most still rely on prompting to induce step-by-step thinking in large models. This has led people to wonder if it is possible for large models to learn this method on their own.
Reinforcement Learning and Self-Taught Reasoning
Similar to AlphaZero, reinforcement learning is a machine learning method that allows machines to adjust their behaviour strategies by interacting with the environment and observing the results. However, it had been challenging to apply to language models.
This changed in 2022 when Stanford University proposed a method called “Self-Taught Reasoner” (STaR). The approach involves initially providing the model with detailed solutions to some example problems. The model then attempts to solve more problems on its own. If it solves them correctly, the methods are added back to the example set, forming a dataset that is used to fine-tune the original model. This allows the model to learn these methods, representing a classic approach for automatically generating data.
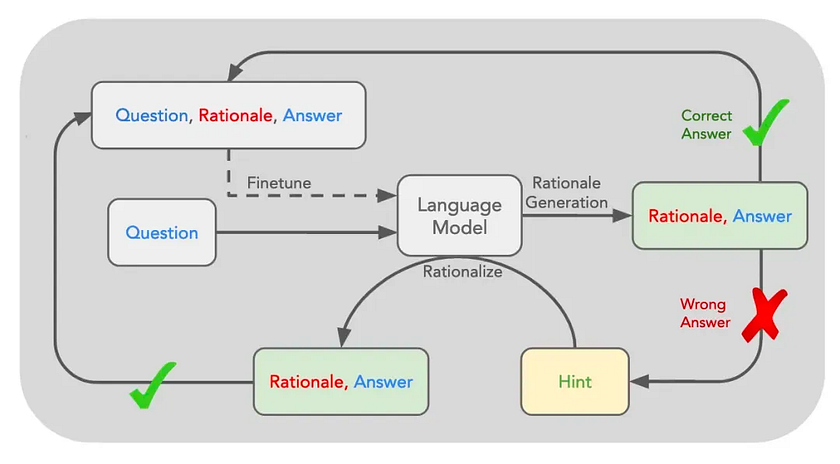
Subsequently, this approach evolved into a new technique known as “Quiet-STaR,” or Q*, which translates roughly to “Quiet Self-Taught Reasoning.” The core idea is to insert a “thinking” step after each input token, allowing the large model to generate internal reasoning. The system then evaluates whether this reasoning helps predict subsequent text and adjusts the model parameters accordingly. This method enables the model to perform implicit reasoning while processing various types of text, not just when answering questions.
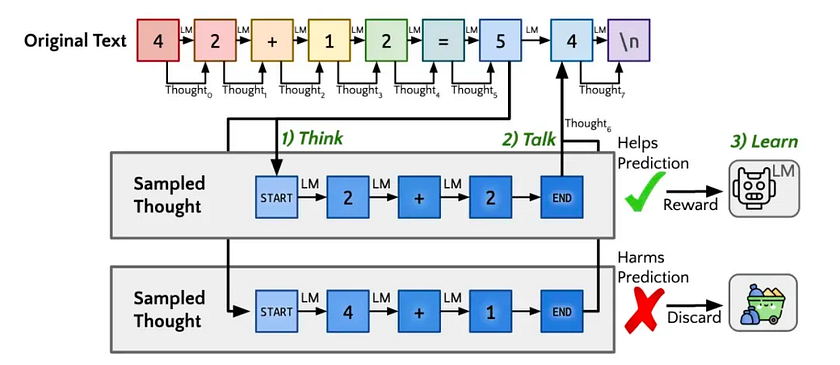
In simpler terms, incorporating reinforcement learning means teaching the large model specific strategies during training (which are, of course, generated and optimised by the model itself). When faced with a problem, the model selects a strategy based on the type of question, breaks it down step by step, and repeatedly reviews the solution. If the chosen strategy doesn’t work, it tries a different one — much like how we teach elementary students problem-solving techniques. However, due to the complexity of the reward model, this self-learning mechanism typically performs better in fields like mathematics and coding.
Extension of Scaling Laws
The combination of the above techniques results in no significant changes during the pre-training phase, but greatly increases computational load during the inference phase. The goal shifts from fast thinking to deliberately slowing down the process to achieve more accurate results.
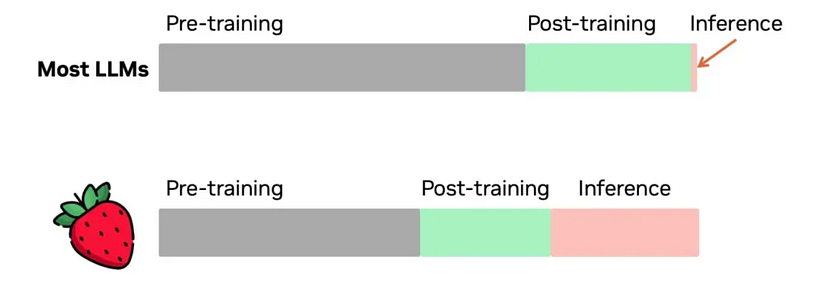
OpenAI mentioned a phenomenon they discovered during training: with more reinforcement learning (training computation) and longer thinking time (inference computation), the performance of their models continues to improve.
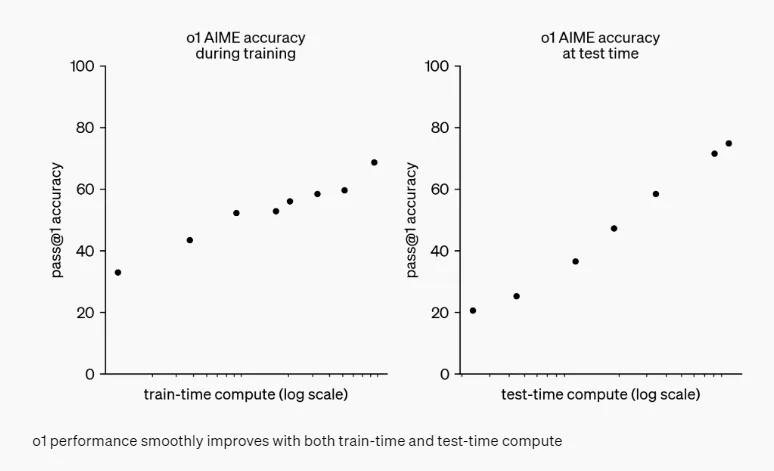
NVIDIA AI leader Jim Fan commented on X about the historical significance of this event: models now have scaling laws not only during training but also during inference. The joint growth of these curves will break through the previous limitations on the capabilities of large models. “Previously, no one could replicate the success of AlphaGo in large models by using more computation to achieve superhuman capabilities. Today, we have turned that page.”
It is foreseeable that against the backdrop of decreasing marginal costs of pre-training, reinforcement learning-based inference enhancement will gain more attention and play a significant role. More computational resources will be devoted to the inference phase, and the global demand for AI chips and computing power will continue to increase.
Tricks
There’s no denying that o1 represents a significant advancement in the field of artificial intelligence. However, a closer look at Altman’s actions over the past year, along with changes in OpenAI’s organizational structure and core team, raises some questions: Is this story perhaps a bit exaggerated? Could it be that a series of small techniques are being used to sustain the company’s valuation and resource acquisition?
1. Technical Barriers
Both Sora and o1 are essentially engineering innovations based on existing research, without particularly high technical barriers. OpenAI’s greatest contribution lies in its resolute and cost-intensive early implementation. Similar to Sora, once OAI has identified a technical direction, engineering replication is likely just a matter of time, and it’s nearly impossible for OAI to outcompete the entire world in all directions. Moreover, based on recent widespread testing, the model’s performance can be described as mediocre at best, often falling short compared to other engineering methods like Claude 3.5’s chain-of-thought approach. In many cases, it feels like a probabilistic lottery with uncertain practical value. Additionally, perhaps to avoid competitors’ espionage and plagiarism, or due to security issues with the open thought process, OpenAI has not made the entire thought chain details available to users. However, researchers have quickly claimed to replicate similar reasoning capabilities.
It’s conceivable that major companies will start focusing on reasoning, rolling out their own “thoughtful” versions of models and quickly levelling the playing field. If OpenAI doesn’t have more substantial breakthroughs, it will be challenging to overcome the current plateau in the model competition.
2. Costs
The model, which was largely completed last year but delayed for so long before release, likely faced this delay not just due to well-known safety reasons but also because o1 and Sora, like their predecessors, have prohibitively high computational costs, making large-scale commercial use unfeasible. Faced with this challenge, Altman’s team has been seeking solutions. They have waited for a long time, hoping that computational costs would decline with technological progress. They have also been raising funds globally to purchase or lease more computing resources. However, despite these efforts, the product still requires several minutes or even tens of minutes for a single inference, costing several times more per token compared to 4.0.
These factors create an awkward situation: the scientific contribution currently far outweighs the commercial value. In this context, maintaining OpenAI’s industry status and valuation becomes quite uncertain. High R&D and operational costs, coupled with commercialisation obstacles, could affect investor confidence and market expectations.
3. Methodology
If the previous two points seem somewhat unfairly critical from a business perspective, then the methodology itself is worth further scrutiny. The claim that this approach reaches or even exceeds “PhD-level” in various STEM fields needs more discussion and validation. Fundamentally, this approach continues to rely on the Scaling Law, adding layers of complexity with brute-force methods like Monte Carlo tree search, which in essence, is using a humanities approach to solve scientific problems. Similar to previous applications like AutoGPT, for complex issues, if the thought chain’s search space isn’t strictly limited and guided, it may lead to vast, aimless exploration, consuming significant computational resources without achieving the desired results.
As mentioned earlier, this method resembles the rote-learning style often used in basic education, relying heavily on memory and pattern matching rather than deep understanding and creative thinking. Even simple questions like comparing 9.11 and 9.8 might be answered incorrectly after much deliberation. AI developed with this method might resemble a “grind student” good at rote learning but lacking true insight and creativity, rather than a “PhD” with genuine innovation and problem-solving skills. After all, training data for rote problem-solving is much easier to obtain.
Indeed, much scientific research involves repetitive and mechanical tasks, and having AI handle these would undoubtedly greatly enhance scientific efficiency. However, the core of research lies in innovation, in exploring unknown questions and discovering new knowledge. This requires inspiration, creativity, and logical reasoning, not just computational power.
As pointed out in the paper “Large Language Monkeys: Scaling Inference Compute,” merely increasing the number of generated samples to expand inference computation does not fundamentally change the nature of large language models; they remain statistical probability-based “monkeys typing.” To truly achieve general artificial intelligence and groundbreaking advances in the scientific field, we may need to seek more fundamental innovations in algorithms and architectures, rather than simply piling on computational power.

Summary and Reflections
We’ve praised and criticised it, but ultimately, I believe these are not the most important aspects of o1. Although it may not appear to be the primary focus for OpenAI, the materials repeatedly highlight a crucial point: o1 is particularly suited for complex problems in fields like science, coding, and mathematics, especially those involving tedious tasks or multi-step inductive or deductive reasoning. For instance, “healthcare researchers can use o1 to annotate cell sequencing data, physicists can use o1 to generate complex mathematical formulas needed for quantum optics, and developers across all fields can use o1 to construct and execute multi-step workflows.”
In the past, we often expected artificial intelligence to be a model that possessed knowledge, intelligence, and even emotions and creativity, leading to ever-increasing model parameters and computational demands. However, perhaps these goals need to be addressed through various methods, some of which might be non-technical. While o1 may indeed enhance the world-understanding capabilities of multimodal models in some way in the future, its core value lies in being a reasoning model significantly decoupled from extensive world knowledge. This is even more apparent in o1-mini, a low-cost, small model particularly adept at programming scenarios that require rigorous multi-step reasoning without extensive world knowledge.
The human learning process involves first acquiring vast amounts of knowledge, forming intelligence through extensive neural activation and connections, while specific knowledge is often forgotten, akin to Zhang Wuji learning Tai Chi. In solving different problems, besides relying on language comprehension and logical reasoning abilities, we also rely on accessing and referencing credible knowledge, the emergence of creative inspiration, and emotional interpersonal connections and empathy. AI will not merely be a large deep learning model but will become an increasingly “sparse” and flexible combination of capabilities, potentially even a new mechanism for human-machine collaboration. The ability to “solve problems” is certainly necessary, but mastering problem-solving is still a considerable distance from addressing real-world issues.
The emergence of o1 might hint at a trend towards such “capability sparsification.” Future AI will evolve from a single large model into a flexible combination of modules for knowledge, reasoning, creativity, and emotions, forming a closer and more efficient collaboration with humans. o1 is just the beginning; we look forward to a flourishing future.
References
- OpenAI (2024b). Introducing OpenAI o1. https://openai.com/index/introducing-openai-o1-preview/.
- Openai.com. (2024b). OpenAI o1-mini. https://openai.com/index/openai-o1-mini-advancing-cost-efficient-reasoning/.
- OpenAI (2024c). Learning to Reason with LLMs. https://openai.com/index/learning-to-reason-with-llms/.
- X (formerly Twitter). (2024b). x.com. https://x.com/sama/status/1834283100639297910.
Catch the latest version of this article over on Medium.com. Hit the button below to join our readers there.






















