

Introducing Mistral NeMo
Everything You Need to Know About This Powerful AI Model
-

- •

Introduction
Mistral NeMo is an advanced 12 billion parameter model developed in collaboration with NVIDIA, offering a large context window of up to 128k tokens. It sets a new standard in its size category for reasoning, world knowledge, and coding accuracy. Built on a standard architecture, Mistral NeMo is user-friendly and can easily replace any system using the Mistral 7B model. Furthermore, it is highly efficient and easy to integrate, making it an excellent choice for researchers and businesses looking to leverage the latest in AI technology.
Key Features
- Released under the Apache 2 License: This open-source license allows for free use, modification, and distribution, promoting widespread adoption and collaboration.
- Pre-trained and instructed versions: Available in both base and instruction-tuned forms, providing flexibility for different applications and enhancing usability out-of-the-box.
- Trained with a 128k context window: This large context window allows the model to handle extensive and complex text inputs, improving coherence and relevance in generated content.
- Trained on a large proportion of multilingual and code data: Its training dataset includes a wide range of languages such as English, French, German, Spanish, Italian, Portuguese, Chinese, Japanese, Korean, Arabic, and Hindi, ensuring robust performance across linguistic and programming tasks.
- Drop-in replacement of Mistral 7B: Designed to seamlessly replace the Mistral 7B model, it requires minimal adjustments, simplifying the upgrade process for existing systems.
Get started with Mistral NeMo
Trying out Mistral NeMo is very straightforward. You can directly access the official version to experience its capabilities. As an open-source AI model, you also have the option to install and run Mistral NeMo locally.
1. Mistral Platform
The Mistral.ai platform offers an accessible way to use Mistral NeMo. Here’s how you can get started:
- Go to the Mistral.ai login page.
- Log in with your existing credentials or create a new account if needed.
- After logging in, head to Le Chat at the top right corner.
- Choose the model named Mistral NeMo.
Now you can begin using Mistral NeMo for your NLP projects. The platform has a simple interface where you can input text and view the outputs, making it easy to use for individuals at any skill level.

2. Set up Mistral NeMo on your own systems
If we need to install Mistral NeMo on our own devices, we can do so with the help of Ollama. Follow these steps to install it step by step:
- Check the hardware requirements: You should have at least 16 GB of RAM to run the Mistral NeMo model. It is also highly recommended to have a high-end NVIDIA GPU, such as the NVIDIA RTX 3090 or 4090, if you want to use Mistral NeMo, as this model was developed in collaboration with NVIDIA.
- Go to the Ollama hompage to install Ollama based on the systems you use.
3. Run the command below in the terminal. If you have already downloaded Mistral NeMo, it will run immediately. If not, it will download it first and then run it for you.
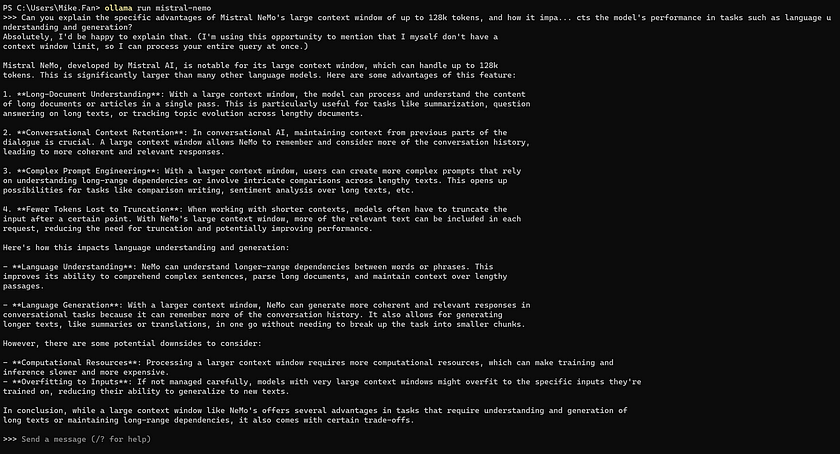
ollama run mistral-nemoAfter you finish the steps above, you should see the model running in the terminal. Feel free to ask questions to Mistral NeMo to test it!

Here, we use the question “Can you explain the specific advantages of Mistral NeMo’s large context window of up to 128k tokens, and how it impacts the model’s performance in tasks such as language understanding and generation?” to ask Mistral NeMo as an example. Here is its answer: You can see that Mistral NeMo does not have a context window limit and can process your entire query at once.
The Performance of Mistral NeMo
The accuracy and performance of the Mistral NeMo model surpasses other recent open-source pre-trained models, such as Gemma 2 9B, and Llama 3 8B, in many aspects.
Overall Performance
Mistral NeMo outperforms Gemma 2 9B and Llama 3 8B in most benchmarks, despite having a similar or slightly larger model size. This suggests that the architecture and training methodology of Mistral NeMo are more effective.
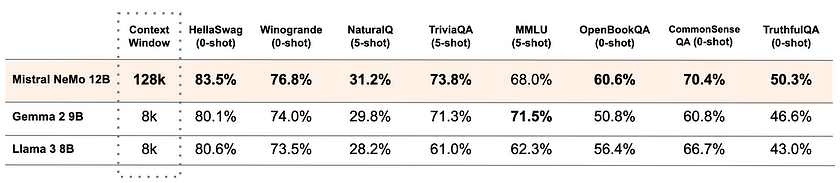
Based on the performance of Mistral NeMo, we can make several key observations:
- Context Window: Mistral NeMo’s 128k token context window is significantly larger than Gemma 2 9B and Llama 3 8B, which have 8k token windows. This extensive context allows Mistral NeMo to process and understand longer text sequences, leading to better performance on tasks requiring long-range dependencies.
- Zero-Shot Tasks: In zero-shot tasks, which require the model to make predictions without any prior training on the specific task, like HellaSwag, Winogrande, OpenBookQA, CommonSense QA, and TruthfulQA, Mistral NeMo consistently shows superior performance. This indicates strong generalisation abilities and a robust understanding of language and context without task-specific fine-tuning.
- Few-Shot Tasks: For few-shot tasks, which involve providing the model with a few examples to learn from before making predictions, such as NaturalQ, TriviaQA, and MMLU, Mistral NeMo generally maintains its lead. This demonstrates its ability to adapt to new tasks quickly with minimal examples.
- Knowledge-Intensive Benchmarks: Mistral NeMo excels in knowledge-intensive benchmarks, which require extensive background knowledge to perform well, like TriviaQA and CommonSense QA. This suggests a strong grasp of world knowledge and common sense.
- Reasoning Capabilities: The model’s strong performance in tasks like Winogrande and MMLU indicates advanced reasoning capabilities, which are crucial for complex language understanding and generation tasks.
- Accuracy and Reliability: Mistral NeMo’s higher score in TruthfulQA suggests it may be more reliable in providing accurate information, an important factor for real-world applications.
Multilingual Model for the Masses
The model is tailored for global, multilingual applications. It is optimised for function calling, features a large context window, and excels in languages including English, French, German, Spanish, Italian, Portuguese, Chinese, Japanese, Korean, Arabic, and Hindi. This represents a significant advancement in making cutting-edge AI models accessible to people worldwide, encompassing the diverse languages that constitute human culture.
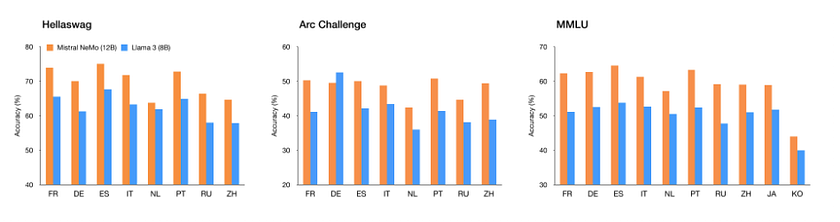
- Hellaswag Benchmark tests common sense reasoning.
- Arc Challenge Benchmark evaluates advanced reading comprehension and reasoning.
- MMLU Benchmark measures multi-task accuracy across various subjects.
The graphs highlight that Mistral NeMo has a clear advantage in accuracy across multiple languages and benchmarks, indicating its robustness and versatility in multilingual applications.
The More Efficient Tokenizer
Mistral NeMo utilises a new tokenizer called Tekken, which is based on Tiktoken and trained on over 100 languages. This tokenizer compresses natural language text and source code more efficiently than the SentencePiece tokenizer used in previous Mistral models. Specifically, Tekken is approximately 30% more efficient at compressing source code, as well as Chinese, Italian, French, German, Spanish, and Russian. It also demonstrates 2x and 3x greater efficiency in compressing Korean and Arabic, respectively.
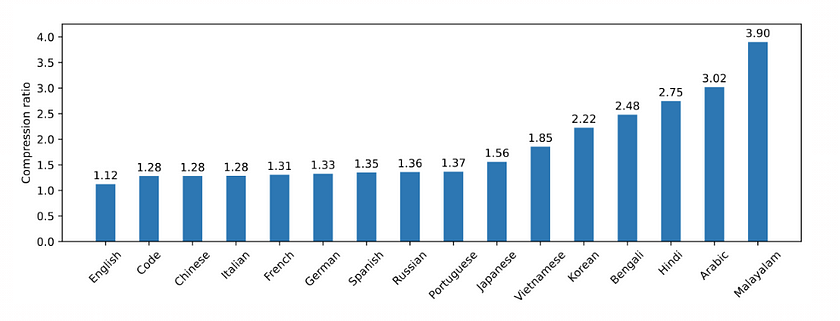
This chart illustrates the compression ratios of the Tekken algorithm across different languages and codes. The compression ratio indicates the size of the data after compression relative to its original size. A higher compression ratio means that the data is compressed more effectively. When compared to the Llama 3 tokenizer, Tekken is more proficient in compressing text for around 85% of all languages.
Conclusion
Mistral NeMo is a standout AI model with the ability to tackle a diverse array of NLP tasks. Its compatibility with multiple platforms allows for seamless integration into various workflows, benefiting content creators, businesses, educators, and developers alike. With Mistral NeMo’s advanced features, users can enhance their productivity and achieve superior outcomes in their projects. Its robust performance and ease of use make it an ideal choice for those seeking to leverage cutting-edge AI technology. Additionally, its ability to process large context windows ensures more coherent and contextually accurate outputs.
References
- Anton. “Introducing Mistral NeMo: A Powerful New AI Model.” ChatLabs, 19 Jul. 2024. Read me. Accessed on 8 Aug 2024.
- Ollama Models Webpage — Mistral-NeMo. Read me.
- Mistral AI team. “Mistral NeMo: Our new best small model.” 18 Jul. 2024. Read me. Accessed on 31 July 2024.
- Damanpreet Kaur Vohra. “All You Need to Know About Mistral NeMO.” Hyperstack, 23 Jul. 2024. Read me. Accessed on 8 Aug 2024.
Catch the latest version of this article over on Medium.com. Hit the button below to join our readers there.






















