


Introduction to GLUE Benchmark
Let’s explore the GLUE benchmark!
-

- •

Introduction
As the demand for more intelligent natural language processing (NLP) systems grows, researchers have developed benchmarks to assess the capabilities of these models across a wide range of linguistic tasks. The General Language Understanding Evaluation (GLUE) benchmark is one of the most influential benchmarks created to address this need. It provides a standardised platform for evaluating the performance of NLP models on a variety of tasks that reflect real-world language understanding challenges.
GLUE consists of:
- A suite of nine diverse tasks based on established datasets, designed to span a range of dataset sizes, text genres, and difficulty levels.
- A diagnostic dataset that tests models across different linguistic phenomena to uncover strengths and weaknesses.
- A public leaderboard and dashboard that tracks and visualises model performance.
The benchmark is model-agnostic, welcoming any system capable of processing sentences or sentence pairs and generating predictions. By selecting tasks that encourage cross-task information sharing through techniques like parameter sharing or transfer learning, GLUE aims to promote the development of robust, general-purpose NLP systems. Its ultimate goal is to push the boundaries of natural language understanding and drive research towards models that can handle diverse linguistic contexts with greater generalisation.
Overview of GLUE Benchmark
The GLUE benchmark is widely used to assess how well models understand and process natural language. It includes 10 tasks, each focusing on different aspects of language comprehension:
CoLA (Corpus of Linguistic Acceptability): This task tests a model’s ability to predict whether a sentence is grammatically acceptable. It challenges models to go beyond surface-level understanding and grasp deeper syntactic rules in language.
Example:
- Input:
The cat on the mat. - Output:
1(The sentence is grammatically correct) - Input:
On the mat cat the. - Output:
0(The sentence is grammatically incorrect)
SST-2 (Stanford Sentiment Treebank): Here, the goal is to predict the sentiment (positive or negative) of a given sentence. This task evaluates a model’s ability to understand nuanced emotional tones in text, which is crucial for applications like opinion mining and sentiment analysis.
Example:
- Input:
This movie was absolutely wonderful! - Output:
1(Positive sentiment) - Input:
The film was incredibly boring. - Output:
0(Negative sentiment)
MRPC (Microsoft Research Paraphrase Corpus): This task asks models to determine if two sentences are paraphrases, meaning they convey the same meaning. It’s a test of semantic similarity, often useful for tasks like text deduplication or summarization.
Example:
- Input:
He is a teacher.andHe teaches students. - Output:
1(The sentences are paraphrases) - Input:
She loves dogs.andShe hates dogs. - Output:
0(The sentences are not paraphrases)
QQP (Quora Question Pairs): Similar to MRPC, this task requires models to identify whether two questions from Quora are semantically equivalent. It emphasizes the importance of detecting similar intent in different phrasings — a challenge in tasks such as question answering and chatbot development.
Example:
- Input:
What is the capital of France?andWhich city is the capital of France? - Output:
1(The questions have the same meaning) - Input:
What is the capital of France?andHow big is France? - Output:
0(The questions have different meanings)
MNLI (Multi-Genre Natural Language Inference): In this task, models must predict the relationship between a premise and a hypothesis across multiple genres of text. The relationship can be entailment (the premise supports the hypothesis), contradiction, or neutral. This broad task evaluates a model’s general inference capabilities across a diverse set of real-world genres.
Example:
- Premise:
The man is driving a car. - Hypothesis:
The man is traveling by vehicle. - Output:
Entailment(The hypothesis follows from the premise) - Premise:
The man is driving a car. - Hypothesis:
The man is flying an airplane. - Output:
Contradiction(The hypothesis contradicts the premise)
QNLI (Question-answering Natural Language Inference): This task is a reformulation of the Stanford Question Answering Dataset (SQuAD), where the model must decide if the answer to a given question is contained within a provided context sentence. It helps assess a model’s understanding of question-answer relations and factual consistency.
Example:
- Question:
What is the capital of France? - Context:
Paris is the capital of France. - Output:
Entailment(The context answers the question) - Question:
What is the capital of France? - Context:
London is the capital of the UK. - Output:
Not Entailment(The context doesn’t answer the question)
RTE (Recognizing Textual Entailment): Models are asked to predict whether one sentence entails another. This is a simplified version of the NLI task and tests the core reasoning abilities of a model, often based on short text pairs.
Example:
- Input:
The company CEO resigned.andThe CEO of the company has left. - Output:
1(Entailment) - Input:
The company CEO resigned.andThe CEO of the company is still in position. - Output:
0(Not Entailment)
WNLI (Winograd Natural Language Inference): This is a challenging task involving pronoun resolution in complex sentences. Models must determine whether a sentence with a substituted pronoun logically follows from an original sentence. It tests a model’s understanding of coreference resolution, a difficult area in language processing.
Example:
- Input:
The trophy didn’t fit in the suitcase because it was too small. - Output:
Itrefers tosuitcase - Input:
The trophy didn’t fit in the suitcase because it was too big. - Output:
Itrefers totrophy
AX (Diagnostics Main): A diagnostic dataset that helps evaluate model performance across different linguistic phenomena, such as lexical semantics, predicate-argument structure, and logical forms. This task offers insight into specific strengths and weaknesses in a model’s understanding of natural language inference.
Example:
- Input:
The cat sat on the mat.andThe animal rested on the rug. - Diagnostic Assessment: Evaluates model performance in lexical semantics, e.g., understanding that
catandanimalare related.
STS-B (Semantic Textual Similarity Benchmark): This task requires models to predict a similarity score (from 1 to 5) between two sentences, based on their meaning. It tests a model’s ability to assess fine-grained semantic similarity, a key aspect of tasks like text summarization or document retrieval.
Example:
- Input:
A man is playing a guitar.andA person is strumming a musical instrument. - Output:
4.8(High semantic similarity) - Input:
A man is playing a guitar.andA cat is sitting on a chair. - Output:
1.0(No semantic similarity)

These tasks include datasets split into training, validation, and testing sets, except for MNLI and AX, which share the same training set. By covering a wide range of language understanding challenges, GLUE provides a comprehensive evaluation of a model’s ability to generalise across various linguistic phenomena.
Comparing the Performance of Open-source Models on GLUE
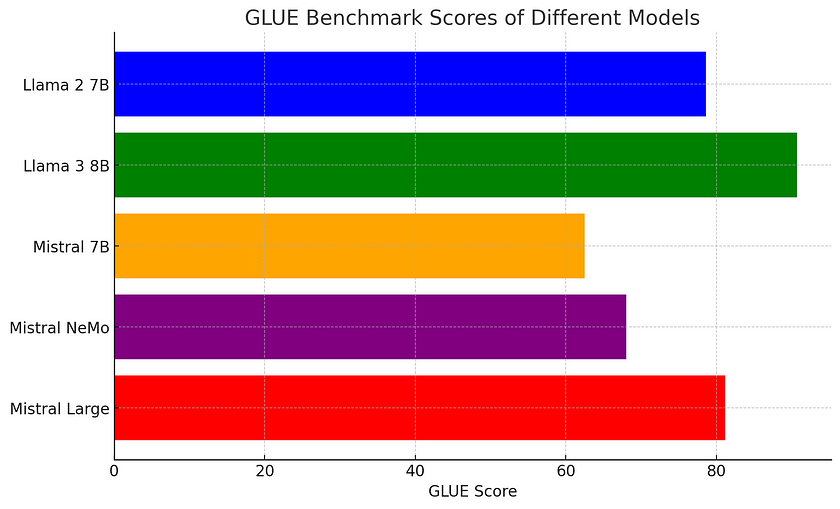
In this section, we will compare the GLUE benchmark scores of several well-known language models, specifically Llama 2 7B, Llama 3 8B, Mistral 7B, Mistral NeMo, and Mistral Large. Due to the memory and performance limitations of my computer, I couldn’t run the benchmarks locally, so the following scores are based on available data from online resources.
The GLUE scores for these models are as follows:
- Llama 2 7B: 78.6
- Llama 3 8B: 90.7
- Mistral 7B: 62.5
- Mistral NeMo: 68
- Mistral Large: 81.2
Despite the larger parameter count of the Mistral models, particularly Mistral Large, the Llama models consistently outperform them on the GLUE benchmark. This is likely due to the Llama models being more finely tuned for the types of tasks included in GLUE, such as natural language inference and sentiment analysis. In contrast, the Mistral models, while powerful, may be designed for more general-purpose tasks and lack the same level of task-specific optimisation. Additionally, architectural improvements in the Llama series, such as better data preprocessing and advanced fine-tuning techniques, allow them to maximise their performance even with fewer parameters.
Thus, although Mistral Large has more parameters, Llama models demonstrate that efficiency and specific task fine-tuning can often outperform sheer size when it comes to benchmarks like GLUE.
Conclusion
The GLUE benchmark has become a vital tool for evaluating the performance of NLP models across a diverse range of language understanding tasks. By assessing models on tasks such as sentiment analysis, textual entailment, and paraphrase detection, GLUE provides a comprehensive view of a model’s generalisation abilities. From the comparison of several open-source models like Llama 2 7B, Llama 3 8B, Mistral 7B, Mistral NeMo, and Mistral Large, it’s evident that model size alone does not guarantee superior performance. Ultimately, the GLUE benchmark highlights the importance of task-specific optimisation and efficient model design. Researchers and practitioners must consider not only the size of a model but also its ability to generalise across diverse language tasks when evaluating and selecting models for practical applications.
References
- Chen Qian. “Evaluate Your Model with GLUE Benchmark”. Medium, 5 Jan. 2023. Read me). Accessed on 3 Oct 2024.
- Hugging Face Webpage — Metric: glue Read me.
- Chen Qian. “GLUE-Benchmarking-Guide”. Github, 5 Jan. 2023. Read me. Accessed on 3 Oct 2024.
- Wang, A., Singh, A., Michael, J., Hill, F., Levy, O., & Bowman, S.R. “GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding”. ICLR, 2019. Read me. Accessed on 3 Oct 2024.
Catch the latest version of this article over on Medium.com. Hit the button below to join our readers there.






















