


Mini RAG using Neo4j
Unveiling the Potential of Neo4j and Retrieval-Augmented Generation
-

- •



Introduction
Knowledge graphs, which offer a structured representation of data and its relationships, are revolutionising how we organise and access information. With large amounts of data, it sometimes becomes difficult to draw insights from it. This blog article examines how to combine Neo4j, a graph database, with OpenAI’s Retrieval-Augmented Generation (RAG) model to build a robust knowledge management system.
Large Language Models (LLMs) are pre-trained models and generate outputs based on the prompts we pass them. Sometimes, the LLM results are precisely what you need, but other times, they just return random facts from their training data. Retrieval-augmented generation (RAG) is an AI framework that tries to improve the response of the LLM models by providing context knowledge from external sources. Additional benefits of RAG include:
- Enables getting insights into private data without sharing or using it for training.
- Reduces the chances of ‘Hallucination’ and incorrect responses.
- Reduces the need to train the model on new data continuously.
Sample Data
For our exercise, we will use OpenAI, combined with the Australian National Graph Database, to create an RAG pipeline.
The Australian National Graph Database is a vast knowledge graph with around 11 million nodes. We can’t possibly fit all the data into the OpenAI context. So, in the first phase, we will retrieve a subset of the graph and then use this graph as a context for the OpenAI and to answer prompts.
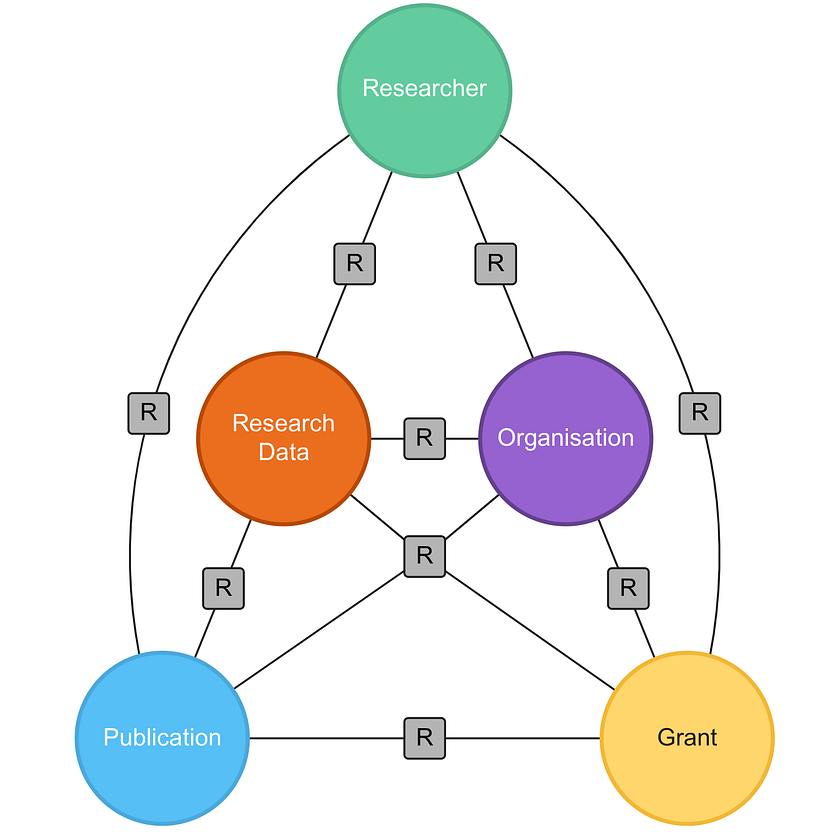
We use a Virtual Machine (VM) with a Neo4j server running the graph database as a Neo4j server. The graph schema includes five primary node types that describe the research ecosystem: Researchers, Publications, Datasets, Grants and Organisations.
Step 1
Firstly, we must establish the connection to the Neo4j database. Also, you might notice that we use an OpenAI API key. This key can be generated at the OpenAI portal. A tutorial is available here.
import os
import json
import pandas as pd
import configparser
from neo4j import GraphDatabase
config = configparser.ConfigParser()
config.read('config.ini')
# Set the OpenAI API key env variable manually
os.environ["OPENAI_API_KEY"] = config['DEFAULT']['openai-key']
# DB credentials
url = config['DEFAULT']['url']
username = config['DEFAULT']['username']
password = config['DEFAULT']['password']Step 2
We get a subset of the graph from the larger dataset by querying Neo4j. The output of the graph is retrieved in JSON format.
def run_query(cypher_query):
with GraphDatabase.driver(url, auth=(username, password)) as driver:
with driver.session() as session:
result = session.run(cypher_query)
return result.data()
cypher_query = """
MATCH (n:organisation)-[r]-(g:grant)
where g.source='arc.gov.au' RETURN * LIMIT 100
"""
result = run_query(cypher_query)Note: We have used a limit of 100 nodes in the response to limit the size of the returning JSON file. This would impact the LLM functionality if it exceeds the context window size.
We create a system prompt by providing background knowledge about the graph database and the task. Along with it, we pass the JSON subgraph as context.
system_prompt = f'''
You are a helpful agent designed to fetch information from a graph database.
Data
{json.dumps(result)}
This is the output of the Neo4j cypher which returns nodes and relationships. n is the organisations, g is the grants
and r is the relationships between the grants and organisations.
Based on this data answer the user prompts and return the output as json.
'''
Users can then enter the prompt to get insights from the subgraph. For example, in the prompt below, we are trying to find the grant with the most relationship to organisations.
prompt = "Help me find the grants which is related to the most organisations"Step 3
We pass the system and user prompts to the OpenAI model. In this case, we use “gpt-4–1106-preview”. More information is available on the OpenAI page on Models.
from openai import OpenAI
client = OpenAI()
def define_query(prompt, model="gpt-4-1106-preview"):
completion = client.chat.completions.create(
model=model,
temperature=0,
response_format= {
"type": "json_object"
},
messages=[
{
"role": "system",
"content": system_prompt
},
{
"role": "user",
"content": prompt
}
]
)
return completion.choices[0].message.contentOpenAI provides the grant details with the most connections to organisations as a JSON output.
print(define_query(prompt))Output
This is the output provided by OpenAI RAG.
{
"grants": [
{
"arc_for_primary": "1117",
"local_id": "LP200301123",
"start_year": "2023",
"purl": "http://purl.org/au-research/grants/arc/LP200301123",
"source": "arc.gov.au",
"type": "grant",
"arc_scheme_name": "Linkage Projects",
"title": "Making Australia resilient to airborne infection transmission.",
"arc_announcement_administering_organisation": "Queensland University of Technology",
"url": "http://dataportal.arc.gov.au/NCGP/API/grants/LP200301123",
"arc_funding_at_announcement": "898013",
"arc_grant_status": "Active",
"arc_for": "040101,1117,111705,120404",
"r_number": "158880661",
"end_year": "2026",
"participant_list": "Lidia Morawska,Duzgun Agdas,Laurie Buys,Keith Grimwood,Graham Johnson,Guy Marks,Alexander Paz,Thomas Rainey,Zoran Ristovski,Kirsten Spann,Bo Xia,Patrick Chambers,Shaun Clough,Stephen Corbett,Charles dePuthod,Neal Durant,Travis Kline,Peter McGarry,Ross Mensforth,Clive Paige,John Penny,Brad Prezant,Uma Rajappa,David Ward,Scott Bell,Giorgio Buonanno,Mark Jermy,Jose Jimenez,Claire Wainwright,Sandra Glaister,greg Bell,Louisa O'Toole",
"key": "arc/LP200301123",
"related_organisations_count": 24
}
]
}We can compare it visually with the graph from Neo4j and see that RAG provided the correct output.

We have tested this mini pipeline with other examples, and the simplicity of the pipeline makes it functional as long as the size of the subgraph produced in Step 2 does not exceed the context window of the OpenAI model.
Conclusion
The integration of OpenAI RAG and Neo4j paves the way for innovative solutions in knowledge graph applications, and recommendation systems. RAG is efficient in grounding the LLM on the most recent data, and verified information and reduces the expense of retraining the model when new data is available.




















