

Mistral Models vs. Competitors: A Performance Showdown Across NLP, Code, and Multilingual Tasks
Discover the Power of Mistral Models Today
-

- •

Introduction
The Mistral AI models, developed by Mistral AI, are open-source, large language models designed to handle a variety of NLP tasks. These models stand out for their transparency, portability, and ease of customisation, making them flexible and adaptable to different user needs. They are user-friendly, cost-effective, and require less computational power, which makes them suitable for deployment on local systems. Popular versions of these models include Mistral 7B, Mistral NeMo, and Mistral Large, each offering unique capabilities and advantages for specific applications.
In our previous articles, we have provided a detailed overview of Mistral models and their installation methods, you can find more details using the links below:
Running Mistral Models with Hugging Face or Ollama: A detailed introduction to the different models under Mistral AI and their distinctions, along with step-by-step instructions on how to install and use them.
Introducing Mistral NeMo: It focuses on the Mistral NeMo model and its usage details.
Building up on that foundation, this introduction will explore the differences in performance and results between Mistral models and other competing models in the field of NLP. By doing so, we aim to highlight why Mistral models are often our preferred choice and what advantages they offer compared to other models. This will also help you understand the specific advantages and disadvantages of Mistral Models.
Mistral 7B: Performance Benchmarks and Real-World Examples
Benchmarks
The provided figures illustrate the performance benchmarks of the Mistral 7B model compared to other popular models, such as LLaMA 2 (7B and 13B), Code LLaMA 7B, and LLaMA 1 34B, across a range of NLP tasks.

The first figure shows a detailed comparison of these models’ accuracies on various benchmarks, including common sense and reasoning (HellaSwag, WinoGrande, PIQA), scientific reasoning (Arc-e, Arc-c), knowledge and QA (NQ, TriviaQA), code understanding (HumanEval, MBPP), and math & logic (MATH, GSM8K). Mistral 7B demonstrates competitive results, particularly excelling in benchmarks like HellaSwag, PIQA, Arc-e, HumanEval, and GSM8K, showing its versatility in different types of tasks.

The second figure provides a more aggregated view of the models’ performance across broader categories such as MMLU, Knowledge, Reasoning, Comprehension, AGI Eval, Math, BBH, and Code. Mistral 7B consistently outperforms or matches the performance of larger models like LLaMA 2 13B and LLaMA 1 34B in several categories, indicating its efficiency and effectiveness despite having fewer parameters. These results highlight Mistral 7B’s strong capabilities across a wide range of NLP tasks and its potential as a preferred choice for various applications due to its balanced performance and efficiency.
Example
From the figures above, we can see that Mistral 7B significantly outperforms the LLaMA series models in solving math problems. To illustrate this further, we present a real-world math problem and compare the answers generated by the LLaMA 2 8B model and the Mistral 7B model. This comparison will help us explore the differences in their performance and reasoning capabilities when tackling mathematical challenges. Question: A train leaves New York travelling at a constant speed of 60 miles per hour. Another train leaves Chicago traveling at a constant speed of 80 miles per hour, heading towards New York. They are 1,600 miles apart. How many hours will it take for the two trains to meet?

It is not hard to determine that the correct answer is T = 1600 / (60 + 80) = 11.43 hours. Now, let’s see what answers our models will provide. Answer from LLaMA 2 7B:
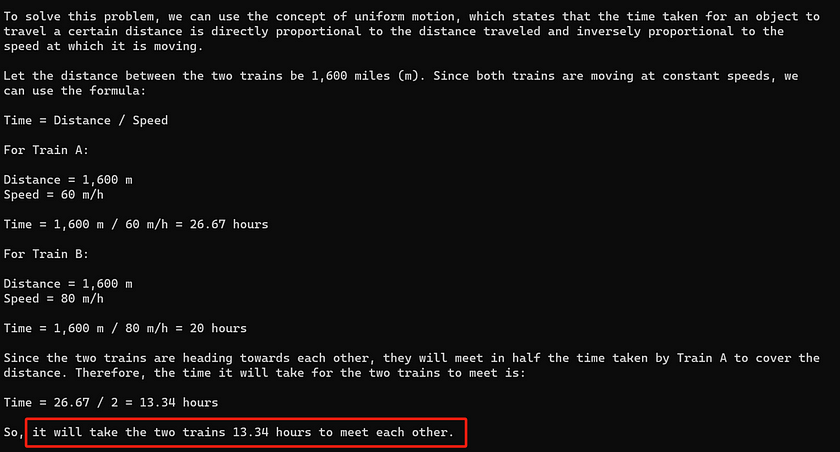
Answer from Mistral 7B:
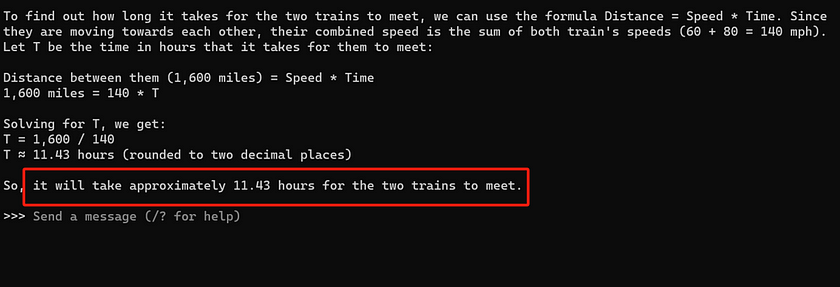
The response from the LLaMA 2 7B model demonstrates a highly disorganised mathematical logic, with many of the equations used being entirely nonsensical and leading to an incorrect answer. In contrast, the Mistral 7B model provides a much shorter response, but its logic is very clear, and the answer is entirely accurate. This highlights the superior ability of Mistral 7B to reason through mathematical problems in a more coherent and effective manner.
Mistral NeMo: Performance Benchmarks and Real-World Examples
Benchmarks 1

The table shows that Mistral NeMo 12B outperforms other models, such as Gemma 2 9B and LLaMA 3 8B, across various benchmarks, including common sense reasoning (HellaSwag: 83.5%), question answering (TriviaQA: 73.8%), and advanced knowledge (CommonSenseQA: 70.4%). With a much larger context window (128k vs. 8k), Mistral NeMo 12B handles complex tasks more effectively, providing clearer and more accurate responses, making it a superior choice for diverse NLP applications.
Example 1
While it is evident that Mistral NeMo often outperforms other competing models in many benchmarks, the differences in scores are not always substantial. This means that, in most cases, the output quality between the models is quite similar. However, there are certain instances where a noticeable difference in quality can be observed. Here is an example: Question: Explain the concept of “photosynthesis” in one or two simple sentences, using an analogy to make it easier to understand. Answer from LLaMA 3 8B:

Answer from Mistral NeMo:

When asked to explain “photosynthesis” using an analogy, LLaMA 3 and Mistral NeMo provide noticeably different responses. LLaMA 3’s analogy, comparing photosynthesis to a bakery using yeast to rise dough, is confusing and misleading because it inaccurately equates sunlight with yeast and suggests processes that are fundamentally different. This can easily confuse users. In contrast, Mistral NeMo compares photosynthesis to a plant “making its own breakfast,” using sunlight, water, and carbon dioxide to produce glucose and oxygen. This analogy is simple and accurate, making the concept easy to understand. Creating effective analogies is more challenging than straightforward explanations, and Mistral NeMo demonstrates a better ability to convey complex ideas clearly.
Benchmarks 2
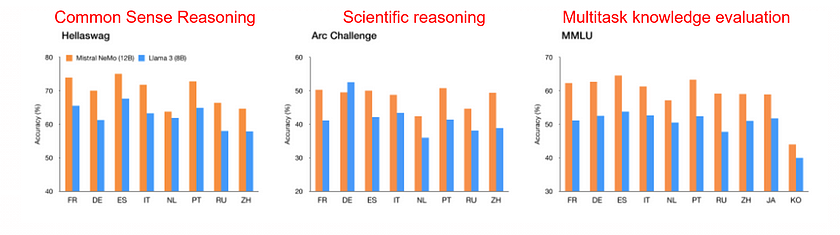
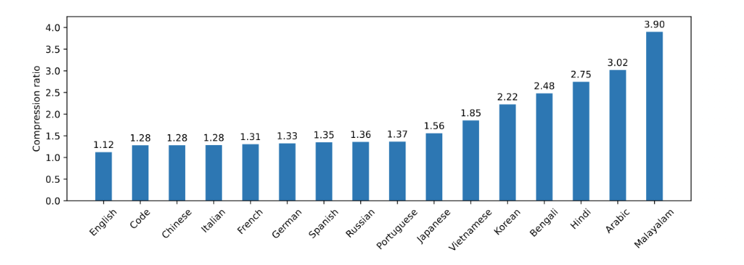
The first chart shows that Mistral NeMo 12B consistently outperforms LLaMA 3 8B across various languages in tasks involving common sense reasoning (HellaSwag), scientific reasoning (Arc Challenge), and multitask knowledge evaluation (MMLU). This highlights Mistral NeMo’s superior multilingual capabilities. The second chart further supports this by illustrating Mistral NeMo’s effective compression ratio across different languages, maintaining a low ratio for many, indicating efficient processing and understanding. These results demonstrate Mistral NeMo’s strong ability to handle diverse languages effectively.
Example 2
Referring to the second chart (Tekken Compression Rate), which shows languages arranged from left to right based on decreasing model proficiency, we chose Chinese, Spanish, and Japanese — three languages where the model’s performance varies. We asked about the same train collision problem in these three languages to see how well Mistral NeMo handles multilingual tasks. This approach allows us to explore Mistral NeMo’s practical performance in multilingual processing. Answer in Chinese:

Answer in Spanish:
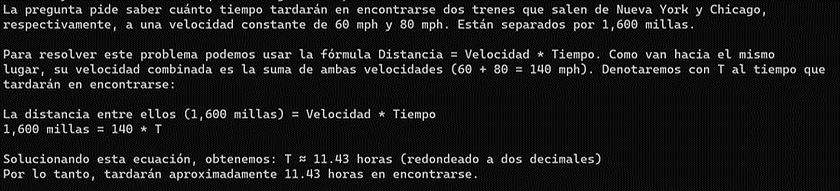
Answer in Japanese:
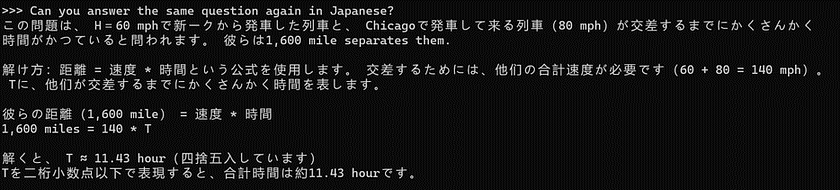
Comparing the responses in these three languages, the quality of the answers in Chinese and Spanish is relatively good. However, the quality in Japanese is notably lower, with a mix of Japanese and English appearing in the answers. This observation highlights that the model does not perform well across all languages, so it’s important to choose languages that Mistral NeMo excels at when using it for multilingual tasks.
Mistral Large: Performance Benchmarks and Real-World Examples
Benchmarks
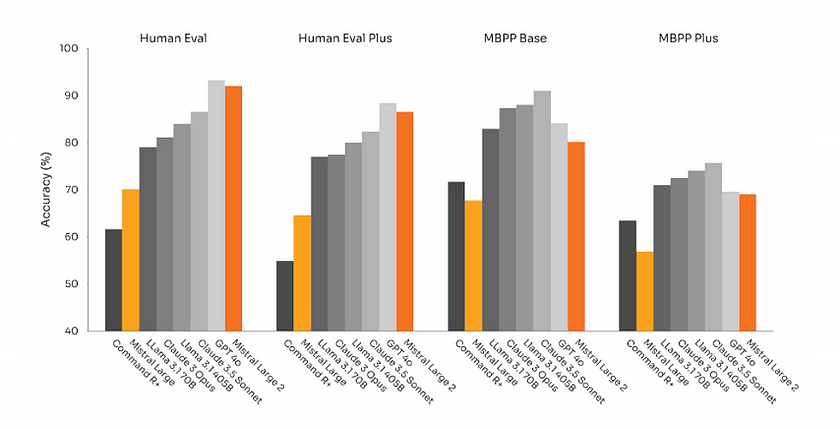
The chart below shows that Mistral Large, as a large-scale model, demonstrates strong capabilities in code generation tasks across various benchmarks, such as Human Eval, Human Eval Plus, MBPP Base, and MBPP Plus. Its performance is competitive, reaching accuracy levels comparable to flagship models like ChatGPT-4o and others on the market. This highlights Mistral Large’s effectiveness and robustness in handling complex coding challenges, positioning it as a formidable alternative to leading models in the field.
Example
Here, we use a prompt: “Write a Python Tetris game,” and have both ChatGPT-4o and Mistral Large 2 complete this task.
Responses from ChatGPT-4o (left) and Mistral Large (right):
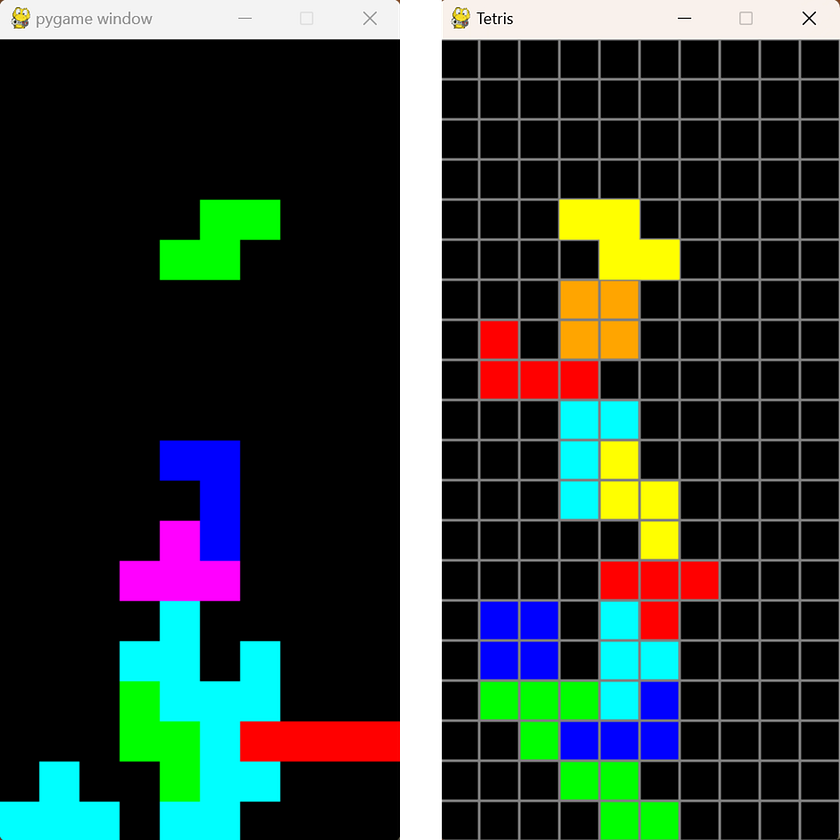
Comparing the Tetris games generated by ChatGPT-4o and Mistral Large, both models deliver visually similar outputs, with Mistral Large’s UI even appearing slightly more polished. This comparison highlights a key point: Mistral Large, an open-source and freely available model, can achieve results on par with commercial software like ChatGPT. This makes it an excellent choice for developers looking for powerful, cost-effective AI tools without sacrificing quality. The fact that Mistral Large is both accessible and capable showcases its potential as a strong alternative in the AI development landscape, providing robust solutions for coding and other tasks.
Build ChatGPT on Your System Using Mistral Models
Next, I will provide an example of how to use Mistral NeMo to build your own ChatGPT-like AI assistant directly on your machine. This AI assistant does not require an internet connection, meaning it can serve you no matter where you are. We will use Mistral NeMo as our AI model and Chainlit to provide a UI input interface. For a detailed step-by-step guide on installing Mistral NeMo, please refer to the recommended articles linked at the beginning of this article.
Steps
- Create a Python file in your folder
- Run
pip install chainlitto install Chainlit - Write the code
- Run
chainlit run test.py -wto start the application
Code Script
import chainlit as cl
import asyncio
# Define the function to run Mistral NeMo
async def run_mistral_nemo(user_input):
print("Running Mistral NeMo with input:", user_input)
process = await asyncio.create_subprocess_exec(
"ollama", "run", "mistral-nemo", user_input,
stdout=asyncio.subprocess.PIPE,
stderr=asyncio.subprocess.PIPE,
)
stdout, stderr = await process.communicate()
if process.returncode == 0 and stdout:
output = stdout.decode('utf-8')
filtered_output = "\n".join(line for line in output.splitlines() if "failed to get console mode" not in line)
return filtered_output.strip()
else:
raise Exception(f"Failed to run Mistral NeMo: {stderr.decode('utf-8').strip()}")
@cl.on_message
async def main(message: cl.Message):
# Get user input
user_input = message.content
# Generate response using the local Mistral NeMo model
try:
generated_text = await run_mistral_nemo(user_input)
except Exception as e:
generated_text = str(e)
# Send the generated response back to the user
await cl.Message(
content=generated_text,
).send()Here’s what our demo looks like

The implementation of this personal AI assistant reminds me of JARVIS from Iron Man. With the rapid advancement of technology, we may soon be able to run highly sophisticated models on portable devices like smartphones. At that point, AI could handle many daily tasks or provide valuable suggestions, allowing humans to focus more on decision-making rather than execution. Imagine a world where everyone has their own powerful, offline AI companion, seamlessly integrating into daily life — whether for work, creativity, or personal growth. This future could redefine productivity, enabling us to leverage AI’s potential to its fullest and transform the way we live and work.
Conclusion
In this article, we explored the potential of Mistral AI models, including Mistral 7B, NeMo, and Large, comparing their performance with other leading models like LLaMA and ChatGPT across various benchmarks. We demonstrated the Mistral models’ effectiveness in NLP tasks, code generation, and multilingual processing. Additionally, we showed how Mistral NeMo can be used to create a personalised, offline AI assistant on your device, highlighting the versatility and accessibility of these open-source models. As AI technology continues to advance, Mistral models provide a powerful and cost-effective alternative for developers and researchers, paving the way for innovative applications and personal AI solutions in the future.
References
- Ollama Models Webpage — Mistral, Mistral-NeMo, and Mistral Large. Read me.
- Mistral AI team. “Mistral 7B — The best 7B model to date, Apache 2.0.” 27 Sep. 2023. Read me. Accessed on 31 July 2024.
- Mistral AI team. “Mistral NeMo: Our new best small model.” 18 Jul. 2024. Read me. Accessed on 31 July 2024.
- Mistral AI team. “Large Enough” 24 Jul. 2024. Read me. Accessed on 31 July 2024.
Catch the latest version of this article over on Medium.com. Hit the button below to join our readers there.






















