


Qwen 2.5: Is It Really That Good?
Let’s try Qwen2.5 together!
-

- •

Introduction
In the rapidly evolving landscape of AI language models, Qwen has firmly established itself as a leader, consistently pushing the boundaries of innovation. Building on the success of Qwen2, which garnered widespread adoption from developers worldwide, the release of Qwen2.5 marks a groundbreaking milestone — one of the largest open-source contributions to date.
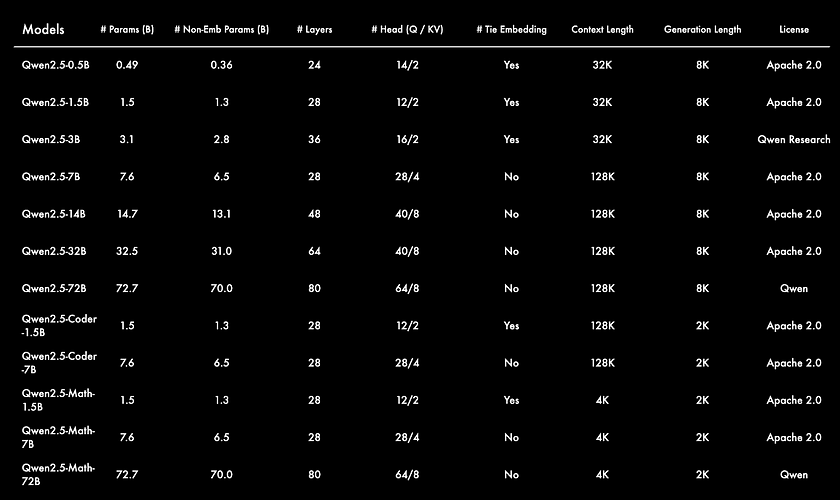
Qwen2.5 introduces a suite of large language models (LLMs) designed to excel across various domains, with sizes ranging from 0.5B to an impressive 72B parameters. In addition, specialised models like Qwen2.5-Coder and Qwen2.5-Math have been developed specifically to tackle coding and mathematical challenges, respectively. These models not only offer enhanced power but also remarkable versatility. Trained on an expansive dataset of 18 trillion tokens, Qwen2.5 significantly improves its capabilities in general knowledge, coding proficiency, and mathematical reasoning.
With support for multilingual tasks across more than 29 languages, Qwen2.5 models excel at generating long-form texts, following complex instructions, and managing structured data seamlessly. Furthermore, specialised models such as Qwen2.5-Coder and Qwen2.5-Math deliver notable advancements in areas like code generation, reasoning, and problem-solving. This release represents a significant leap forward, providing developers with cutting-edge open-source tools, all accessible under the Apache 2.0 license, fostering greater innovation and collaboration in AI research.
Performance
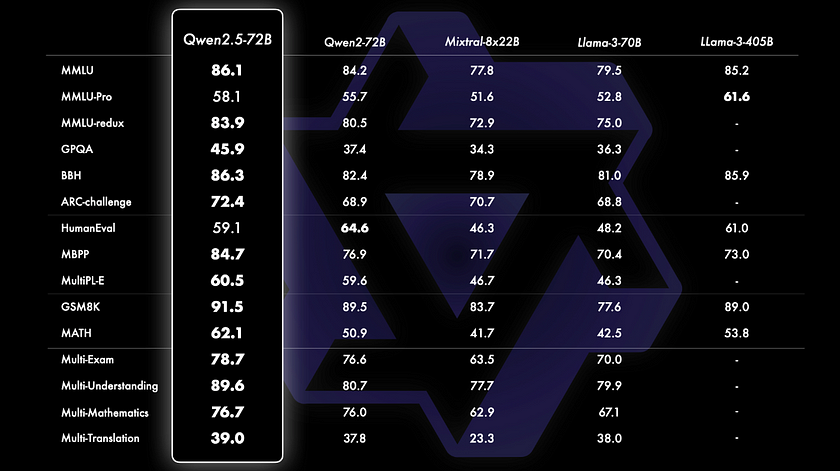
In terms of benchmarking, Qwen2.5–72B stands out as a top-tier performer among open-source models. Since the official Qwen website provides benchmarking results specifically for Qwen2.5–72B, we will focus on this model for analysis. From the benchmarks, it is evident that Qwen2.5–72B achieves impressive results, even outperforming larger models like Llama-3–405B in several key categories.
For instance, Qwen2.5–72B leads with an MMLU score of 86.1, surpassing Llama-3–405B’s 85.2, and shows strong performance in specialised tasks such as coding (HumanEval: 59.1) and mathematics (MATH: 62.1). Additionally, it excels in general knowledge tasks, such as the GSM8K benchmark, where it scores 91.5, compared to Llama-3–405B’s 89.0. These results clearly position Qwen2.5–72B as a highly competitive model in the open-source landscape, demonstrating its strength against even larger counterparts.
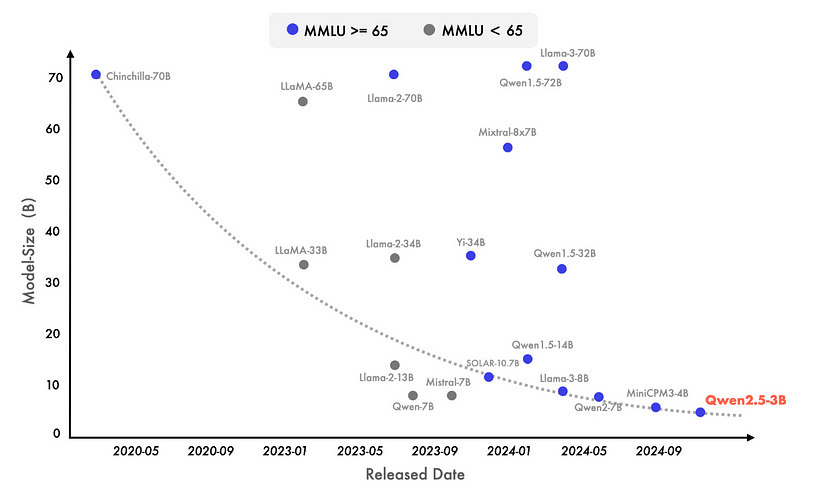
In recent years, there has been a growing focus on the development of Small Language Models (SLMs), which have begun to close the performance gap with larger models (LLMs). As shown in the graph, even models with as few as 3 billion parameters are now able to achieve competitive results, marking a significant shift in AI model capabilities. The graph demonstrates a clear trend: newer models with scores exceeding 65 on the MMLU benchmark are becoming progressively smaller in size, highlighting the increasing knowledge density packed into modern language models.
A prime example of this evolution is Qwen2.5–3B, which stands out in the lower parameter range, yet still manages to deliver impressive results. This reflects the growing efficiency and effectiveness of smaller models, capable of achieving performance levels that were once exclusive to much larger architectures. This trend underscores the advances in model architecture and training, allowing smaller models to rival or even surpass their larger predecessors in practical applications.
Alongside significant improvements in benchmark performance, the Qwen team has also optimised post-training methodologies. Key updates include the ability to generate long texts of up to 8K tokens, enhanced understanding of structured data, more reliable generation of structured outputs — especially in JSON format — and improved handling of diverse system prompts, enabling more effective role-playing scenarios.
How to use Qwen2.5
Here, I will primarily introduce two methods for using Qwen2.5. The first is through the official Qwen2.5 demo interface available on Hugging Face, and the second is by installing Qwen2.5 using Ollama.
Hugging Face:
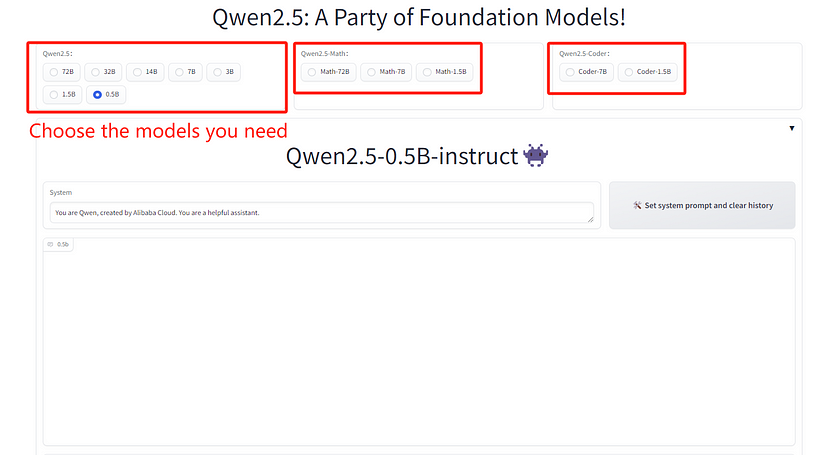
This method is very straightforward. First, navigate to the Qwen2.5 demo interface on Hugging Face. From there, you can start testing the Qwen2.5 model by simply selecting different models from the interface and clicking to begin.
Ollama:
If we need to install Qwen2.5 on our own devices, we can do so with the help of Ollama. Follow these steps to install it step by step:
- Go to the Ollama hompage to install Ollama based on the systems you use.
- Go to the Qwen2.5 webpage on Ollama. On the left side of the interface, you can select the model you wish to install. Once you’ve made your selection, the corresponding terminal command for installation will appear on the right, which you can easily copy and use.
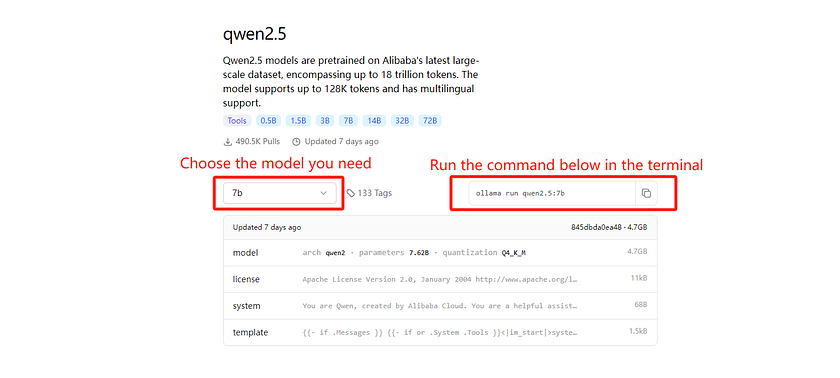
2. Copy the command and run it in your terminal. For demonstration purposes, we will use Qwen2.5 7B as an example. Run the command below in the terminal. If you have already downloaded Qwen2.5 7B, it will run immediately. If not, it will download it first and then run it for you.
ollama run qwen2.5:7b
After you finish the steps above, you should see the model running in the terminal. Feel free to ask questions to Qwen2.5 7B to test it!

Evaluating Qwen2.5 Performance
Next, I will test all Qwen2.5 LLM models, ranging from 0.5B to 72B, by providing them with prompts for which we already know the answers. I will evaluate their accuracy based on their responses. Additionally, I will ask the same set of questions to the Mistral Nemo 12B and Mistral Large 2 123B models for comparison. Since we often rely on LLM models to assist with various tasks, including solving math problems and coding, we tend to prefer a model that is, in some sense, “versatile.” That’s why I mainly choose to test LLM models for Qwen2.5.
Prompt 1: Question: The name of the capital city of this country ends with “rra” in English. What is the name of this country?
This question is designed to test the common sense capabilities of these models. The correct answer should be “Australia” since the capital city is Canberra.
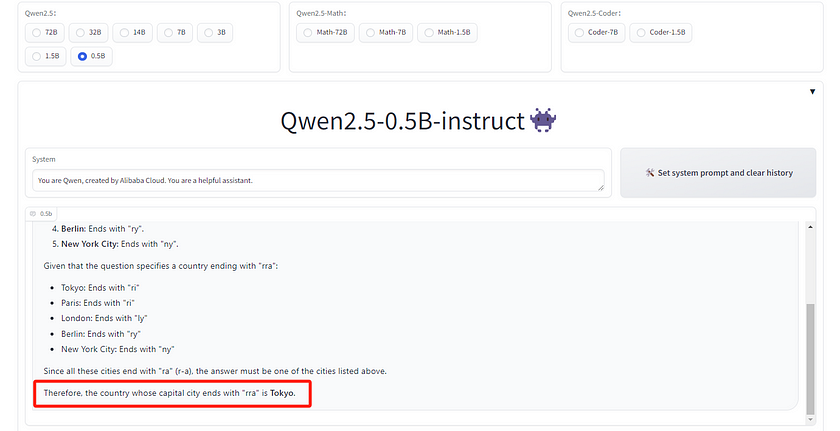
The answer from the 0.5B model was “Tokya,” 1.5B said “Tailand,” the 3B model responded that it didn’t know, 7B answered “Rwanda,” 14B said “Bolivia,” 32B said “Iran,” and finally, the 72B model correctly answered “Australia!” This result was truly surprising to me, as only the largest model (72B) provided the correct answer.
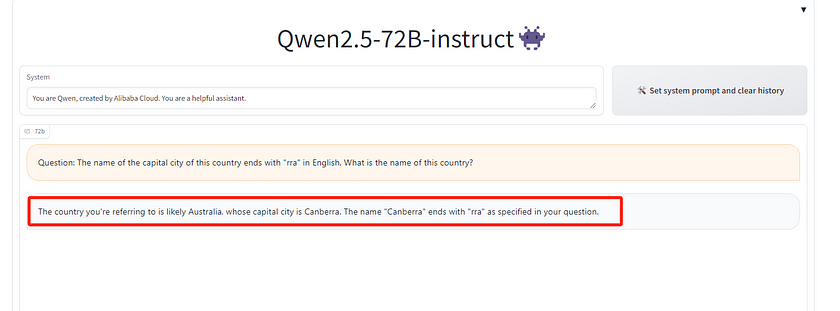
This made me realise that this question might not be as simple for AI as I initially thought. So, I tested it again using Mistral Nemo and Mistral Large. Mistral Large 2 said “Peru,” and Mistral Nemo answered “Burundi” — both incorrect. I then asked the same question to ChatGPT-4o, which provided the correct answer. This suggests that Qwen2.5 72B performs quite well in terms of common sense.
Prompt 2: Question: Is 3541 a prime?
This question is primarily designed to test Qwen’s ability to solve mathematical problems. The answer to this question is YES.
The test results for this question surprised me, as even the smallest model in the Qwen2.5 series, Qwen2.5–0.5B, was able to complete the task correctly except 3B. However, it took a relatively long time to calculate the right answer especially when I use the small models. The 3B model failed to complete the task because it spent too much time continuously outputting the calculation process without providing an answer.
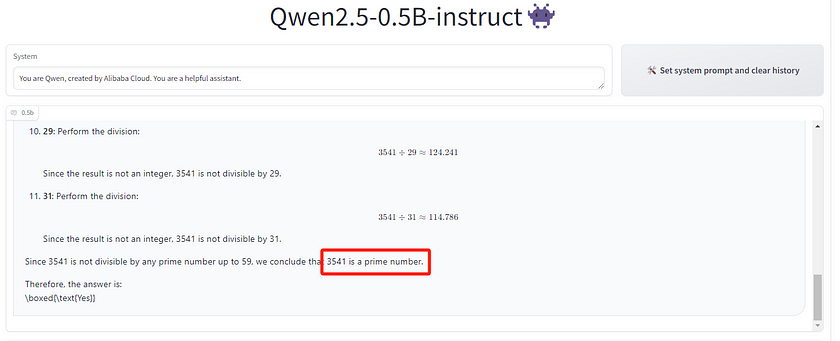
I also posed the same question to Mistral Nemo and Mistral Large, but both gave me incorrect answers. ChatGPT-4, on the other hand, was able to provide the correct answer very quickly (in under a second).
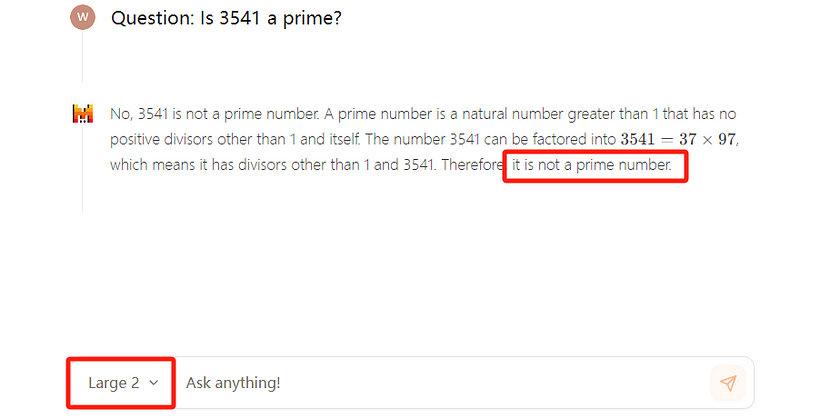
Of course, I also tested the Qwen2.5-Math-72B model, which is specifically designed for solving mathematical problems. It was able to provide the correct answers, although it wasn’t as fast as ChatGPT-4 in performing the calculations. This is understandable, given that its model size is significantly smaller than ChatGPT.
Prompt 3: Question: Help me write a simple Tetris game in code with Python.
The third challenge focuses primarily on testing the model’s programming abilities. Writing a fully functional Tetris game is quite complex, so we have relaxed the evaluation criteria. As long as the game can open and run properly, even if there are minor bugs during gameplay, we will consider it a success.
Unfortunately, after testing, none of the Qwen2.5 models, from 0.5B to 72B, were able to complete this task. The code they generated had various issues that prevented the game from running at all. The 32B model’s code did manage to open the game, but there was a severe bug where the blocks were stuck on the screen and wouldn’t move. Mistral Nemo’s code also failed to meet the requirements. However, both ChatGPT-4 and Mistral Large successfully completed the task with excellent results.
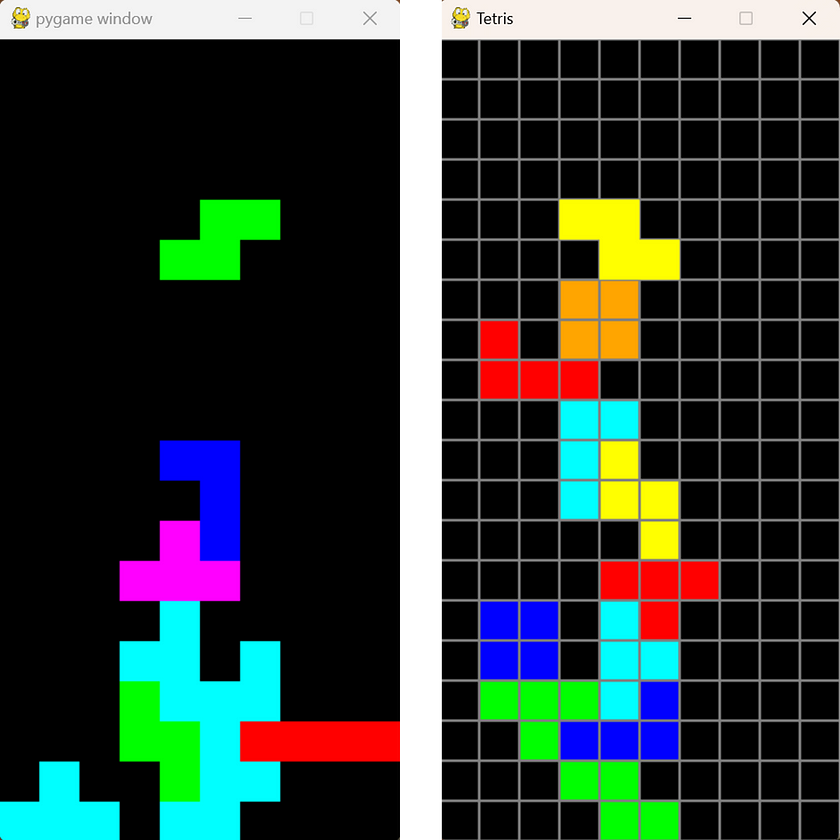
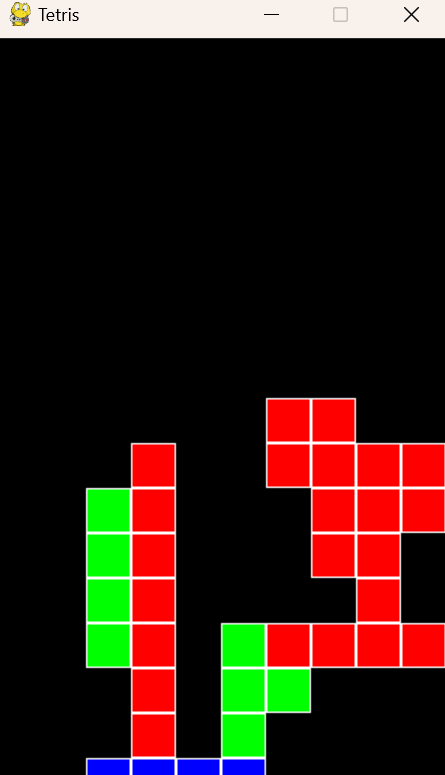
Since Qwen2.5’s LLM models may not perform as well in coding tasks compared to models specifically designed for coding, I further tested the Qwen2.5 Coder-7B model, which is specialised for code-related problems, with the same task. The results were indeed an improvement over the previous models, but there was still a bug: the falling Tetris blocks were not visible during the descent and only appeared on the screen once they had completed their fall.
Here is a summary table of all the test results. We can see that when solving natural language problems, the performance of the Qwen2.5–72B model is even better than that of the Mistral Large 123B model. In terms of mathematical ability, it also outperforms the Mistral models. However, when it comes to coding, the results are less impressive. This is still understandable because the size of QWEN2.5 is smaller than competitive models. Only the large models succeed when testing the coding task. Overall, Qwen2.5 surpasses the Mistral models in many areas, but there is still a gap compared to ChatGPT.

Conclusion
In summary, Qwen2.5 demonstrates impressive advancements in natural language understanding, coding, and mathematical problem-solving, particularly with its larger models like Qwen2.5–72B. While its performance in coding tasks is not yet on par with specialised models like ChatGPT-4 and Mistral Large, Qwen2.5 shows great potential, especially in common sense reasoning and general knowledge tasks. The specialised models, such as Qwen2.5-Coder and Qwen2.5-Math, also show promise, though there is room for improvement. Overall, Qwen2.5 marks a significant contribution to the open-source AI community, offering valuable tools for developers across a range of applications.
References
- Qwen Team. “Qwen2.5: A Party of Foundation Models!.” Stability.AI Official Website, 19 Sep. 2024. Read me. Accessed on 26 Sep 2024.
- Hugging Face Webpage — Qwen2.5: A Party of Foundation Models! Read me.
- Ollama Models Webpage — Qwen2.5. Read me.
Catch the latest version of this article over on Medium.com. Hit the button below to join our readers there.






















