

Stable Diffusion 3.5
Stability AI’s latest release offering New Models and Features

Stable Diffusion 3.5 by Stability AI marks a major step forward in AI-driven image generation. Following the launch of Stable Diffusion 3 Medium, which faced some criticism, Stability AI has now introduced Stable Diffusion 3.5 with an array of improvements, making it their most powerful model yet. Let’s explore what makes Stable Diffusion 3.5 stand out and why it has captured the interest of AI enthusiasts and professionals.
Introducing Stable Diffusion 3.5
Stable Diffusion 3.5 is an open release that includes multiple model variants, each designed for specific use cases. These include Stable Diffusion 3.5 Large, Stable Diffusion 3.5 Large Turbo, and Stable Diffusion 3.5 Medium (to be released on October 29th). These models are designed to run on consumer hardware, providing greater accessibility, flexibility, and performance.
You can download Stable Diffusion 3.5 Large and Stable Diffusion 3.5 Large Turbo models from Hugging Face and access the inference code on Github. It allows both commercial and non-commercial use.
The model weights are now accessible on Hugging Face for self-hosting, and the model can also be utilised via the following platforms:
Key Takeaways: What’s Being Released?
1. Stable Diffusion 3.5 Large
- Parameters: 8 billion.
- Quality and Prompt Adherence: Delivers the highest quality images at 1-megapixel resolution.
- Ideal For: Professional-grade applications requiring superior detail and precision.
2. Stable Diffusion 3.5 Large Turbo
- Parameters: 8 billion (distilled version).
- Speed: High-quality image generation in just four steps, making it significantly faster.
- Use Cases: When speed is prioritised without sacrificing image quality.
3. Stable Diffusion 3.5 Medium (To be released on October 29th, 2024)
- Parameters: 2.5 billion.
- Optimised For: Consumer hardware with enhanced MMDiT-X architecture.
- Flexibility: Customisable with resolutions between 0.25 and 2 megapixels.
How Does Stable Diffusion 3.5 Work?
In Stable Diffusion 3.5, Stability AI has integrated Query-Key Normalization into its transformer blocks, improving model training stability and enhancing fine-tuning capabilities. This allows for more precise customisations and easier modifications, making it ideal for those looking to develop AI applications or fine-tuned art styles.
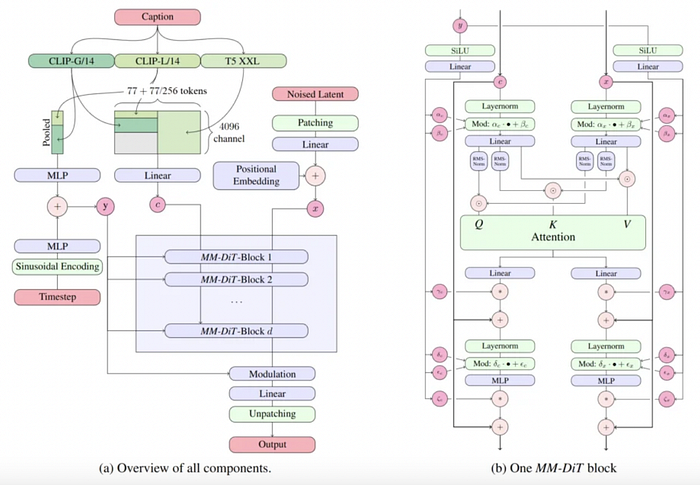
Components Overview
CLIP and T5 Models
The architecture involves two CLIP models (marked as CLIP-G/14 and CLIP-L/14) along with a T5 XXL model. CLIP is responsible for understanding and encoding images and text, while T5 focuses more on text-based understanding and generation.
Input tokens
Both the image and text inputs are represented as tokens, which are individual segments that the model processes. Here, the architecture takes 77 tokens from CLIP models and a larger set of tokens from T5 XXL for comprehensive text processing.
Patching & Embedding
The diagram shows that after encoding and pooling (simplifying) the image, it is broken into smaller segments or “patches” which are embedded or converted into a format that the model can understand.
Latent Space & Positional Embedding
The “Noised Latent” part refers to the core of diffusion models like Stable Diffusion, where the model gradually removes noise from an image to create a clear picture. Positional embedding helps the model understand the order and relative position of elements in the text and images.
Multiple MM-DiT Blocks
These are sections that repeatedly process information in stages. Each block refines the input, making the model more accurate over each step. MM-DiT blocks essentially represent a specialised variant of transformer-based layers.
Attention Mechanism
At the heart of the MM-DiT block, there’s an attention mechanism denoted by Q (Query), K (Key), and V (Value). This mechanism lets the model focus on different aspects of the input (e.g., text details or image sections) and figure out the most relevant parts to pay attention to.
Modulation and Layer Normalization
The architecture uses multiple normalising steps, ensuring each segment of data is correctly scaled and processed. Modulation elements (denoted as “Mod”) help adjust the information flow to fine-tune the final output.
MLP (Multi-Layer Perceptron)
These MLP blocks act as processing units for refining the image and text representations. They further polish the outputs from the attention blocks.
Overall Workflow
Text and image tokens are fed separately through CLIP and T5 XXL, encoding the data to meaningful tokens.
Noised latent and positional embedding provide the model with processed visual input and text-based positional information.
The combined data is processed through a series of MM-DiT blocks. These blocks gradually refine the text and image features using repeated attention and normalization processes.
The noised latent input, derived from visual data, helps the model learn to progressively refine and reconstruct image details, enhancing visual comprehension.
Meanwhile, positional embeddings capture the structure and order of text, ensuring that the model understands relationships between words and aligns them with corresponding visual features. Together, these components allow the model to maintain coherence between image and text, leading to improved understanding and generation capabilities.
Finally, modulation and unpatching convert the processed tokens back into the desired output format.
This architecture ensures that the model can both understand and generate high-quality images and text while keeping a clear connection between visual and language data. In simpler terms, it’s like a series of intelligent filters that understand and enhance the relationship between images and words to generate or process visual-text content accurately.
Customisability with Trade-Offs
While the model’s flexibility allows for broader applications, it also leads to more variation in outputs from the same prompt with different seeds. This variance is intentional and supports a more diverse knowledge base and creative possibilities.
Key Features of Stable Diffusion 3.5
- Customisability: The new architecture enables users to fine-tune models more easily for specific creative requirements.
- Efficient Performance: Optimised to run on consumer-grade hardware, especially with Stable Diffusion 3.5 Medium and Large Turbo models.
- Versatile Styles: The model can generate a wide array of visual aesthetics such as 3D renders, photorealistic images, line art, and paintings.
- Prompt Adherence: Competing with even larger models in terms of following input prompts accurately.
- Diverse Outputs: Creates images representative of the world, not just one type of person, but rather different features in a person.


Performance and Comparisons
Stable Diffusion 3.5 rivals larger, resource-intensive models in areas such as image quality and prompt adherence. Notably, Stable Diffusion 3.5 Large Turbo has some of the fastest inference times for its size, achieving high image quality in just four steps. This makes it a strong contender against similar models from competitors like Flux and Midjourney.
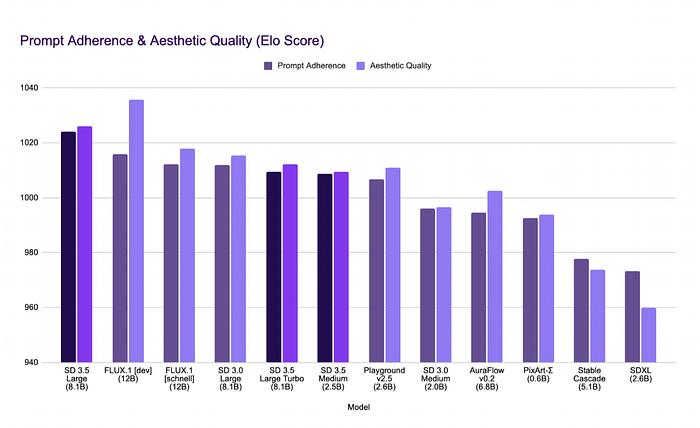
Market-Leading Prompt Adherence
In terms of aligning generated images with input prompts, Stable Diffusion 3.5 Large has outperformed comparable models, while Stable Diffusion 3.5 Medium is among the top choices for balancing quality and efficiency.
Improvements Under the Hood
Stability AI prioritised customisability by redesigning core model functionalities. The use of Query-Key Normalisation during training stabilises the entire process, allowing users to fine-tune the models with ease. Moreover, Stability AI introduced the LoRA (Low-Rank Adaptation) training guide to help users quickly specialise the model to specific styles or subjects.
Support for Negative Prompts
The new model claims that it supports negative prompts, allowing users to include specific instructions in their prompts to avoid unwanted results.





Output comparison of Stable Diffusion 3.5 VS FLUX.1
This section shows the output comparison of Stable Diffusion 3.5 (SD3.5) and FLUX.1! as per RunComfy. With the latest ComfyUI workflow, you can now input a text prompt and generate images using both models simultaneously, making it easy to compare and select your favourite results.



The output using SD3.5-large and Flux.1, each model showcased its strengths. FLUX.1 excels at creating highly photorealistic images, while SD3.5 shines in producing anime-style artwork without needing additional fine-tuning or adjustments.
Real-World Applications of Stable Diffusion 3.5
1. Artistic and Creative Projects
Artists can explore new visual styles and experiment with creative ideas. The flexibility of the model allows for fine-tuned aesthetics and stylistic experimentation.
2. Professional Content Creation
Agencies, marketers, and developers can leverage the model to create custom imagery for branding, advertisements, and game design. The high-resolution outputs make it suitable for professional environments.
3. Educational and Research Use
Educators and researchers can use Stable Diffusion 3.5 to visualise complex concepts, making learning more engaging and interactive.
Conclusion
In conclusion, Stable Diffusion 3.5 stands as a landmark achievement in generative AI, redefining the balance between innovation and accessibility. By integrating advanced features like Query-Key Normalization and refining its architecture, Stability AI has successfully addressed past limitations and delivered a model that excels in both performance and prompt adherence. This release underscores the company’s commitment to shaping the future of visual media, offering a versatile solution for creators, developers, and enterprises. As the landscape of AI-powered image generation continues to evolve, Stable Diffusion 3.5 sets a new standard, combining cutting-edge capabilities with practical deployment options, making it a pivotal tool in the creative and professional domains.
References
- Stability AI, “Stable Diffusion 3.5 Overview,” DeepInfra. [Online]. Available: https://deepinfra.com/stabilityai/sd3.5.
- RunComfy, “Stable Diffusion 3.5 vs. Flux1: A Detailed Comparison,” ComfyUI Workflows. [Online]. Available: https://www.runcomfy.com/comfyui-workflows/stable-diffusion-3.5-vs-flux1.
- A. McFarland, “Stable Diffusion 3.5: Architectural Advances in Text-to-Image AI,” Unite.AI, 22-Oct-2024. [Online]. Available: https://www.unite.ai/stable-diffusion-3-5-architectural-advances-in-text-to-image-ai/.
- Stability AI, “Introducing Stable Diffusion 3.5,” Stability AI News. [Online]. Available: https://stability.ai/news/introducing-stable-diffusion-3-5.
Catch the latest version of this article over on Medium.com. Hit the button below to join our readers there.






















