


Typesense and Neo4j in a hybrid information retrieval solution
A novel approach to improving the efficiency of text search in graph databases utilising Neo4j, OpenAI, and Typesense
-

- •



Introduction
The ability to use cutting-edge tools and frameworks is essential for staying ahead in the ever-changing field of technology. When it comes to natural language processing, search capabilities, and graph databases, LLM (Large Language Models), Typesense, and Neo4j work together as a powerful trio that offers a cohesive and effective solution.
As we explore further, we will learn about the unique advantages of Typesense, Neo4j, and LLM and how their combined powers may open up a new world of possibilities. This blog is your resource for comprehending, putting into practice, and optimising the potential of this influential trio, whether you’re a developer looking for creative solutions, a data scientist seeking improvements in analytics, or a business professional trying to maximise information retrieval.
What is Neo4j and Typesense?
Neo4j is a well-known graph database that specialises in managing densely linked data. Because of its superior relationship management capabilities, it is a well-known option for applications with complex data models. Conversely, Typesense is an extremely quick, open-source search engine that can quickly search through and retrieve a lot of text-based data.
While Neo4j is a powerful tool for traversing relationships and querying graph data, its built-in text search features are not effective for handling large amounts of text. Here, we will use Typesense to enhance Neo4j’s text search capabilities by using a customised solution for effective and quick search operations.
Text Search Challenges in Neo4j
Memory: Neo4j relies heavily on memory. Thus, it may consume a lot of memory for intensive text search queries.
Lack of Specialised Text Search Features: Neo4j is a graph database, and its main function is to handle and store graph-based data. As compared to other search tools, it lacks some specialised text search features, which may have a negative impact on the result.
In this article, we are using a Neo4j Graph database that uses this schema to demonstrate the challenges for text search and potentially a working solution. The graph includes five primary objects including research publications, researchers, organisations, academic grants, and research data collections, capturing the collaborative network of academic works.
The following is a subset of the schema that contains information relevant to this article.

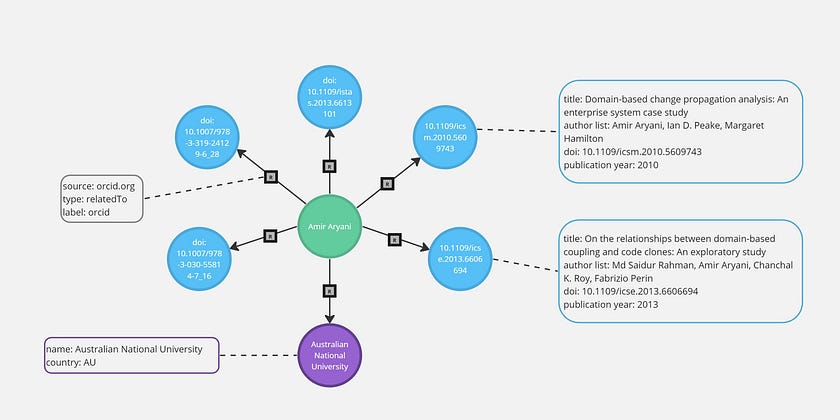
To illustrate the difficulty at hand, if we wish to find research grants and publications associated with ‘Artificial Intelligence’, we will encounter the following issues:
(a) We will need to find all alternative or relevant terms (e.g. AI, ML, ...)
(b) We will need to have a (computationally) expensive text index search across nodes as Neo4j does not particularly perform well for text search.
To address this issue, we are employing a text-based search engine called Typesense. But first, let's look at the advantages and capabilities of both tools in our toolbox.
Advantages of Neo4j
Flexibility: The graph model is adaptable and may quickly change to reflect new relationships and data structures.
Cypher Query Language: Neo4j uses Cypher query language, which is expressive, readable, and more suitable for graph databases. It makes retrieving complex patterns from graph databases easier.
Performance: Neo4j’s underlying architecture is optimised to query nodes and relationships in a graph efficiently, thus improving the performance.
Scalability: Neo4j supports horizontal scalability. It lets you add more machines to handle large datasets when needed.
Transactional Support: Neo4j ensures data consistency and integrity in transactional operations by adhering to the ACID (Atomicity, Consistency, Isolation, Durability) standards.
Advantages of Typesense
Speed: As a search engine designed just for text queries, Typesense performs very well in terms of speed. We can offload the text-search tasks to Typesense and increase the speed of the application.
Rich Text Search: Typesense provides various advanced text search features, including typo tolerance, faceted, hybrid, and fuzzy search. Hence, it can accommodate typos and potential errors in user inputs.
Scalable: Typesense can scale horizontally. Thus, it can handle large datasets and a huge volume of queries.
Easy Integration: Typesense has simple APIs and connectors for different programming languages, making integrating with other platforms and software accessible.
Vector Search
Typesense can use various small LLM models to create embeddings for the text and then use these embeddings to do a nearest neighbour search (KNN).
An embedding for a document is an alternate representation of data as floating point values. These embeddings are generated using Machine Learning models. In principle, two similar documents would have embeddings “closer” to each other.
For example, using OpenAI, we can convert text to embeddings using OpenAI APIs as below:
from openai import OpenAI
client = OpenAI()
response = client.embeddings.create(
input="Your text string goes here",
model="text-embedding-ada-002"
)
print(response.data[0].embedding)The generated embeddings will be as follows:
{
"data": [
{
"embedding": [
-0.006929283495992422,
-0.005336422007530928,
...
-4.547132266452536e-05,
-0.024047505110502243
],
"index": 0,
"object": "embedding"
}
],
"model": "text-embedding-ada-002",
"object": "list",
"usage": {
"prompt_tokens": 5,
"total_tokens": 5
}
}Typesense converts text in each document using the LLM model mentioned in the schema.
Here are some common models you can use to generate these document embeddings:
You can find the list of built-in models supported by Typesense here.
For example, below is a schema for a collection of grants that creates embeddings for the attribute “grant-summary” using the “all-MiniLM-L12-v2” LLM model for creating the embeddings. The created embeddings are stored as a new attribute called embedding in the same document.
grant_schema = {
"name": "grant",
"fields": [
{"name": "grant-summary", "type": "string"},
{"name": "flat-field-of-research", "type": "string"},
{
"name": "embedding",
"type": "float[]",
"embed": {
"from": [
"grant-summary"
],
"model_config": {
"model_name": "ts/all-MiniLM-L12-v2"
}
}
}
]
}
Demo
We will make use of OpenAI, Typesense, and Neo4j to get relevant data for a keyword from the Neo4j graph database.
Resources: We have a Virtual Machine (VM) with a Neo4j server running with the grants data embedded on the “grant-summary” attribute. Typesense is running on the same VM on port 8108. Lastly, we need an OpenAI API key that can be generated from OpenAI.
In this example, we will search for a keyword and all related related terms. We will use OpenAI to generate the related words to the keyword. We will then use these related words to do a semantic search in the Typesense database to get a list of IDs. Using this list of IDs, we can then query the Neo4j database to get the graph.
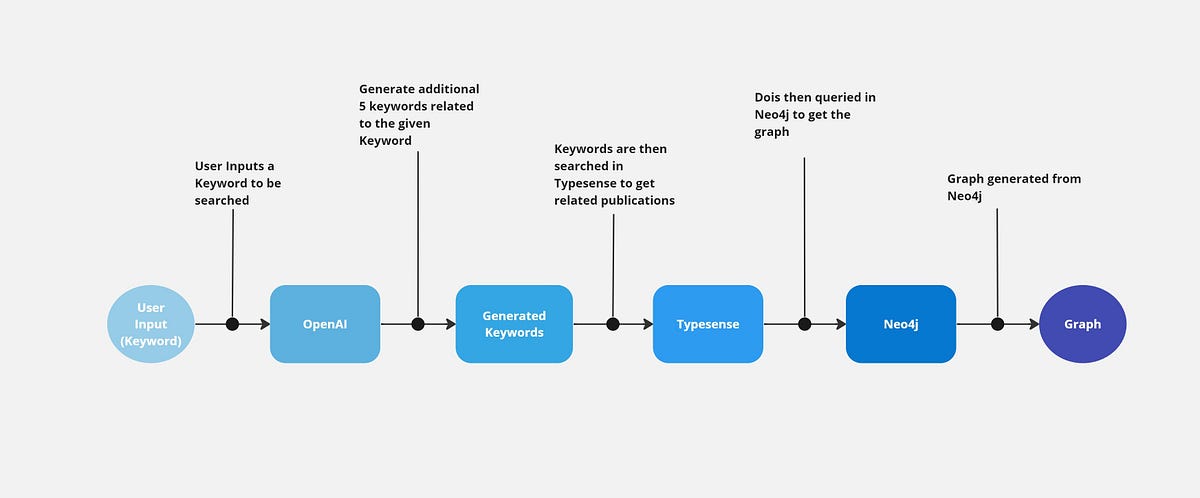
- First, we accept the user input, which is the keyword that needs to be searched.
2. Then, this keyword is passed to OpenAI, which generates a set of 5 keywords that are related to the given keyword.
prompt = "We are searching academic articles for research related to a
keyword presented by the user. Recommend five alternative terms
that find related papers to the given keyword. Only create keywords
and no other description in your response. Produce CSV"
user_prompt = "The keyword I want search for articles is" + search_query_term
import openai
completion = openai.ChatCompletion.create(
model="gpt-4-1106-preview",
messages=[
{"role": "system", "content": prompt},
{"role": "user", "content": user_prompt}
]
)For the keyword “Artificial Intelligence”, OpenAI generated the following output below:
{
"role": "assistant",
"content": "\"machine learning\", \"neural networks\", \"cognitive computing\", \"natural language processing\", \"robotics\""
}3. The generated keywords are then searched in Typesense to get a set of DOIs related to the keywords.
import typesense
client = typesense.Client({
'nodes': [{
'host': 'localhost',
'port': '8108',
'protocol': 'http'
}],
'api_key': api_key,
'connection_timeout_seconds': 300
})
search_parameters = {
'searches': [],
}
for term in completion.choices[0].message["content"].split(','):
search_object = {
'q': term.strip(),
'query_by': 'embedding',
'exclude_fields': 'embedding',
'limit': 2,
'collection': 'publications'
}
search_parameters["searches"].append(search_object)
common_search_params={}
data = client.multi_search.perform(search_parameters, common_search_params);
dois = []
for search_result in data['results']:
for doc in search_result['hits']:
dois.append(doc['document']['DOI'])
print(doc['document']['DOI'] , ' ' , doc['document']['title'])4. DOIs can then be easily queried from the Neo4j database to get the related data and graph.
Conclusion
To sum up, the integration of Neo4j, OpenAI, and Typesense is a combination that tackles the difficulties related to text search in graph databases.
With this integration, developers can take advantage of the benefits of each of the platforms, making text search more effective, scalable, and feature-rich. For those looking to improve the search capabilities of their apps, the Neo4j-OpenAI-Typesense combination seems to be a strong option as businesses struggle with ever-more complicated data models.




















