


What is BLIP?
Bridging the Gap Between Visuals and Language in AI
-

- •

Introduction
In today’s digital age, we’re constantly interacting with images and text together — whether it’s scrolling through social media, searching for products online, or using virtual assistants. But have you ever wondered how computers understand the relationship between what we see and what we read? Enter BLIP, short for Bootstrapping Language-Image Pre-training, a groundbreaking AI technology that’s revolutionising how machines comprehend and generate content that combines images and text.
Developed by researchers at Salesforce, BLIP is like teaching a computer to see and read at the same time, and then use that knowledge to perform amazing tasks. From describing images in natural language to answering questions about visual content, BLIP is pushing the boundaries of what’s possible in the world of artificial intelligence. In this article, we’ll dive into what BLIP is, how it works, and why it’s such a big deal for the future of human-computer interaction.
The Problem BLIP Solves
Imagine you’re showing a photo album to a friend. As you flip through the pages, you naturally describe what’s in each picture, answer questions about the images, or find a specific photo based on a description. These tasks, which seem effortless to us, are quite challenging for computers to perform. This is where vision-language tasks come in: they are AI challenges that involve understanding and processing both images and text together. Some common examples include:
- Image captioning: Generating a text description of what’s in an image.
- Visual question answering: Answering questions about an image in natural language.
- Image-text retrieval: Finding the right image based on a text description, or vice versa.
While AI has made significant strides in these areas, existing methods faced several challenges:
- Specialisation vs. Generalisation: Many AI models were good at either understanding tasks (like answering questions) or generation tasks (like writing captions), but not both.
- Noisy Data: To train these AI models, researchers often used large datasets of images and captions from the internet. However, these captions were often inaccurate or irrelevant, making it harder for the AI to learn effectively.
- Limited Understanding: Previous models sometimes struggled to grasp the nuanced relationships between images and text, leading to errors or misinterpretations.
- Efficiency: Training AI models for these tasks was often time-consuming and required massive amounts of data.
BLIP was developed to address these challenges, aiming to create a more versatile, accurate, and efficient way for AI to understand and work with combined image and text data. In the next section, we’ll explore what BLIP is and how it tackles these problems.
What is BLIP
BLIP, which stands for Bootstrapping Language-Image Pre-training, is like a highly advanced AI student who has mastered the art of understanding and creating content involving both images and text. But what sets BLIP apart is its innovative learning approach and the remarkable range of tasks it can perform.
At its core, BLIP is a sophisticated AI model trained on millions of image-text pairs. Imagine it as an AI that has analysed countless social media posts, each containing an image and a caption. However, BLIP doesn’t simply memorise these pairs. Instead, it develops a nuanced understanding of the intricate relationships between visual elements and their textual descriptions.
BLIP’s effectiveness stems from two key components that set it apart from previous AI models in this field:
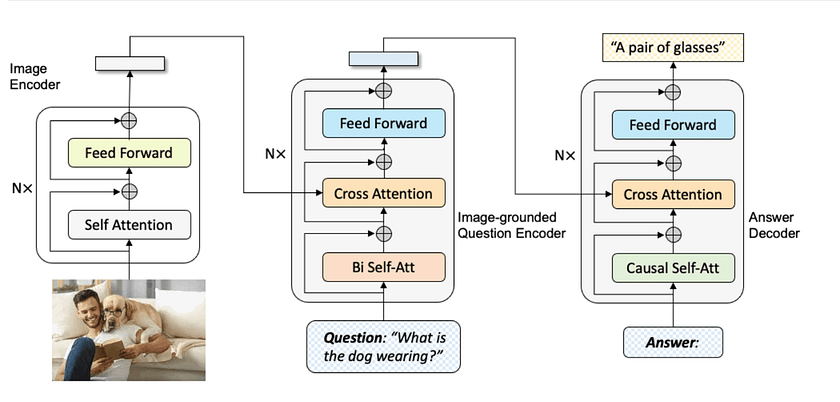
- The MED Model: MED, which stands for Multimodal mixture of Encoder-Decoder, is the core architecture of BLIP. This versatile structure enables BLIP to excel in three critical functions: encoding images, encoding text in the context of images, and generating text based on images:
- Image Encoder: This component analyses visual data, breaking down images into meaningful features. It employs a Vision Transformer (ViT) to process images as a sequence of patches, enabling it to capture both local details and global context. The Image Encoder’s output is a set of visual embeddings that represent the image’s content.
- Text Encoder: This module processes textual information in the context of associated images. It uses a BERT-like architecture enhanced with cross-attention layers, allowing it to interpret text while considering visual context. This enables BLIP to understand nuanced relationships between textual descriptions and visual elements.
- Text Decoder: Generating descriptive text based on visual inputs, this component utilises a transformer-based architecture with causal self-attention. It can produce coherent and contextually relevant captions or responses, leveraging the understanding developed by the Image and Text Encoders.
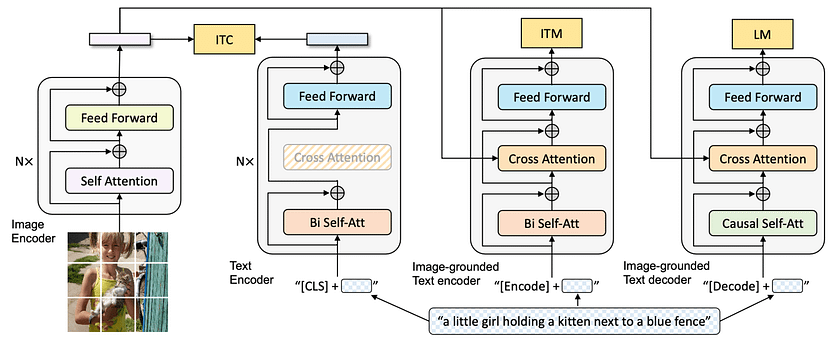
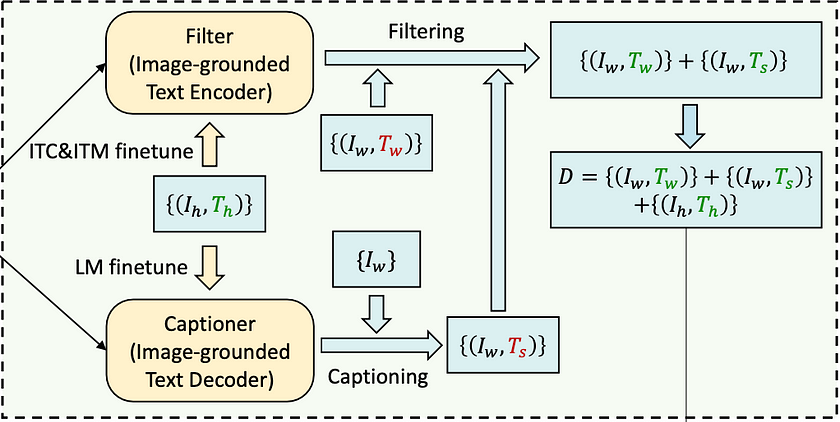
- The CapFilt Method: CapFilt, short for Captioning and Filtering, is an innovative approach to improving the quality of training data. This method addresses the persistent challenge of noisy or irrelevant data often found in large-scale internet-sourced datasets. CapFilt operates in two stages:
— Captioning: The system generates its own descriptive captions for images.
— Filtering: It then evaluates both the original and generated captions, retaining only those that accurately describe the image content.
How BLIP Works
BLIP’s innovative approach combines two key components: the Multimodal Mixture of Encoder-Decoder (MED) Model and the Captioning and Filtering (CapFilt) Method. Let’s explore how these elements work together to create a powerful Vision-Language Pre-training (VLP) framework.
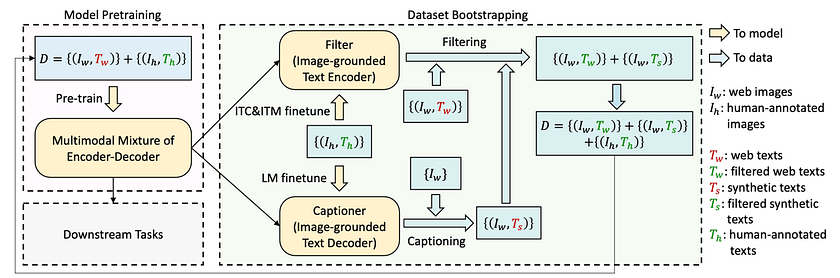
- Initial Pre-training: BLIP starts by pre-training the MED Model on a dataset that combines web-sourced image-text pairs {(Iw, Tw)} with high-quality human-annotated pairs {(Ih, Th)}. This initial training gives the model a foundation in understanding and generating vision-language content.
- CapFilt Method: After pre-training, BLIP employs the CapFilt method to refine and expand its training data: a) Captioner: The MED Model is fine-tuned as an Image-grounded Text Decoder using a Language Modeling (LM) objective. This Captioner generates synthetic captions (Ts) for web images (Iw), introducing new, potentially more accurate descriptions. b) Filter: Simultaneously, the model is fine-tuned as an Image-grounded Text Encoder using Image-Text Contrastive (ITC) and Image-Text Matching (ITM) objectives. This Filter evaluates both web texts (Tw) and synthetic texts (Ts), retaining only the most accurate ones.
- Dataset Bootstrapping and Iterative Improvement: The CapFilt process creates an improved dataset by combining filtered web texts (Tw’), filtered synthetic texts (Ts’), and original human-annotated pairs (Ih, Th). This refined dataset D = {(Iw, Tw’)} + {(Iw, Ts’)} + {(Ih, Th)} is then used to pre-train a new MED Model. This creates a powerful feedback loop: the improved dataset enhances the model’s performance, which in turn can generate better captions and perform more accurate filtering in subsequent iterations. This iterative process continuously refines the model’s understanding and generation capabilities.
By combining the flexible MED architecture with the data-improving CapFilt method, BLIP creates a robust system that can learn from noisy web data while continuously refining its understanding of vision-language relationships. This approach results in a model that can seamlessly switch between understanding and generation modes, making it a powerful tool for diverse vision-language applications.
Why BLIP Matters
BLIP represents a significant leap forward in the field of vision-language AI, setting itself apart from previous methods in several key ways.
Firstly, BLIP’s unified approach to vision-language tasks is a major innovation. Unlike many previous models that excelled either at understanding tasks (such as visual question answering) or generation tasks (like image captioning), BLIP performs admirably in both domains. This versatility stems from its MED architecture, which integrates encoding and decoding functionalities. As a result, BLIP can switch between tasks without the need for separate, specialised models, offering a more efficient and flexible solution for a wide range of applications.
Another standout feature of BLIP is its novel approach to handling noisy web data. Previous methods often struggled with the inconsistent quality of image-text pairs sourced from the internet, which could lead to suboptimal learning and performance. BLIP addresses this challenge head-on with its CapFilt method. By generating its own captions and then filtering both original and synthetic captions, BLIP effectively creates a self-improving loop that enhances the quality of its training data. This approach not only mitigates the impact of noisy data but also allows BLIP to learn from a broader range of examples, improving its overall robustness and performance.
Furthermore, BLIP shows remarkable adaptability when fine-tuned for specific tasks. Its pre-trained model serves as a strong foundation that can be efficiently adjusted for various downstream applications, often outperforming specialised models in their respective domains. This adaptability makes BLIP not just a powerful research tool, but also a practical solution for real-world applications.
Potential Real-World Applications
BLIP’s advanced capabilities in understanding and generating content that combines images and text open up a wide range of real-world applications. Let’s explore some of the most promising areas where BLIP can make a significant impact.
One of the most powerful applications of BLIP is in enhancing accessibility for visually impaired individuals. BLIP’s image captioning abilities can generate detailed, contextually accurate descriptions of images on websites, social media platforms, or digital documents. For instance, a visually impaired user browsing a news website could receive rich, narrative descriptions of photographs accompanying articles, providing a more complete understanding of the content. This technology could be integrated into screen readers, significantly improving the online experience for millions of users worldwide.
BLIP’s image-text retrieval functionality has significant implications for digital asset management and content creation. In the field of journalism or digital marketing, professionals often need to sift through vast databases of images to find the perfect visual for their content. BLIP could power an advanced search system where users can input detailed textual descriptions and receive highly relevant image results. For instance, a marketer could search for “a group of diverse professionals collaborating in a modern office space with a city skyline visible through large windows,” and BLIP would understand and retrieve images matching this complex description.
Conclusion
BLIP represents a significant leap forward in vision-language AI, offering a versatile and powerful solution for understanding and generating multimodal content. By integrating advanced image and text processing capabilities within a unified framework, BLIP excels in tasks ranging from image captioning to visual question answering. Its innovative architecture and ability to handle noisy web data positions it at the forefront of AI technology, with applications spanning industries from e-commerce to healthcare and accessibility. As BLIP continues to evolve, it promises to reshape how we interact with visual and textual information, paving the way for more sophisticated AI systems that can understand and communicate about our visual world with increasing proficiency.
References
[1] BLIP: Visual Language Processing with OpenVINO — Practical example of BLIP implementation. Read notebook.
[2] BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation — Original research paper on BLIP. Read paper.
[3] BLIP GitHub Repository — Official implementation and code for BLIP by Salesforce. Explore code.
Catch the latest version of this article over on Medium.com. Hit the button below to join our readers there.






















