


What is Fal AI?
A Beginner’s Guide
-

- •

Introduction
In the rapidly evolving landscape of artificial intelligence, developers and businesses face a common challenge: bridging the gap between cutting-edge AI models and practical, real-world applications. As the complexity and computational demands of AI continue to grow, so does the need for efficient, scalable, and user-friendly platforms that can harness the power of these models. Enter Fal AI, a groundbreaking platform that’s redefining how we interact with and deploy AI technologies. Fal AI emerges as a solution to the perennial problems of latency, scalability, and ease of use in AI development. By offering lightning-fast inference APIs, seamless serverless deployments, and a suite of tools designed for real-time AI applications, Fal AI is democratising access to advanced AI capabilities. In this article, we’ll explore what Fal AI is, dive into working examples that showcase its power, and demonstrate how it’s simplifying the process of building and deploying AI-driven applications. Whether you’re a seasoned AI developer or just starting your journey in the world of artificial intelligence, Fal AI offers a compelling platform that promises to accelerate your projects and bring your AI visions to life.
What is Fal AI?
Fal AI is a cutting-edge platform designed to revolutionise the way developers and enterprises interact with AI technologies. Founded with the mission to make AI development more accessible and efficient, Fal AI has quickly garnered attention in the tech world, recently securing $23 million in funding to fuel its growth. At its core, Fal AI aims to address the common pain points in AI development: slow inference times, complex deployment processes, and the challenges of scaling AI applications. The platform’s flagship offering is its suite of real-time inference APIs, which allow developers to access and deploy state-of-the-art AI models with unprecedented speed. Fal AI has optimised popular models like Stable Diffusion, reducing inference times from seconds to milliseconds. This breakthrough enables the creation of truly interactive AI applications, opening up new possibilities in fields such as real-time image generation, text-to-speech conversion, and dynamic content creation. Beyond speed, Fal AI provides a comprehensive ecosystem for AI development. Its serverless infrastructure allows developers to deploy Python functions as scalable endpoints without worrying about underlying hardware management. The platform also offers web endpoints for easy API creation, a sophisticated queue system for handling high loads, and runtime optimisations for enhanced performance. With its user-friendly SDKs, support for popular frameworks, and enterprise-grade reliability, Fal AI is positioning itself as a one-stop solution for both individual developers and large organisations looking to harness the power of AI in their applications.

Working Example 1:Basic Image Generation via Web Interface
Fal AI’s web interface offers an intuitive platform for generating images using various AI models. This example demonstrates how to create images, explore sample prompts, and analyse usage statistics without any coding.
Steps
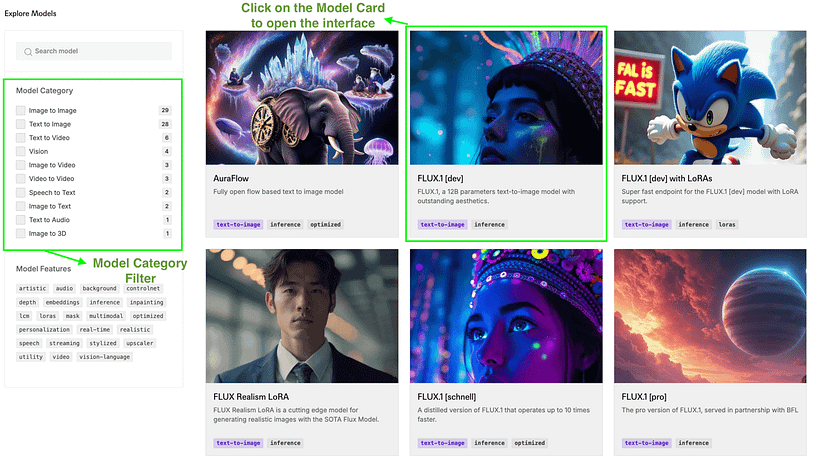
1. Navigate to https://fal.ai/models in your web browser.
2. Browse the available image generation models. For this example, let’s use “FLUX.1 [dev]”.
3. Click on the “FLUX.1 [dev]” model to open its interface.
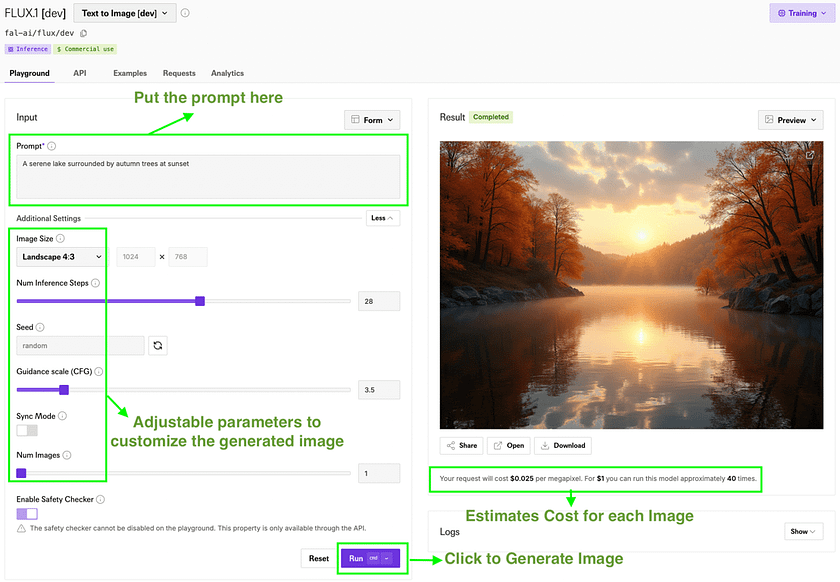
4. In the prompt field, enter a description of the image you want to generate. For example: “A serene lake surrounded by autumn trees at sunset”.
5. (Optional) Adjust additional parameters if available, such as:
- Image dimensions: to set the output size
- Number of images: to generate multiple variations
6. Click the “Generate” button, View and download the generated image at will.
7. Additionally, you can:
a. Explore the “Examples” tab:
- View sample prompts and their generated images for inspiration
- Use “Copy prompt” to directly use a sample prompt
- Click “Customize it” to modify a sample prompt
- Note the parameters used (e.g., num_inference_steps, guidance_scale) for each example
b. Analyse your usage in the “Analytics” tab:
- Review total requests and success rate
- Check Billable Time to estimate resource consumption
- Examine speed metrics (p90 and p75) to understand performance
- View request stats and latency graphs to identify usage patterns
- Check recent errors and slower requests for troubleshooting
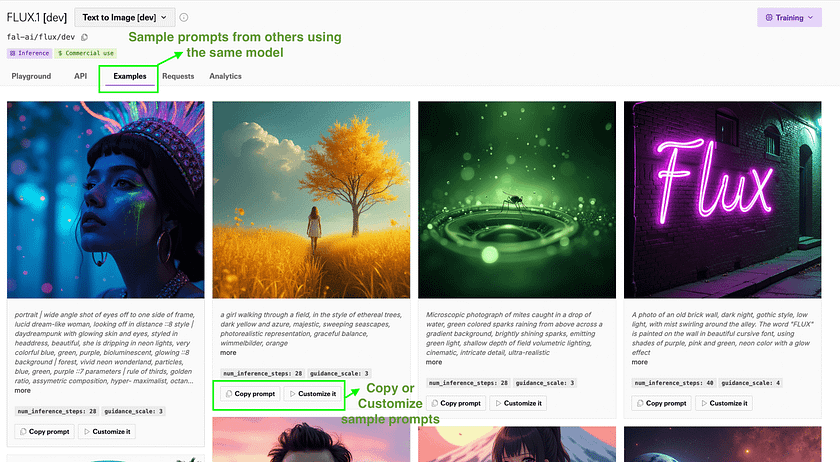
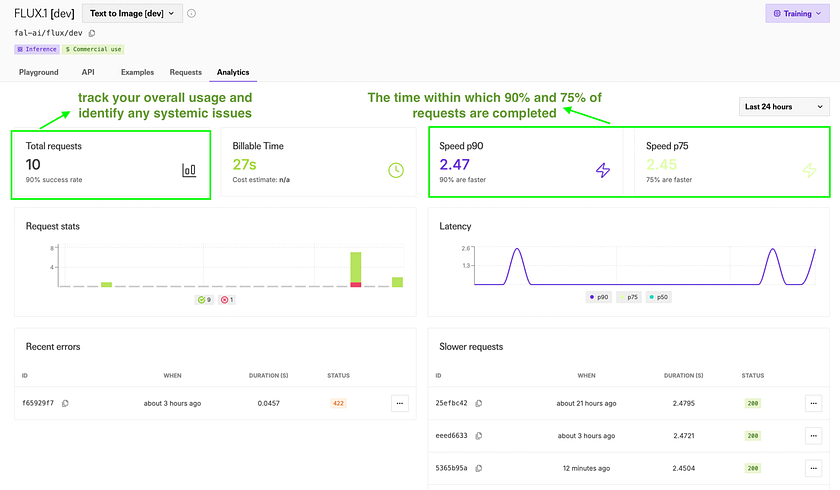
The web interface simplifies AI image generation, allowing users to experiment with various prompts and settings without coding. The Examples tab provides inspiration and helps users understand effective prompts and parameters. The Analytics tab offers valuable insights into usage patterns, performance metrics, and potential issues, helping users optimise their use of the platform and troubleshoot any problems.
Working Example 2: Basic Image Generation via API
Fal AI provides powerful APIs that allow developers to integrate AI-powered image generation capabilities into their applications. These APIs support various programming languages, including Python, JavaScript, Kotlin, and Swift, making them accessible to a wide range of developers. In this example, we’ll demonstrate how to use the Python API to generate images using the FLUX.1 [dev] model, showcasing the programmatic approach to image creation, which complements the web interface’s visual method.
Steps
- Set up your environment: — Ensure you have Python installed — Install the fal-client library:
pip install fal-client- Install Pillow for image handling:pip install Pillow - Obtain your API key: - Log in to your Fal AI account - Set your API key as an environment variable:
export FAL_KEY="YOUR_API_KEY"
3. Create a Python script (e.g., flux_dev_fal.py) with the following code:
import fal_client
import time
from PIL import Image
import requests
from io import BytesIO
# Submit a request to the FLUX.1 [dev] model
start_time = time.time()
handler = fal_client.submit(
"fal-ai/flux/dev",
arguments={
"prompt": "A serene lake surrounded by autumn trees at sunset",
"image_size": {
"width": 1024,
"height": 1024
},
"num_inference_steps": 28,
"guidance_scale": 3.5,
"num_images": 1,
"enable_safety_checker": True
},
)
# Get the result
result = handler.get()
print(result)
# Calculate and print the generation time
generation_time = time.time() - start_time
print(f"Image generated in {generation_time:.2f} seconds")
# Save the generated image
image_url = result['images'][0]['url']
response = requests.get(image_url)
img = Image.open(BytesIO(response.content))
img.save("generated_image.png")
print("Image saved as generated_image.png")4. Run the script:
python flux_dev_fal.py5. The script will output the result, including the URL of the generated image, the generation time (2.76 seconds inference time), and save the image locally

6. For comparison, we performed the same generation task on an A6000 GPU with the identical configuration using the code below, achieving a completion time of approximately 18 seconds.
import torch
from diffusers import FluxPipeline
import time
pipe = FluxPipeline.from_pretrained("black-forest-labs/FLUX.1-dev", torch_dtype=torch.bfloat16)
prompt = "A serene lake surrounded by autumn trees at sunset"
start_time = time.time()
image = pipe(
prompt,
height=1024,
width=1024,
guidance_scale=3.5,
num_inference_steps=28,
generator=torch.Generator("cpu").manual_seed(42)
).images[0]
generation_time = time.time() - start_time
print(f"Image generated locally in {generation_time:.2f} seconds")
image.save("flux-dev-local.png")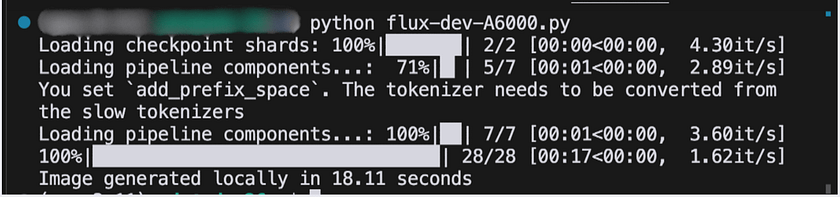
Fal AI’s API’s significantly faster performance (2.76 seconds vs. 18 seconds on an A6000) can be attributed to several factors. Fal AI likely employs advanced optimisation techniques, such as model quantization, parallel processing, and specialised hardware acceleration, which are fine-tuned for their specific infrastructure. Additionally, their cloud-based setup may utilise more powerful or specialised GPUs than a standard A6000. This performance advantage demonstrates the benefit of using a specialised, cloud-based AI service that can offer optimised inference times without the need for local high-end hardware or complex setup. However, it is important to note that actual performance may vary based on factors like network conditions, server load, and specific use cases.
Working Example 3: Building a Real-Time AI Application
Fal AI offers powerful real-time APIs that enable rapid image generation, allowing for interactive applications with near-instantaneous results. In this example, we’ll use a pre-built demo application to showcase the capabilities of Fal AI’s real-time image generation.
Steps
- Clone the demo repository
git clone https://github.com/fal-ai/real-time-demo-app.git
cd real-time-demo-app2. Install dependencies:
npm install3. Add your Fal AI API key to the .env.local file:
FAL_KEY=your_fal_api_key_here
4. Run the development server:
npm run dev5. Open your browser and navigate to http://localhost:3000 to see the application in action.
Fal AI’s real-time functionality, as demonstrated in this application, leverages advanced techniques to provide near-instantaneous image generation. Here’s how the real-time system works:
- WebSocket Connection: The
fal.realtimeclient establishes a persistent WebSocket connection between the user's browser and Fal AI's servers. This connection allows for continuous, bidirectional communication, which is crucial for real-time interactions. - Streaming Inference: Unlike traditional API calls where the entire process must be completed before sending a response, Fal AI uses a streaming inference approach. This means the AI model can start sending partial results as soon as they’re available, rather than waiting for the entire image to be generated.
- Efficient State Management: The
fal.realtimeclient manages the state of the generation process, handling updates smoothly without requiring the entire page to reload or the connection to be re-established for each change.
This real-time capability opens up new possibilities for interactive AI applications, enabling experiences that feel more like natural, instantaneous interactions rather than discrete query-and-response cycles. Developers can leverage this technology to create highly responsive AI-powered tools for a wide range of applications, from creative design assistants to dynamic content generation systems.
Working Example 4: Deploying a Custom AI Model (Currently Beta Test Only)
Fal AI allows developers to deploy custom AI models using serverless functions (An Admin API Key is required to access this feature). This approach enables you to run your own models in a scalable, cloud-based environment. In this example, we’ll deploy a simple custom image classification model using PyTorch and demonstrate how to use it through Fal AI’s API.
Steps
- Set up your environment: Install the fal library
pip install fal - Create a new Python file (e.g.,
custom_sd_model.py) with the following code:
import fal
from pydantic import BaseModel
from fal.toolkit import Image
class Input(BaseModel):
prompt: str
class Output(BaseModel):
image: Image
class CustomSDModel(fal.App, keep_alive=300):
machine_type = "GPU-A100"
requirements = [
"diffusers==0.28.0",
"torch==2.3.0",
"accelerate",
"transformers",
]
def setup(self):
import torch
from diffusers import StableDiffusionXLPipeline, DPMSolverSinglestepScheduler
self.pipe = StableDiffusionXLPipeline.from_pretrained(
"sd-community/sdxl-flash",
torch_dtype=torch.float16,
).to("cuda")
self.pipe.scheduler = DPMSolverSinglestepScheduler.from_config(
self.pipe.scheduler.config,
timestep_spacing="trailing",
)
@fal.endpoint("/")
def generate(self, request: Input) -> Output:
result = self.pipe(request.prompt, num_inference_steps=7, guidance_scale=3)
image = Image.from_pil(result.images[0])
return Output(image=image)
if __name__ == "__main__":
fal.run(CustomSDModel)3. Deploy your model:
fal deploy custom_sd_model.py::CustomSDModel
4. After deployment, Fal AI will provide you with an API endpoint. You can use this endpoint to generate images:
import requests
API_URL = "https://fal.run/your-user-id/custom-sd-model" # Replace with your actual URL
API_KEY = "your_fal_api_key"
headers = {
"Authorization": f"Key {API_KEY}",
"Content-Type": "application/json"
}
data = {
"prompt": "A serene lake surrounded by autumn trees at sunset"
}
response = requests.post(API_URL, json=data, headers=headers)
print(response.json())This example demonstrates deploying a custom Stable Diffusion model as a Fal AI private serverless function. The CustomSDModel class, inheriting from fal.App, is configured to run on a GPU-A100 with specific Python package requirements. It utilises a setup() method for model initialisation, implements a keep_alive feature to reduce cold starts, and exposes an API endpoint via the @fal.endpoint("/") decorator. The model is deployed using a simple fal deploy command, leveraging Fal AI's GPU infrastructure.
By using Fal AI, developers gain access to scalable GPU resources without managing hardware. This approach simplifies deployment, offers automatic scaling, and integrates with Fal AI’s monitoring tools. It enables efficient deployment of custom AI models like Stable Diffusion, combining the power of sophisticated AI with the convenience of cloud-based services.
Comparison with Alternatives
Fal AI distinguishes itself from traditional cloud providers like AWS, GCP, or Azure by offering a more streamlined, AI-focused platform. While these larger providers offer extensive customisation and a broader range of services, Fal AI provides a more specialised, user-friendly experience tailored specifically for AI model deployment. Unlike platforms such as Hugging Face, which primarily focus on model sharing and collaboration, Fal AI emphasises rapid deployment and scalable inference. This makes Fal AI particularly suitable for developers who need to quickly operationalise AI models without deep infrastructure expertise.
Compared to other AI-specific platforms like Replicate or Banana, Fal AI stands out with its real-time capabilities and optimised performance for certain models. Fal AI’s approach to serverless deployment is similar to services like AWS Lambda or Google Cloud Functions but with a specific focus on AI workloads and pre-optimised environments for popular AI frameworks. This specialisation allows for faster deployment times and potentially better performance for AI tasks. However, it’s worth noting that Fal AI may offer less flexibility for non-AI workloads compared to more general-purpose cloud platforms.
Conclusion
Fal AI offers a compelling solution for developers seeking to deploy AI models, particularly for real-time applications. Its streamlined approach simplifies the deployment process, provides optimised performance for AI workloads, and offers scalable infrastructure without the complexity of managing traditional cloud resources. While it may not match the breadth of services offered by major cloud providers, Fal AI’s focus on AI-specific needs makes it an attractive option for teams looking to quickly operationalise their models. As AI continues to evolve, platforms like Fal AI are poised to play a crucial role in democratizing access to advanced AI capabilities, enabling developers to bring innovative AI-powered applications to market more efficiently.
References
[1] Future Tools. Fal AI. View Tool.
[2] Fal AI. Documentation. View Docs.
[3] Fal AI. Blog. View Blog.
[4] Fal AI. Real-Time Demo App Repository. View GitHub.
Catch the latest version of this article over on Medium.com. Hit the button below to join our readers there.






















