

Ministral — The World’s Best Edge Language Model
Revolutionising On-Device AI: High-Performance, Low-Resource Language Models for Edge Computing
- •

Introduction
In recent years, there’s been a notable shift in the AI landscape, with many companies moving away from developing massive, compute-intensive models towards building smaller, more efficient alternatives. The demand for these compact models stems from the desire to make AI more accessible and practical, particularly in environments where computational resources and power are limited. Unlike their larger counterparts that require substantial server infrastructure, these models can run efficiently on local devices, such as smartphones, edge servers, IoT devices, and other hardware, making them ideal for real-time, on-device applications.
This trend has been driven by several key factors. First, the need for latency reduction is crucial in many AI-driven applications, from autonomous vehicles to real-time language translation, where even a few milliseconds of delay can significantly impact performance. Smaller models allow inference to happen closer to the user or device, eliminating the need to send data to and from a remote server, thus reducing response times and improving user experiences.
Second, cost efficiency is a major consideration. Running large models typically requires expensive cloud infrastructure and high GPU costs, making them less practical for widespread deployment. In contrast, smaller models can be deployed across a larger number of devices without incurring significant overhead, making AI solutions more scalable and sustainable, particularly for startups and companies with tighter budgets.
Moreover, privacy and data security are increasingly critical in today’s data-driven world. By deploying models directly on devices rather than relying on remote servers, companies can ensure that sensitive data remains on the local device, mitigating the risks associated with data transmission and storage in centralised databases. This is particularly advantageous for applications in healthcare, finance, and other fields where data privacy is paramount.
Keeping all these in mind, let us learn about Mistral’s latest innovations!
A Deep Dive Into Ministral
What is Ministral?
On the first anniversary of the release of Mistral 7B, a model that transformed independent frontier AI innovation for millions, the Mistral AI team introduced two new state-of-the-art models on October 16, 2024 — described by their creators as “the world’s best edge models” — for on-device computing and edge use cases: Ministral 3B and Ministral 8B. These two models, with 3 billion and 8 billion parameters respectively (significantly fewer than most of their counterparts), are setting a new standard in the sub-10B parameter space, offering unmatched capabilities in knowledge integration, commonsense reasoning, function-calling, and efficiency.
Features of Ministral
The Ministral 3B and 8B models come equipped with a range of advanced features that make them ideal for a variety of edge computing applications. Here’s a closer look at what sets these models apart:
1. Versatility and Efficiency
Ministral 3B and 8B are designed to handle a wide range of applications, from orchestrating complex workflows to performing highly specialised tasks. Their versatile nature means they can be easily adapted to various industry needs, making them suitable for both everyday users and enterprise-level applications. This flexibility allows them to power solutions across different domains, including natural language processing, automation, and task-specific models, providing effective performance without the need for large, resource-intensive servers.
2. Extended Context Lengths
Both models support context lengths of up to 128k tokens, allowing them to manage and process significantly longer inputs than many other models in their class. This capability is particularly useful for applications like document analysis, long-form conversations, and any scenario where maintaining extended context is crucial. Currently, this capability is available up to 32k through vLLM, an optimised library for running large language models (LLMs) efficiently. By leveraging vLLM, Ministral 3B and 8B provide users with deeper understanding and continuity over longer interactions, which is essential for advanced natural language understanding and generation.
3. Innovative Interleaved Sliding-Window Attention (Ministral 8B)
A standout feature of Ministral 8B is its interleaved sliding-window attention mechanism. This technique optimises memory usage and processing speed by dividing the input sequence into overlapping windows that are processed iteratively. As a result, the model can perform inference more efficiently, making it ideal for edge AI deployments where computational resources are limited. This feature ensures that Ministral 8B maintains a balance between high-speed processing and the ability to handle large contexts without demanding excessive memory, making it a perfect choice for real-time applications.
4. Local, Privacy-First Inference
Responding to growing demand from customers for privacy-conscious AI solutions, Ministral 3B and 8B are built with local, privacy-first inference capabilities in mind. This makes them ideal for applications where data security is critical, such as on-device translation, internet-less smart assistants, local analytics, and autonomous robotics. By running models directly on local devices, users can ensure that sensitive data remains on-site, reducing risks associated with transmitting data to cloud servers and enhancing overall security.
5. Compute-Efficient and Low-Latency Solutions
One of the core strengths of les Ministraux is their ability to deliver compute-efficient and low-latency AI solutions. This means they can provide quick responses and maintain high performance even on devices with limited hardware capabilities. Whether it’s independent hobbyists working on personal projects or large-scale manufacturing teams optimising automated processes, Ministral 3B and 8B offer a scalable solution that can meet a wide variety of needs without the burden of heavy computational resources.
6. Efficient Intermediaries for Function-Calling
When used alongside larger language models like Mistral Large, Ministral 3B and 8B serve as efficient intermediaries for function-calling in complex, multi-step workflows. They can be fine-tuned to handle specific tasks such as input parsing, task routing, and API calls based on user intent, ensuring that multi-step processes are executed seamlessly. With their low latency and low cost, they enable faster interactions and better resource management in scenarios where complex agentic workflows are required.
Together, these features make Ministral 3B and Ministral 8B powerful tools in the evolving world of edge AI. By offering a blend of versatility, efficiency, and advanced context management, they cater to the diverse needs of users, from individuals looking for practical on-device AI solutions to enterprises seeking scalable, privacy-first AI deployments.
Ministral’s Benchmarking Performances
The Ministral AI team has shared how Ministral 3B and Ministral 8B perform on industry-standard benchmarks, pitting them against other leading models in their category. This detailed comparison highlights how these models excel in various tasks, providing compelling reasons to choose Ministral as your AI companion for on-device and edge applications.
Pretrained Models
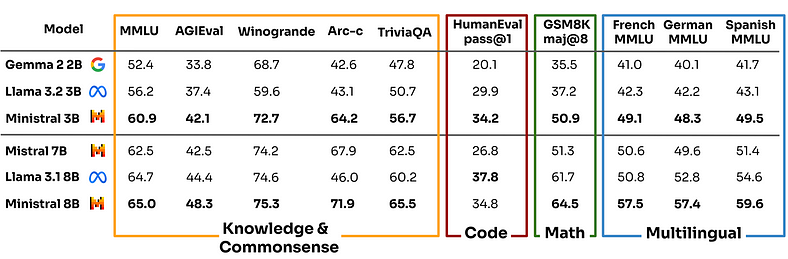
The graph above showcases the strengths of Ministral 3B and 8B against other models like Llama 3.2 3B and Mistral 7B, emphasising their ability to deliver robust performance despite their compact size. Their efficiency in handling various benchmarks makes them an ideal choice for users who prioritise performance without the need for large-scale infrastructure.
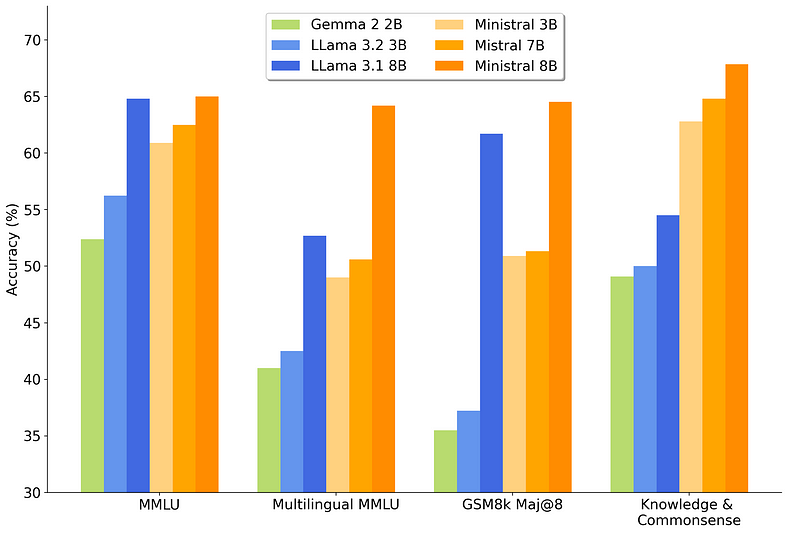
This chart further demonstrates how Ministral 3B and 8B stack up against similar models, showing their strengths in key categories, from language understanding to task-specific performance. These results highlight why Ministral’s models are among the top choices for users looking for compact yet capable AI models.
Instruct Models
Instruct models are fine-tuned versions of language models designed to better understand and follow user instructions, making them highly effective for interactive applications like chatbots, customer service automation, and more.
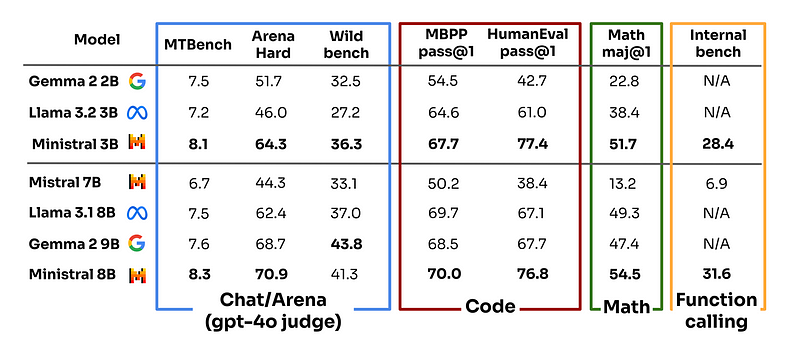
The above comparison shows how Ministral’s Instruct models excel in multiple evaluation categories, providing a more responsive and accurate experience in user interactions. They stand out for their ability to understand nuanced instructions, making them a strong choice for applications that require precise interpretation and action.
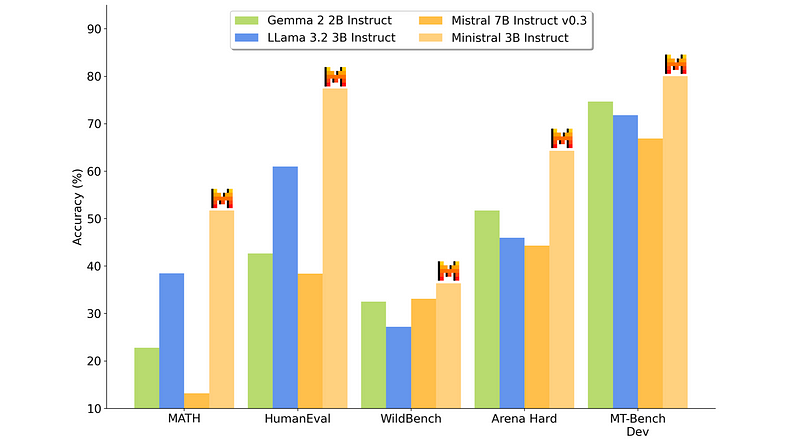
This figure highlights the efficiency of Ministral 3B compared to other 3B models, showing how it even outperforms the larger Mistral 7B in some cases. This makes Ministral 3B a compelling option for those seeking strong performance without the larger computational footprint.
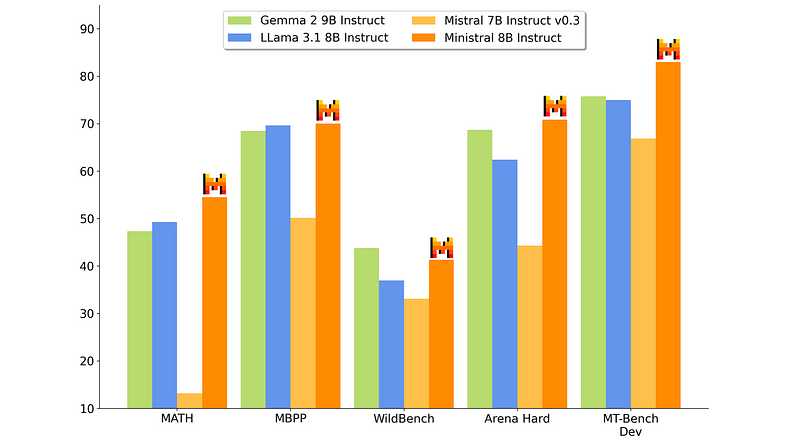
This final chart focuses on the 8B Instruct models, with Ministral 8B proving to be a strong competitor against larger models like Gemma 2 9B and Mistral 7B. Its ability to deliver high performance with fewer parameters showcases its efficiency, making it ideal for real-world applications that require a balance of speed, accuracy, and cost-effectiveness.
Availability and Pricing
Both Ministral 3B and Ministral 8B are available starting today, providing users with flexible access options tailored to their needs.

The pricing is designed to make Ministral models accessible for various applications, with Ministral 8B priced at $0.1 per million tokens and Ministral 3B at $0.04 per million tokens. Both input and output tokens are counted, providing cost-effective options for developers looking to integrate advanced AI capabilities into their projects.
For users interested in self-deployed models, the Mistral AI team offers direct support through their contact page. This support includes assistance with commercial licensing and lossless quantization of the models, ensuring that they can be tailored to specific use cases and deliver maximum performance for deployment.
Additionally, the model weights for Ministral 8B Instruct are available for research use through Hugging Face, providing researchers with access to advanced AI capabilities. For those looking to deploy the models in a cloud environment, Ministral 3B and Ministral 8B will soon be available through Mistral’s cloud partners, offering a seamless integration path for businesses and developers.
These flexible access options and support for both commercial and research use make Ministral 3B and 8B accessible to a wide range of users, from individual researchers to large enterprises looking to leverage the power of state-of-the-art edge models.
How to Use the Ministral API
Ministral 3B and Ministral 8B models can be easily integrated into your applications using their API through la Plateforme — Mistral’s cloud-based service for accessing and deploying advanced AI models. This platform enables developers to leverage the power of Ministral models for a variety of tasks, from natural language processing to custom AI solutions, with simple API calls.
Here’s a step-by-step guide on how to get started with the Ministral API:
1. Sign Up for Access
To get started, you first need to create an account on la Plateforme. Visit the la Plateforme sign-up page and register for an account. Once registered, you’ll have access to the documentation, API keys, and other resources necessary to integrate the Ministral 3B and 8B models into your application.
2. Obtain API Keys
After signing up, navigate to your API settings within the platform dashboard to generate your API key. This key is required for authenticating your requests to the Ministral API. Keep this key secure, as it provides access to the models and tracks your usage.
3. Make API Requests
Using the API is straightforward. Below is a basic example of how to make a request using curl or any programming language that supports HTTP requests:
curl -X POST "https://api.mistral.ai/v1/ministral-8b-latest" \
-H "Authorization: Bearer YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{ "input": "What are the benefits of using Ministral models?", "max_tokens": 150 }'
Replace YOUR_API_KEY with your API key and customise the input with your desired prompt. The response will contain the model’s generated output, providing you with an easy way to integrate Ministral 8B or 3B capabilities into your applications.
4. Choose the Right Model
The API allows you to specify the model you want to use by indicating the model name in your request. For example:
- To use Ministral 3B, use the model identifier
ministral-3b-latest. - To use Ministral 8B, use the model identifier
ministral-8b-latest.
This flexibility allows you to select the model that best fits your application’s needs based on factors like response time and token limits.
5. Manage Usage and Monitor Costs
- Through la Plateforme’s dashboard, you can monitor your API usage and track costs. This helps you stay within your budget by understanding how many tokens are being processed and adjusting your usage accordingly. You can view metrics such as token usage per day and estimated costs, making it easier to manage and scale your AI integration.
6. Get Support for Advanced Use-Cases
- For businesses looking to deploy the models at scale or for specific use-cases, Mistral AI offers support through their contact page. This includes help with lossless quantization, optimizing the models for deployment, and integrating them into custom workflows.
With la Plateforme, integrating advanced AI capabilities into your products has never been easier. Whether you are developing a chatbot, creating automated content, or analysing large volumes of text, the Ministral API provides a robust and flexible solution for leveraging state-of-the-art AI directly in your applications.
Using Ministral-8B with vLLM: Python Implementation Guide
The Ministral-8B-Instruct-2410 is a fine-tuned language model optimised for instruction-based tasks, available through Hugging Face. When deployed using vLLM, an optimised library for efficient large language model inference, it offers powerful capabilities and low-latency performance. Here’s how you can get started with integrating Ministral-8B using vLLM:
Installation
To begin, ensure you have the latest versions of vLLM and mistral_common installed:
pip install --upgrade vllm
pip install --upgrade mistral_commonNote: Make sure you are using vLLM version 0.6.2 or higher for compatibility with the Ministral-8B model.
Offline Usage with vLLM
For offline use, you can directly load and interact with Ministral-8B using the following Python code:
from vllm import LLM
from vllm.sampling_params import SamplingParams
# Specify the model
model_name = "mistralai/Ministral-8B-Instruct-2410"
sampling_params = SamplingParams(max_tokens=8192)
# Initialize the LLM with Mistral-specific configurations
llm = LLM(model=model_name, tokenizer_mode="mistral", config_format="mistral", load_format="mistral")
# Define a prompt and structure the request
prompt = "What are the potential implications of artificial intelligence on the job market in the next decade?"
messages = [
{
"role": "user",
"content": prompt
},
]
# Generate output
outputs = llm.chat(messages, sampling_params=sampling_params)
print(outputs[0].outputs[0].text)This script initialises the Ministral-8B model, sets up a prompt, and generates a response. It’s an ideal setup for local development or testing use cases where you need the model’s output without setting up a full server environment.
Server Mode Inference with vLLM
For more scalable deployment, you can run vLLM in server mode, which allows the model to handle multiple requests via a REST API. This is especially useful for integrating Ministral-8B into larger systems or applications:
- Start the vLLM server:
vllm serve mistralai/Ministral-8B-Instruct-2410 --tokenizer_mode mistral --config_format mistral --load_format mistral
2. Make API requests to the running server:
You can interact with the server using curl or any HTTP client. Here’s an example using curl:
curl --location 'http://localhost:8000/v1/chat/completions' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer token' \
--data '{
"model": "mistralai/Ministral-8B-Instruct-2410",
"messages": [
{
"role": "user",
"content": "What are the potential implications of artificial intelligence on the job market in the next decade?"
}
]
}'This setup allows for real-time inference and supports concurrent connections, making it suitable for production use where multiple users or systems need access to Ministral-8B’s capabilities.
Important Notes on vLLM Usage
- Context Size Limitations: vLLM currently supports a maximum context size of 32k tokens. This is due to constraints in implementing interleaved attention kernels for paged attention. If you need to leverage the full 128k context size of Ministral-8B, consider using Mistral Inference directly from their GitHub repository.
- Optimising Memory Usage: For deployments where GPU memory is a constraint, you can reduce the memory footprint by using tensor parallelism. Add
tensor_parallel=2to the LLM initialisation to distribute the workload across multiple GPUs.
# Initialize the LLM with Mistral-specific configurations and tensor parallelism
llm = LLM( model=model_name, tokenizer_mode="mistral", config_format="mistral", load_format="mistral", tensor_parallel=2)
# Added tensor parallelism here to reduce GPU memory usageBy following these steps, you can seamlessly integrate Ministral-8B into your Python projects using vLLM. Whether you choose offline inference for localised tasks or server mode for scalable deployment, the combination of Ministral-8B’s advanced capabilities and vLLM’s optimised inference makes it a versatile solution for a wide range of AI applications.
Conclusion
The release of Ministral 3B and Ministral 8B marks a significant milestone in the evolution of edge AI, offering a powerful blend of compactness and capability. As AI continues to move closer to the devices we use daily, the need for models that can deliver high performance without relying solely on cloud resources becomes ever more critical. Ministral’s models embody this shift, providing the flexibility, efficiency, and advanced features that developers and enterprises alike require to stay competitive in an increasingly data-driven world.
These models are not just about numbers and benchmarks — they represent a reimagining of how AI can be integrated into our lives, making cutting-edge capabilities more accessible to those who need them. Whether you’re a researcher looking to explore the frontiers of AI with Ministral 8B Instruct or a developer seeking a practical, low-latency solution for real-time applications, Ministral 3B and 8B offer a versatile toolkit that adapts to a range of scenarios.
Moreover, with options like vLLM integration and comprehensive support for self-deployment, the Ministral AI team has ensured that these models are not just technically advanced but also user-friendly and adaptable to diverse environments. The emphasis on privacy-first, local inference adds another layer of value, especially in fields where data security and integrity are paramount.
As AI technology continues to advance, the importance of balancing power with practicality cannot be overstated. Ministral 3B and 8B have shown that it’s possible to maintain this balance, making AI not just a tool for the cloud but a companion for everyday devices. They stand as a testament to what can be achieved when innovation meets the needs of real-world applications, setting the stage for a new era of AI that is as close to us as the devices in our hands.
References
- Gautam Chutani. “Meet Ministral 3B and 8B: Edge AI Game-Changers — Gautam Chutani — Medium.” Medium, 17 Oct. 2024, gautam75.medium.com/meet-ministral-3b-and-8b-edge-ai-game-changers-3f7532da8f90. Accessed 22 Oct. 2024.
- “Un Ministral, Des Ministraux.” Mistral.ai, 16 Oct. 2024, mistral.ai/news/ministraux/. Accessed 22 Oct. 2024.
Catch the latest version of this article over on Medium.com. Hit the button below to join our readers there.






















