

Pixtral 12B — Mistral’s New Lightweight Multimodal Powerhouse
The Power and Versatility of Pixtral 12B
- •

Introduction
The production of multimodal models has surged in recent years, with companies racing to develop models that can seamlessly handle both text and image instructions with high accuracy. On September 17, 2024, Mistral introduced Pixtral, a lightweight yet powerful multimodal model that stands out from the crowd. Despite its smaller size, Pixtral delivers performance comparable to, and in some cases exceeding, larger models like LLaVa OneVision in standard benchmarking tests — all while requiring significantly fewer computational resources. In this article, we’ll dive into the standout features of Pixtral, explore some working examples, compare its performance with other leading multimodal models, and show how you can access and use this model.
A Deep Dive into Pixtral 12B
What is Pixtral 12B?
Pixtral 12B was designed to be a drop-in replacement for Mistral Nemo 12B, but what sets it apart is its ability to deliver top-notch multimodal reasoning without compromising on key text-based capabilities such as instruction following, coding, and math. Unlike many models that focus on either multimodal or text-based tasks, Pixtral excels at both, providing state-of-the-art performance on text-only benchmarks while also handling complex multimodal tasks with ease.
One of Pixtral’s standout features is its natively multimodal architecture, trained using interleaved image and text data. This allows the model to perform exceptionally well in tasks requiring an understanding of both types of input. The model’s architecture includes a newly developed 400 million parameter vision encoder, built from scratch, and a 12 billion parameter multimodal decoder, inspired by Mistral Nemo. These components work together to support variable image sizes and aspect ratios, enabling Pixtral to efficiently process a wide range of visual data. Additionally, the model can handle multiple images simultaneously within its 128K token context window, offering a high degree of flexibility and performance.
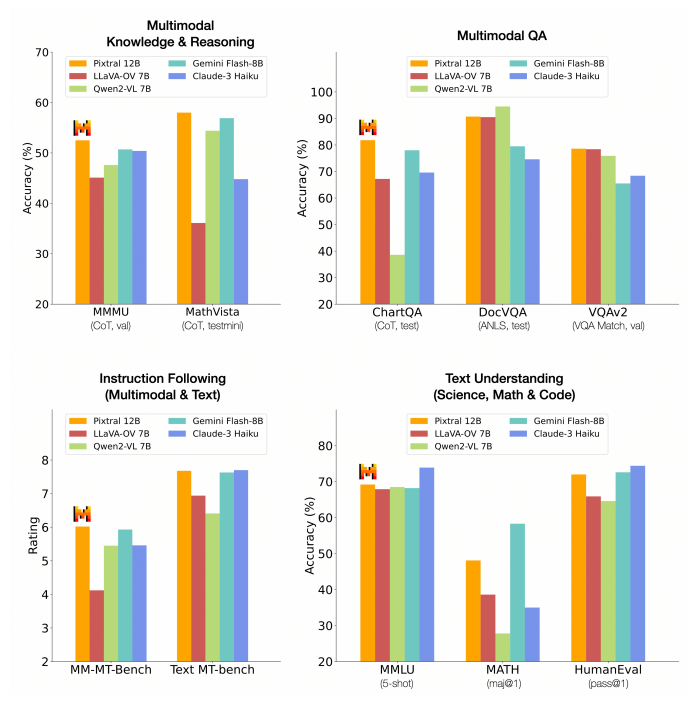
Pixtral’s training allows it to process both natural images and documents with remarkable precision, achieving an impressive 52.5% on the MMMU reasoning benchmark, surpassing several larger models. It shows strong abilities in tasks such as chart and figure understanding, document question answering, multimodal reasoning, and instruction following. Importantly, Pixtral allows users to ingest images at their natural resolution and aspect ratio, ensuring that the processing remains efficient and flexible regardless of the image size. Perhaps most crucially, Pixtral achieves all of this without sacrificing its performance on text benchmarks, a rare feat in the world of multimodal models.
Now that we’ve briefly seen what Pixtral is about, let us look at some of its working examples to give you more of a reason to run this powerful model!
Working Examples
1. Natural Scene Understanding
Natural Scene Understanding (NSU) refers to the ability of an AI or machine learning model to interpret and analyse complex, real-world images or scenes in a way that mimics human perception. This involves recognising objects, understanding their spatial relationships, identifying actions or events occurring in the scene, and deriving meaningful information from these elements.
With this definition in mind, let’s look at an example of how Pixtral excels at NSU.

Pixtral was provided with the image above and the following prompt:
Is this person really big, or is this building just super small?
Pixtral responded with the following generated content:
The image shows a person holding their thumb in front of the Leaning Tower of Pisa, making it appear as if the thumb is much larger than the tower. This creates an optical illusion, making the tower seem smaller than it actually is. In reality, the Leaning Tower of Pisa is a large and iconic structure, and the person’s thumb is not nearly as large as it appears in the image. The purpose of this photo is to demonstrate the impressive height and size of the tower by comparing it to a familiar object, such as a thumb.
From the above response, we can see that Pixtral is not easily misled by the proximity of objects in the image, showcasing its proficiency in NSU tasks.
2. Image to Code
Let us now see if Pixtral is able to design a webpage based on a hand-drawn image of the desired webpage result. This would require the model to first interpret what was drawn and then showcase its ability to provide accurate code as well. Given that this model is meant to be a replacement for Mistral Nemo 12B, its text generation capabilities (in this case, code generation) should ideally be very strong.

The Mistral team provided the above image along with the following prompt:
Write HTML code to create a website like this
This was the response generated by the Pixtral model:
Certainly! Below is an example of HTML code to create a simple webpage that allows users to pick an ice cream flavor. This example includes a dropdown menu for selecting the flavor and a "Next" button.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Pick an Ice Cream Flavor</title>
<style>
body {
font-family: Arial, sans-serif;
display: flex;
justify-content: center;
align-items: center;
height: 100vh;
background-color: #f0f0f0;
}
.container {
background: white;
padding: 20px;
border-radius: 8px;
box-shadow: 0 0 10px rgba(0, 0, 0, 0.1);
}
h1 {
text-align: center;
}
select {
width: 100%;
padding: 10px;
margin-top: 10px;
margin-bottom: 20px;
}
button {
width: 100%;
padding: 10px;
background-color: #4CAF50;
color: white;
border: none;
border-radius: 4px;
cursor: pointer;
}
button:hover {
background-color: #45a049;
}
</style>
</head>
<body>
<div class="container">
<h1>Pick An Ice Cream Flavor</h1>
<select id="flavorSelect">
<option value="vanilla">Vanilla</option>
<option value="chocolate">Chocolate</option>
<option value="strawberry">Strawberry</option>
<option value="cookie_dough">Cookie Dough</option>
<option value="mint_chocolate">Mint Chocolate</option>
</select>
<button onclick="next()">Next</button>
</div>
<footer style="position: fixed; bottom: 0; width: 100%; text-align: center; font-size: 12px;">
© copyright MistralAI
</footer>
<script>
function next() {
const selectedFlavor = document.getElementById('flavorSelect').value;
alert('You selected: ' + selectedFlavor);
}
</script>
</body>
</html>If this code is pasted into an HTML file and opened in a web browser, you will see the result below, which is quite similar to the hand-drawn requirements.
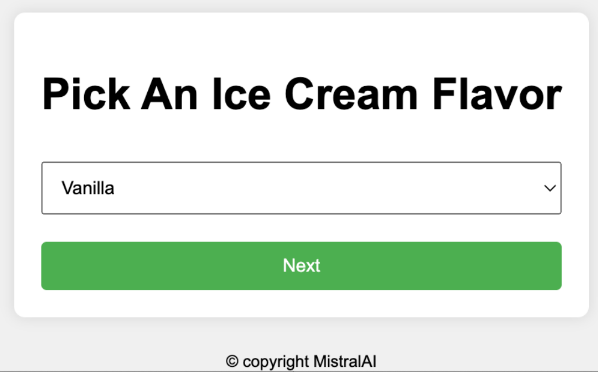
3. Chart Understanding and Analysis
Let’s look at a more demanding visual task where Pixtral is required to understand a chart (in this case, trends) and answer a question.
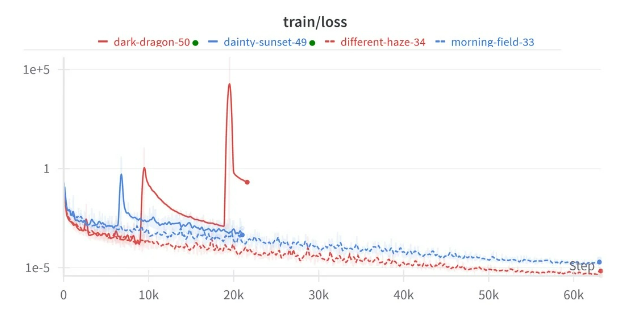
The following prompt was provided with the image above:
When did things start to go wrong for dark dragon?
Pixtral generated the following response:
The image is a line graph titled 'train/loss' that shows the training loss over steps for four different models: dark-dragon-50, dainty-sunset-49, different-haze-34, and morning-field-33. The x-axis represents the steps, ranging from 0 to 60k, and the y-axis represents the loss on a logarithmic scale from 1e-5 to 1e+5.
To determine when things started to go wrong for the dark-dragon-50 model, we need to look at the red line representing this model. Initially, the loss decreases, indicating that the model is learning effectively. However, around the 10k step mark, the loss starts to spike significantly. This spike indicates that the model's performance is deteriorating. The loss continues to spike and fluctuate, reaching very high values, which suggests that the model is not learning effectively and is likely overfitting or encountering other issues.
Therefore, the critical point where things started to go wrong for the dark-dragon-50 model is around the 10k step mark.
This response showcases how Pixtral can accurately perform complex visual interpretation tasks.
Pixtral’s Features
Now that we’ve seen some working examples, let us look under the hood at what makes Pixtral tick.
1. Evaluation Protocol
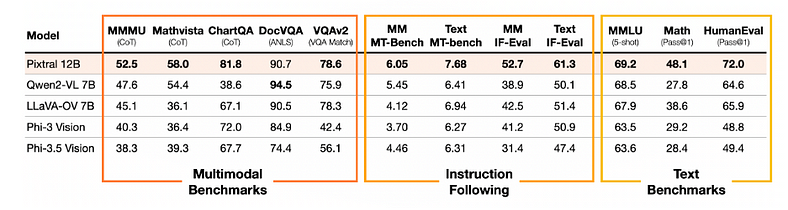
In evaluating a range of open and closed models, Pixtral 12B was tested using a standardised evaluation harness. This harness serves as a controlled framework that ensures all models are assessed under the same conditions, using the same datasets, task prompts, and performance metrics. By applying the same prompts, which were carefully selected to reproduce the results of leading multimodal models like GPT-4o and Claude-3.5-Sonnet, the evaluation harness allows for a fair and consistent comparison. Pixtral consistently outperformed all open models of its scale and, in many cases, exceeded the performance of closed models such as Claude 3 Haiku. It even matched or surpassed much larger models like LLaVa OneVision 72B on key multimodal benchmarks. Importantly, the methodology and prompts used in this evaluation are open-sourced and available in Mistral’s technical report of Pixtral, ensuring transparency and reproducibility of the results.
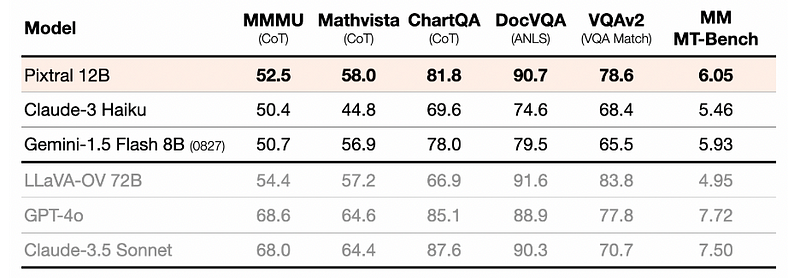
2. Instruction Following
Pixtral 12B demonstrates exceptional performance in both multimodal and text-only instruction following, significantly outperforming other open multimodal models. When compared to models such as Qwen2-VL 7B, LLaVa-OneVision 7B, and Phi-3.5 Vision, Pixtral achieved a 20% relative improvement in benchmarks like IF-Eval and MT-Bench, highlighting its superior instruction-following capabilities. All models were benchmarked using the same evaluation harness and with the same prompts, ensuring a fair and consistent comparison. To further assess its performance in multimodal tasks, specific benchmarks — MM-IF-Eval and MM-MT-Bench — were created. On these multimodal instruction-following benchmarks, Pixtral once again surpassed its open-source counterparts, solidifying its position as a leader in this space.
3. Architecture
Pixtral’s architecture is designed to optimise for both speed and performance, particularly in handling variable image sizes. The model uses a newly developed vision encoder that processes images at their native resolution and aspect ratio, converting them into image tokens for each 16x16 patch in the image. These tokens are then flattened into a sequence, with special markers like [IMG BREAK] and [IMG END] to indicate rows and the end of the image. This system allows Pixtral to distinguish between images with different aspect ratios even if they use the same number of tokens. This architecture is particularly useful for understanding complex diagrams, charts, and high-resolution documents, while also enabling fast inference speeds for smaller images such as icons, clipart, and equations.
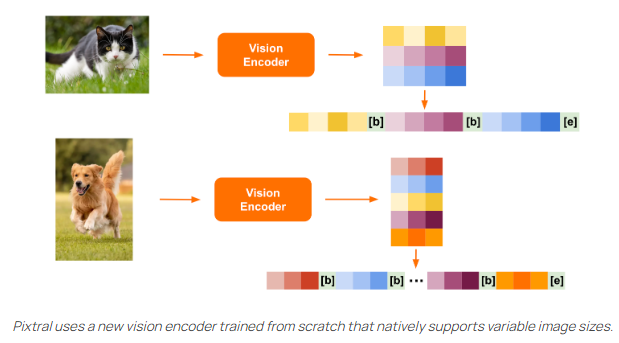
The final architecture of Pixtral consists of two main components: the Vision Encoder, which tokenizes images, and the Multimodal Transformer Decoder, which predicts the next text token based on a sequence of text and images. This flexible design allows Pixtral to handle images of arbitrary sizes in its large 128K token context window, ensuring high performance across a variety of tasks.
How to run Pixtral?
Now that we’ve talked about what makes Pixtral the powerhouse it is, let’s get down to the fun part: how can you actually run this model? Don’t worry, it’s a piece of cake!
1. Le Chat
First up, we’ve got Le Chat — Pixtral’s super easy-to-use, conversational chat interface. Just hop on, select Pixtral from the model list, upload an image, and start asking your questions. It’s that simple. Try it out here.

2. La Plateforme
Looking for something a little more customisable? Enter La Plateforme. You can tap into Pixtral’s capabilities through API calls, which makes it a breeze to integrate into your own apps and workflows. Here’s a little example to get you started:
curl https://api.mistral.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $MISTRAL_API_KEY" \
-d '{
"model": "pixtral-12b-2409",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "What’s in this image?"
},
{
"type": "image_url",
"image_url": "https://tripfixers.com/wp-content/uploads/2019/11/eiffel-tower-with-snow.jpeg"
}
]
}
],
"max_tokens": 300
}'3. Running Locally with Mistral Inference
If you’re feeling like rolling up your sleeves and getting your hands dirty with some code, you can run Pixtral locally using mistral-inference. Here’s the gist of it: install mistral_inference, download the model, and you’re good to go. Here’s a snippet to get you started:
# download the model
from huggingface_hub import snapshot_download
from pathlib import Path
mistral_models_path = Path.home().joinpath('mistral_models', 'Pixtral')
mistral_models_path.mkdir(parents=True, exist_ok=True)
snapshot_download(repo_id="mistralai/Pixtral-12B-2409", allow_patterns=["params.json", "consolidated.safetensors", "tekken.json"], local_dir=mistral_models_path)
# load the model
from mistral_inference.transformer import Transformer
from mistral_inference.generate import generate
from mistral_common.tokens.tokenizers.mistral import MistralTokenizer
from mistral_common.protocol.instruct.messages import UserMessage, TextChunk, ImageURLChunk
from mistral_common.protocol.instruct.request import ChatCompletionRequest
tokenizer = MistralTokenizer.from_file(f"{mistral_models_path}/tekken.json")
model = Transformer.from_folder(mistral_models_path)
# Run the model
url = "https://huggingface.co/datasets/patrickvonplaten/random_img/resolve/main/yosemite.png"
prompt = "Describe the image."
completion_request = ChatCompletionRequest(messages=[UserMessage(content=[ImageURLChunk(image_url=url), TextChunk(text=prompt)])])
encoded = tokenizer.encode_chat_completion(completion_request)
images = encoded.images
tokens = encoded.tokens
out_tokens, _ = generate([tokens], model, images=[images], max_tokens=256, temperature=0.35, eos_id=tokenizer.instruct_tokenizer.tokenizer.eos_id)
result = tokenizer.decode(out_tokens[0])
print(result)4. vLLM
For those of you who are serious about cranking up throughput, vLLM is your go-to. It’s a great option for serving Pixtral locally while squeezing every bit of performance out of it. Here’s a quick and easy example:
from vllm import LLM
from vllm.sampling_params import SamplingParams
model_name = "mistralai/Pixtral-12B-2409"
sampling_params = SamplingParams(max_tokens=8192)
llm = LLM(model=model_name, tokenizer_mode="mistral")
prompt = "Describe this image in one sentence."
image_url = "https://picsum.photos/id/237/200/300"
messages = [
{
"role": "user",
"content": [{"type": "text", "text": prompt}, {"type": "image_url", "image_url": {"url": image_url}}]
},
]
outputs = llm.chat(messages, sampling_params=sampling_params)
print(outputs[0].outputs[0].text)Conclusion
Pixtral 12B stands as a significant advancement in the development of lightweight, multimodal AI models. Its ability to seamlessly process both images and text while maintaining state-of-the-art performance across diverse tasks is truly noteworthy. From natural scene understanding to instruction following and image-to-code generation, Pixtral not only competes with larger models but also serves as a highly capable successor to Mistral Nemo 12B.
The model’s versatility is one of its strongest attributes, excelling in both multimodal and text-based tasks with ease. Whether handling complex diagrams, documents, or everyday images, Pixtral proves its efficiency while requiring far fewer computational resources than its larger counterparts. This makes it an ideal choice for a wide range of users, from researchers and developers to AI enthusiasts. With options to use Le Chat for easy conversational interaction, La Plateforme for API integration, or local deployment using mistral-inference or vLLM, Pixtral offers flexibility for various use cases.
In an era where AI models are growing increasingly complex, Pixtral shows that efficiency and performance can go hand in hand. Its compact yet powerful design highlights the potential for AI to deliver high-quality results without the need for massive scale. Pixtral 12B is more than just a technical accomplishment — it represents a new direction for AI, emphasising optimised performance and usability in a way that pushes the boundaries of what’s possible in the field.
As we look ahead, it’s clear that models like Pixtral are paving the way for more efficient and powerful AI applications, reshaping the future of multimodal AI in exciting ways.
References
- AI, Mistral. “Announcing Pixtral 12B.” Mistral.ai, 17 Sept. 2024, mistral.ai/news/pixtral-12b/. Accessed 1 Oct. 2024.
Catch the latest version of this article over on Medium.com. Hit the button below to join our readers there.






















