

Qwen2 — Alibaba’s New Powerhouse Multimodal AI
- •

Introduction
In the ever-evolving landscape of artificial intelligence, staying ahead means constantly pushing the boundaries of what machines can do. Alibaba Group, a titan in global commerce and technology, has introduced their new groundbreaking AI model, Qwen2, poised to redefine how machines understand and interact with the world. This article explores the innovations behind Qwen2, its potential applications, and its impact on both the AI community and various industries.
Key Features of Qwen2
Qwen2 introduces several notable advancements in AI, underscoring its role as a leading model in the field. Here are the key features of Qwen2:
- Diverse Model Sizes: Qwen2 is available in five sizes, catering to various needs and applications: Qwen2–0.5B, Qwen2–1.5B, Qwen2–7B, Qwen2–57B-A14B, and Qwen2–72B. This range allows users to choose a model that best fits their computational resources and performance requirements.
- Multilingual Training: The model has been trained on data in 27 additional languages beyond English and Chinese. This extensive multilingual capability ensures robust performance across diverse linguistic contexts, making Qwen2 versatile for global applications.
- Benchmark Excellence: Qwen2 has achieved state-of-the-art performance across a wide array of standard industrial benchmark evaluations. This includes leading metrics in various AI tasks, demonstrating its advanced capabilities and reliability.
- Enhanced Coding and Mathematics Abilities: Significant improvements have been made in Qwen2’s performance in coding and mathematical problem-solving. These enhancements make it a powerful tool for applications that require precise and complex computational tasks.
- Extended Context Length: Qwen2 supports extended context lengths of up to 128,000 tokens with the Qwen2–7B-Instruct and Qwen2–72B-Instruct variants. This extended context capability allows the model to handle more extensive and intricate input data, enhancing its ability to manage large-scale information and maintain coherence over longer texts.
- Open Source Availability: To promote accessibility and collaboration, Qwen2 models have been open-sourced on Hugging Face and ModelScope. This move facilitates wider adoption and allows the community to contribute to and benefit from Qwen2’s capabilities.
Let’s dive into these key features and explore what makes Qwen2 so powerful!
The Qwen2 Model Series
The Qwen2 series represents a significant leap forward in AI model development, offering a range of base and instruction-tuned models that cater to diverse computational needs and applications. This series includes five distinct models: Qwen2–0.5B, Qwen2–1.5B, Qwen2–7B, Qwen2–57B-A14B, and Qwen2–72B. Each model in the series has been meticulously designed to balance performance and efficiency, and their features are summarised in the table below:
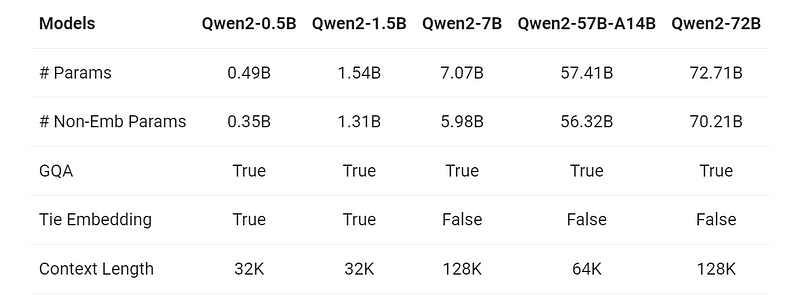
Model Variants and Specifications
The Qwen2 series is designed to cater to a range of computational demands and application scenarios. The models are available in several sizes, with parameter counts ranging from 0.49 billion to 72.71 billion. Each model also varies in terms of non-embedding parameters, context length support, and the application of advanced features such as Group Query Attention (GQA) and embedding tying.
- Group Query Attention (GQA): Previously limited to Qwen1.5–32B and Qwen1.5–110B, GQA is now implemented across all Qwen2 models. This is a technique used in large language models to speed up the inference time by grouping queries together and computing their attention collectively. This inclusion enhances the efficiency of model inference, reducing both speed and memory consumption, which is crucial for large-scale applications.
- Embedding Tying: In smaller models like Qwen2–0.5B and Qwen2–1.5B, embedding tying is utilised to manage the extensive sparse embeddings efficiently. It is a technique used in natural language processing (NLP) models, particularly in neural networks like transformers, to reduce the number of parameters in the model and improve efficiency. The idea behind embedding tying is to share the same set of parameters (weights) between the input embedding layer and the output projection layer. This approach helps in optimising parameter allocation, making the models more resource-efficient.
Context Length Capabilities
One of the notable advancements in the Qwen2 series is the extended context length support. While all base language models have been pretrained with a context length of 32,000 tokens, the instruction-tuned variants exhibit impressive capabilities. Specifically, the Qwen2–7B-Instruct and Qwen2–72B-Instruct models can handle context lengths of up to 128,000 tokens effectively, particularly when augmented with YARN technology. This extended context capability ensures that the models can understand and process longer texts with high accuracy, which is critical for complex tasks and detailed document analysis.
Multilingual Competence
A significant focus in the development of Qwen2 was enhancing its multilingual capabilities. The models have been trained on data from 27 additional languages beyond English and Chinese, reflecting a commitment to global applicability. The languages covered span various regions:
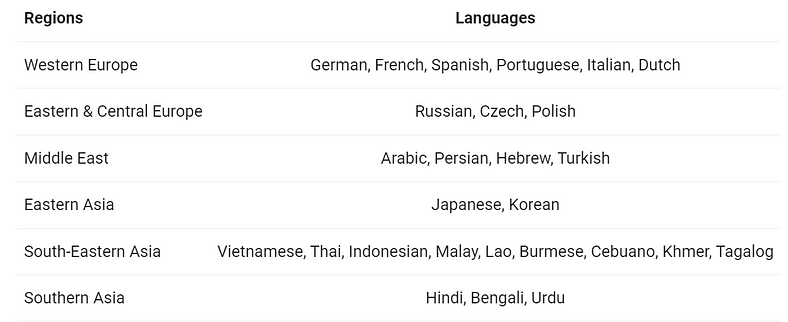
Furthermore, significant efforts were made to address code-switching which is the practice of alternating between two or more languages or varieties of language in conversation— a common phenomenon in multilingual contexts. The Qwen2 models have demonstrated enhanced proficiency in managing code-switching, reducing associated issues significantly. This improvement was validated through evaluations that tested the models’ responses to prompts likely to induce code-switching.
Performance
The Qwen2 series, particularly the Qwen2–72B model, represents a significant leap forward in AI performance compared to its predecessors and contemporary models. Here’s a detailed look at the performance enhancements and key features of Qwen2:
1. Superior Large-Scale Performance
Comparative assessments reveal that Qwen2–72B, with its 72 billion parameters, offers substantial performance improvements over previous models like Qwen1.5–110B, despite having fewer parameters. The evaluation of Qwen2–72B focuses on various capabilities, including natural language understanding, knowledge acquisition, coding proficiency, mathematical skills, and multilingual abilities. The model’s performance surpasses that of leading open models such as Llama-3–70B, showcasing its advanced capabilities in these areas.
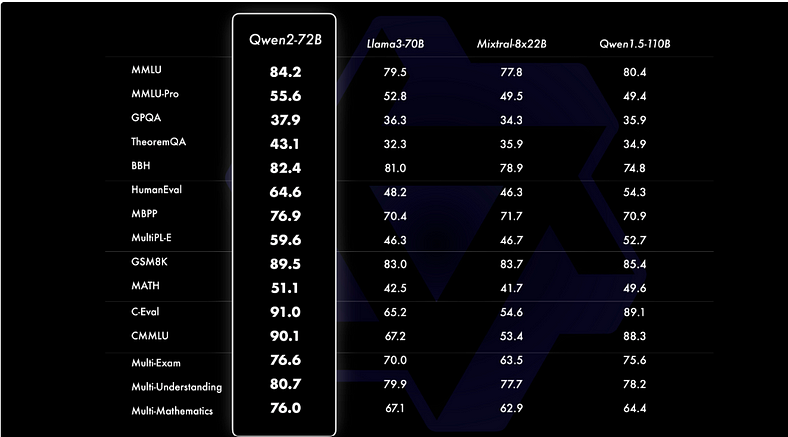
2. Enhanced Training Techniques
Qwen2 benefits from an extensive pre-training phase, followed by targeted post-training to refine its capabilities and align its outputs with human values. This process enhances the model’s performance in coding, mathematics, reasoning, instruction-following, and multilingual understanding. The post-training phase is designed to improve intelligence and ensure that the model remains helpful, honest, and harmless. Key techniques include:
- Automated Alignment Strategies: To obtain high-quality, diverse, and creative data, various automated alignment strategies are employed. The primary goal of alignment strategies is to ensure that different entities, such as sequences, models, or goals, are properly synchronised or matched according to certain criteria. For example, word alignment links words or phrases in a source language sentence to their corresponding words or phrases in the target language sentence. These include rejection sampling for mathematics, execution feedback for coding and instruction-following, back-translation for creative writing, and scalable oversight for role-play scenarios.
- Training Methods: A combination of supervised fine-tuning, reward model training, and online Direct Preference Optimization (DPO) training is used. Additionally, the novel Online Merging Optimizer minimizes alignment tax, further boosting model performance.
3. Benchmark Excellence
Qwen2–72B-Instruct has been evaluated across 16 benchmarks in various domains, demonstrating a strong balance between enhanced capabilities and alignment with human values. Notably, Qwen2–72B-Instruct significantly outperforms Qwen1.5–72B-Chat across all benchmarks and shows competitive performance compared to Llama-3–70B-Instruct. This indicates that Qwen2–72B-Instruct not only achieves superior results but also aligns well with user expectations and ethical standards.
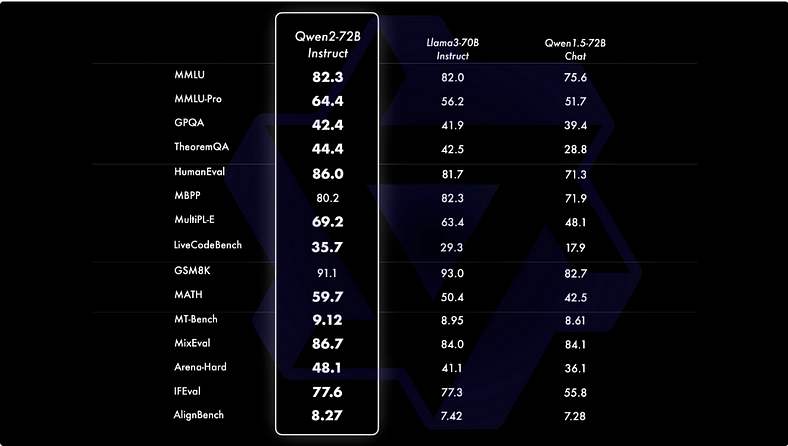
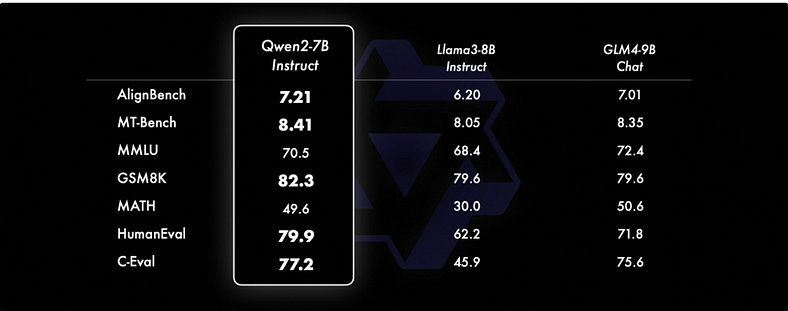
4. Impressive Results in Smaller Models
Even the smaller Qwen2 models, such as Qwen2–7B-Instruct, exhibit advantages over state-of-the-art models of similar or larger sizes. The Qwen2–7B-Instruct model shows outstanding performance, particularly in coding and Chinese-related metrics, outperforming several recently released state-of-the-art models. This demonstrates that Qwen2’s advancements extend across different model sizes, ensuring robust performance regardless of scale.
Coding & Mathematics
One of the standout features of Qwen2 is its exceptional performance in coding and mathematics. These areas have been a focal point of development, with continuous efforts to push the boundaries of what the model can achieve.
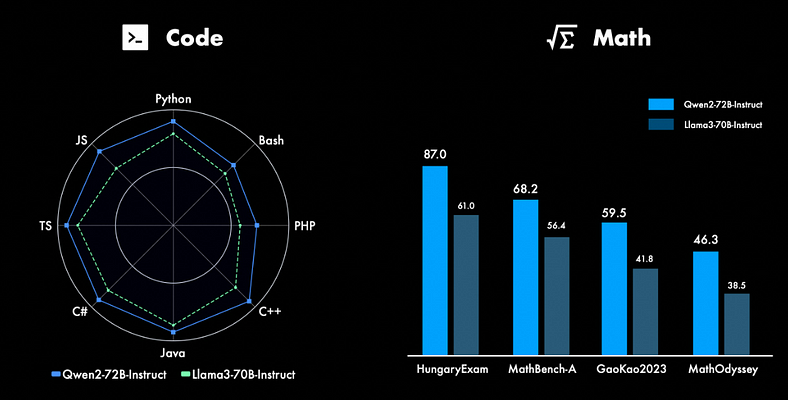
Advanced Coding Proficiency
In the realm of coding, Qwen2–72B-Instruct showcases significant advancements. Leveraging the code training experience and datasets from its predecessor, CodeQwen1.5, the model demonstrates improved performance across various programming languages. The integration of these high-quality resources has enabled Qwen2 to excel in coding tasks, making it a powerful tool for developers and engineers. Whether it’s generating code snippets, debugging, or understanding complex programming concepts, Qwen2–72B-Instruct stands out as a robust solution, delivering accurate and efficient results across diverse coding challenges.
Mathematical Mastery
Qwen2’s capabilities in mathematics have also seen remarkable enhancements. By utilising extensive and meticulously curated datasets, Qwen2–72B-Instruct has been trained to solve complex mathematical problems with greater accuracy and speed. The model’s ability to handle intricate calculations and mathematical reasoning tasks sets it apart from previous versions and many contemporary models. This improvement is particularly evident in tasks that require deep understanding and application of mathematical concepts, positioning Qwen2 as a leader in AI-driven mathematics solutions.
Long Context Understanding
Qwen2 stands out not just for its overall performance but also for its remarkable ability to understand and process long contexts, making it a powerful tool for tasks involving extensive textual data. The series has been designed to handle long-context scenarios with precision and efficiency, thanks to innovative training techniques.
Training for Extended Contexts
All instruction-tuned models in the Qwen2 series have been trained on contexts up to 32,000 tokens in length. However, what sets Qwen2 apart is its ability to extrapolate beyond this initial training context length, achieving even greater capacities through advanced techniques such as YARN (Yet Another Recursive Network) and Dual Chunk Attention. These methods allow the models to handle longer texts while maintaining their accuracy and coherence.
Performance Across the Series
The flagship model, Qwen2–72B-Instruct, excels in long-context understanding. In tests like the Needle in a Haystack task, which involves extracting specific information from a vast amount of data, Qwen2–72B-Instruct flawlessly handles contexts up to 128,000 tokens. This capability, combined with its strong inherent performance, makes it the go-to choice for tasks that require processing lengthy documents or datasets, especially when ample computational resources are available.
Other models in the Qwen2 series also exhibit impressive long-context capabilities:
- Qwen2–7B-Instruct: Nearly matches the flagship’s performance, managing contexts up to 128,000 tokens with impressive accuracy.
- Qwen2–57B-A14B-Instruct: Handles contexts up to 64,000 tokens, offering a robust solution for medium-length text tasks.
- Smaller Models: Both Qwen2–0.5B and Qwen2–1.5B support contexts up to 32,000 tokens, making them suitable for shorter documents while still benefiting from the series’ advanced training techniques.
Scaling Up: Processing Massive Documents
Beyond the long-context models, Qwen2 also includes an open-sourced agent solution capable of efficiently processing documents containing up to 1 million tokens. This solution is ideal for handling exceptionally large texts or datasets, offering scalability and efficiency in a variety of applications. For those interested in exploring this capability further, more detailed information is available in our dedicated blog post.
Overall, Qwen2’s mastery of long-context understanding significantly expands its applicability, making it an invaluable tool for tasks that involve processing and analysing extensive textual information.
Safety and Responsibility
Safety and responsibility are at the core of the Qwen2 series, with particular emphasis on reducing harmful outputs and ensuring the model’s alignment with ethical standards. The performance of Qwen2–72B-Instruct in this regard is a testament to Alibaba’s commitment to creating AI that is not only powerful but also responsible.
Evaluation of Harmful Responses
To assess the safety of Qwen2–72B-Instruct, a series of tests were conducted using multilingual unsafe queries across four key categories: Illegal Activity, Fraud, Pornography, and Privacy Violations. The test data, derived from Jailbreak and translated into multiple languages, provided a rigorous evaluation of the model’s ability to handle potentially harmful prompts.
The results, presented in the table below, demonstrate that Qwen2–72B-Instruct performs comparably to GPT-4 in terms of safety, particularly in its ability to avoid generating harmful responses across different languages. This is a significant achievement, especially when considering that many large-scale models struggle with multilingual safety. For instance, Llama-3, despite its strengths in other areas, was excluded from this comparison due to its inadequate handling of multilingual prompts.
Comparison with Other Models
In direct comparison with other leading models, Qwen2–72B-Instruct significantly outperforms the Mistral-8x22B model in terms of safety. The significance testing (P_value) confirms that Qwen2–72B-Instruct’s performance is not only robust but also reliable, offering a safer alternative for applications that require the handling of sensitive or potentially harmful content.
Accessibility to the AI Community
Qwen2 has been made widely accessible to developers and researchers, marking a significant milestone in the journey toward open-source AI. All models in the Qwen2 series are now available on popular platforms such as Hugging Face and ModelScope, allowing enthusiasts and professionals alike to explore their capabilities, fine-tune them for specific needs, and contribute to their ongoing development.
Access and Usage
Developers can easily access detailed information about each model, including their features, performance metrics, and best-use scenarios, by visiting the model cards on Hugging Face and ModelScope. These resources provide comprehensive guidance on how to effectively utilize the Qwen2 models, whether for research, application development, or further fine-tuning.
Community Support and Contributions
The development of Qwen2 has been a collaborative effort, supported by a broad community of developers, researchers, and organizations. Various teams have played crucial roles in different aspects of Qwen2’s evolution:
- Fine-tuning: Contributions from platforms like Axolotl, Llama-Factory, Firefly, Swift, and XTuner have been instrumental in optimizing Qwen2 for specific tasks.
- Quantization: Tools like AutoGPTQ, AutoAWQ, and Neural Compressor have been used to compress the models, making them more efficient without compromising performance.
- Deployment: Frameworks such as vLLM, SGL, SkyPilot, TensorRT-LLM, OpenVino, and TGI have facilitated the deployment of Qwen2 across various environments.
- API Platforms: Integration with platforms like Together, Fireworks, and OpenRouter has expanded Qwen2’s accessibility through APIs.
- Local Run: Solutions like MLX, Llama.cpp, Ollama, and LM Studio have enabled local execution of Qwen2 models, making them versatile tools for development.
- Agent and RAG Frameworks: Frameworks like LlamaIndex, CrewAI, and OpenDevin have enhanced Qwen2’s capabilities in agent-based systems and Retrieval-Augmented Generation (RAG).
- Evaluation: Contributions from LMSys, OpenCompass, and Open LLM Leaderboard have provided valuable benchmarks and assessments for Qwen2.
- Model Training: Initiatives like Dolphin and Openbuddy have contributed to the training and refinement of Qwen2 models.
This collective effort has not only enriched the Qwen2 series but also fostered a strong community spirit, driving innovation and collaboration in the open-source AI community. While not every contributor is mentioned, their efforts are deeply appreciated, and Alibaba expresses sincere gratitude to all who have supported the project.
Licensing and Openness
In a move to further democratize access to AI, Alibaba has adjusted the licensing of Qwen2 models. The flagship model, Qwen2–72B, along with its instruction-tuned variants, continues to use the original Qianwen License. However, the other models in the series — Qwen2–0.5B, Qwen2–1.5B, Qwen2–7B, and Qwen2–57B-A14B — have adopted the Apache 2.0 license. This shift towards a more open licensing framework is intended to accelerate the adoption, application, and commercial use of Qwen2 across the globe.
By opening up Qwen2 under these licenses, Alibaba aims to empower developers and researchers to explore new frontiers in AI, fostering an environment where innovation can thrive, and the full potential of Qwen2 can be realized. The company remains committed to supporting the global AI community and looks forward to continued collaboration and shared success.
Quick and Easy Qwen2 Installation
Now that we have learned about how powerful Qwen2 can be, let’s look at how you can easily start using this model!
Step 1: Install Ollama
Ollama can be thought of as a platform that helps you easily download and access open-source language models. You can click on this link to reach the download page of Ollama: Ollama Download Page. Ollama can be downloaded on macOS, Linux, and Windows.
Step 2: Installing Qwen2
Once you have installed Ollama, open your command prompt/terminal and execute the following command:
ollama run qwen2:0.5b
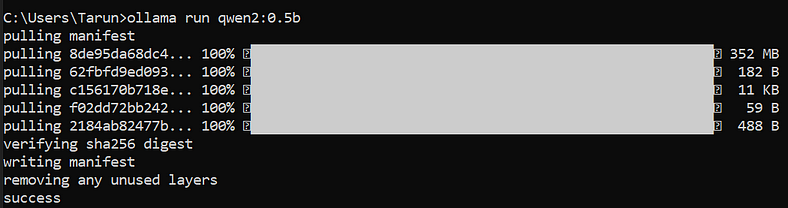
This command will install the Qwen2 model with 0.5 billion parameters. As of the time of this article, you can also install models with 1.5 billion, 7 billion, and 72 billion parameters using the following commands:
ollama run qwen2:1.5bollama run qwen2:7bollama run qwen2:72b
Step 3: Trying Out Qwen2’s Latest Multimodal AI!
Once you download your desired Qwen2 model, you should see the following message request:

If not, you can always run the same command that you ran to install your Qwen2 model!

Conclusions
As we reflect on the launch of Qwen2, it’s clear that this series marks a pivotal moment in the evolution of AI. Alibaba’s commitment to pushing the boundaries of innovation is evident in every aspect of Qwen2, from its diverse model sizes to its sophisticated capabilities in coding, mathematics, and long-context understanding.
Further, the decision to open-source Qwen2 models and adopt more flexible licensing is a significant step towards democratizing access to cutting-edge AI technology. This move not only encourages broader adoption but also fosters a collaborative environment where the global AI community can contribute to and benefit from these advancements.
Moreover, Qwen2’s emphasis on safety and ethical considerations underscores the importance of responsible AI development. By aligning its models with high standards of performance and safety, Qwen2 sets a precedent for future AI systems, demonstrating that intelligence and responsibility can go hand in hand.
In essence, Qwen2 embodies the spirit of collaboration and innovation that drives the AI field forward. As we look ahead, the impact of Qwen2 will likely resonate across various domains, inspiring new applications and advancements. Its journey is a testament to the power of open-source contributions and the collective effort of a global community committed to shaping the future of AI.
References
- Team, Qwen. “Hello Qwen2.” Qwen, 7 June 2024, qwenlm.github.io/blog/qwen2/
- Yang, A., Yang, B., Hui, B., Zheng, B., Yu, B., Zhou, C., Li, C., Li, C., Liu, D., Huang, F., Dong, G., Wei, H., Lin, H., Tang, J., Wang, J., Yang, J., Tu, J., Zhang, J., Ma, J., . . . Fan, Z. (2024). Qwen2 Technical Report. ArXiv. /abs/2407.10671
Catch the latest version of this article over on Medium.com. Hit the button below to join our readers there.






















