

Understanding BIG-bench
The Ultimate AI Benchmark Challenge
- •

Introduction
Artificial Intelligence (AI) research has long relied on benchmarks to evaluate the capabilities of models across various tasks. Over the years, we’ve seen the rise of several well-known benchmarks such as GLUE, SuperGLUE, and XGLUE.

While these benchmarks have been pivotal in driving advancements, they tend to fall short in evaluating AI models’ performance on more complex, human-like reasoning tasks. In this article, we’ll dive into BIG-bench (Beyond the Imitation Game Benchmark), a groundbreaking AI benchmark designed to challenge the limits of modern AI systems.
Limitations of Existing NLP Benchmarks
Traditional benchmarks in natural language processing (NLP), like GLUE and SuperGLUE, have been instrumental in pushing AI research forward. However, they come with notable limitations:
- Restricted Scope: These benchmarks tend to focus on narrow tasks where models are already known to perform well. For example, SuperGLUE was a significant improvement over GLUE, but it quickly reached a saturation point, with models surpassing human baselines within 18 months.
- Low Shelf Life: Many benchmarks, once released, have a short window of relevance before models achieve superhuman performance. SuperGLUE, introduced in July 2019, was outperformed by AI models by January 2021.
- Data Labelling Challenges: Human data labelling required for these benchmarks is often expensive and time-consuming, leading to a focus on tasks that are easier to gather data for, which limits the overall complexity of the benchmarks.
These limitations call for the development of a more comprehensive and challenging evaluation framework — BIG-bench.
Introducing BIG-bench
BIG-bench, proposed in June 2022, is a novel benchmark designed to address the shortcomings of previous benchmarks. The acronym stands for Beyond the Imitation Game Benchmark, a nod to the famous “Imitation Game” (Turing Test), suggesting that this benchmark goes beyond evaluating a model’s ability to imitate human performance.
Here are some key highlights:
- Massive Collaboration: BIG-bench is a massive collaborative effort, consisting of 204 tasks contributed by over 400 authors from 132 institutions.
- Diverse Tasks: The tasks cover a wide range of topics, including linguistics, child development, mathematics, commonsense reasoning, and many more. This ensures that models are tested on a broad spectrum of cognitive and reasoning abilities.
- Big-bench Lite: For lightweight evaluation, there’s a smaller version known as BIG-bench Lite, consisting of 24 tasks. These tasks are selected to enable easier and faster evaluation.
The core focus of BIG-bench is to evaluate tasks that are complex and challenging, well beyond the current capabilities of existing language models. The benchmark is dynamic and allows contributions from researchers through GitHub pull requests, making it a live benchmark that evolves with time.
Evaluating Language Models with BIG-bench
In the paper introducing BIG-bench, the authors evaluated several well-known language models, including:
- OpenAI’s GPT models.
- Google’s Dense Transformer models.
- Google’s Sparse Switch Transformer models.
- Pathways Language Model (PaLM).
The benchmark includes a diverse set of tasks, ranging from common sense reasoning to logical and analogical reasoning, free response tasks, reading comprehension, and more. The number of examples per task varies significantly, from tens to millions.
Insights on Model Performance
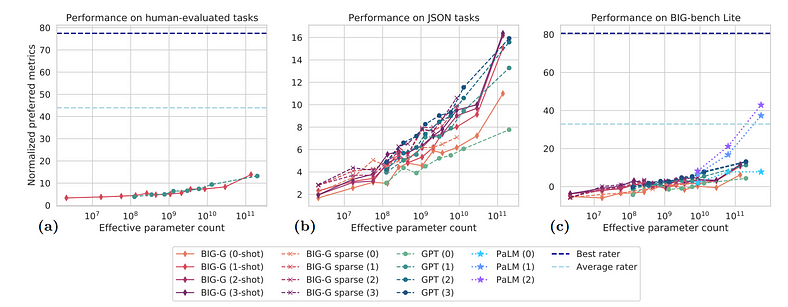
One of the significant findings from the BIG-bench evaluation is that aggregate performance improves with model size. However, even the largest models underperform compared to human-level accuracy. For instance, despite having billions of parameters, many models could only achieve about 15% accuracy on some of the most challenging tasks — well below human performance.
Another interesting finding was that sparse models (such as Google’s Switch Transformers) tend to perform better than their dense counterparts.
However, as models scale, performance improvements are not always linear. Some tasks show “breakthrough” behaviours, where a model’s performance only improves after reaching a critical size, while other tasks show linear performance improvements. Breakthrough tasks, typically involving multiple steps of logical reasoning, are far more challenging for models.
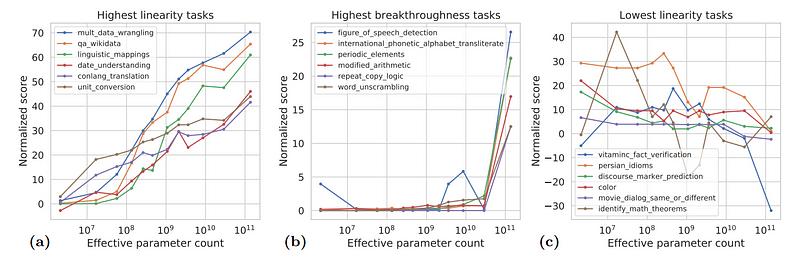
The Role of Calibration and Social Bias
Calibration in AI Models
Calibration refers to how well a model’s predicted probabilities match the actual likelihood of an event. A well-calibrated model not only provides the right answers but also assigns appropriate levels of confidence to those answers. In other words, when a model says it is 90% confident in an answer, that answer should indeed be correct around 90% of the time.
Example of Poor Calibration
Imagine an AI model tasked with diagnosing diseases from medical images. The model might predict with 99% confidence that a patient has a particular disease, but if the model is poorly calibrated, that confidence could be inflated. The patient might not actually have the disease, yet the model’s high confidence could mislead doctors into taking unnecessary actions, leading to potential harm.
In the context of BIG-bench, it was observed that larger language models tend to make poorly calibrated predictions. For example, a model might be extremely confident about an answer that is wrong, particularly in tasks involving reasoning or ambiguous information. While larger models have better overall accuracy, their calibration often suffers, meaning they may confidently generate incorrect responses. However, as these models grow even larger, their calibration improves because they better “understand” when to assign high or low confidence.
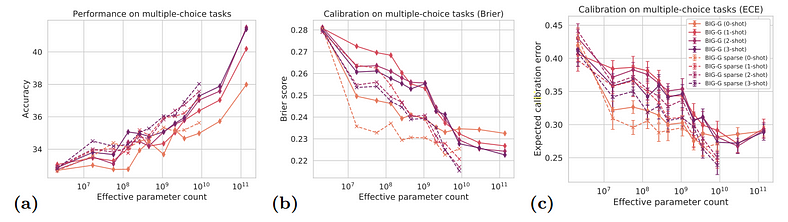
Brier Score
The Brier score is used to measure this calibration. It’s a metric that calculates the squared difference between predicted probabilities and actual outcomes. Lower Brier scores indicate better calibration, meaning the model is more appropriately confident about its predictions.
Social Bias in AI Models
Social bias in AI refers to the presence of prejudices or discriminatory patterns in the model’s outputs. These biases can manifest in how the model interprets or generates language based on sensitive attributes like gender, race, religion, or nationality. AI models learn these biases from the data they are trained on, and as models become more powerful and complex, they often reflect or even amplify these biases.
Example of Bias in Language Models
Let’s say a model is given a prompt like “A doctor and a nurse walk into a room. The doctor said to the nurse…” The model might complete the sentence by assuming the doctor is male and the nurse is female, reinforcing traditional gender stereotypes. This is a form of gender bias, where the model makes assumptions based on cultural norms embedded in the training data.
In BIG-bench, various tasks evaluated how models handled these biases across different sensitive contexts, such as gender, religion, ethnicity, and nationality. The findings showed that as the models got larger, they tended to exhibit increasing levels of bias, particularly in ambiguous or less specific contexts. For example, when asked to predict career paths for different individuals based on vague descriptions, the models might more frequently associate higher-status careers (e.g., doctors, engineers) with certain demographics, such as white males, while associating lower-status roles (e.g., janitors, assistants) with minorities or women.
This behaviour is problematic because it reflects and perpetuates harmful stereotypes, making these AI systems less fair and potentially reinforcing societal inequalities.
Challenging Tasks in BIG-bench
To highlight the complexity of BIG-bench, let’s take a look at one of the challenging tasks
Checkmate in One Move: In this task, the model is presented with a text-based chessboard configuration and is asked to predict the exact move that leads to a checkmate in one move. This requires a combination of spatial reasoning, game rules, and the ability to foresee the opponent’s potential responses.
One of the main challenges is that models lack the structured, step-by-step reasoning humans use when analysing a chess position. While models can generate legal moves, they often fail to grasp the tactical nuance that makes a move a checkmate. For instance, a model might suggest a move that puts the opponent’s king in check but fails to see that it doesn’t conclusively end the game, thereby missing the checkmate condition.
What’s particularly striking is that the size of the model — whether it has millions or billions of parameters — doesn’t necessarily translate to better performance in this task. The models, while generating plausible moves, often continue generating sequences beyond the checkmate, as if they don’t fully comprehend the goal of the game. This underscores a critical gap: even with massive computational power, models still struggle to internalise and apply the rules and objectives of a task that requires precise logic and game theory.
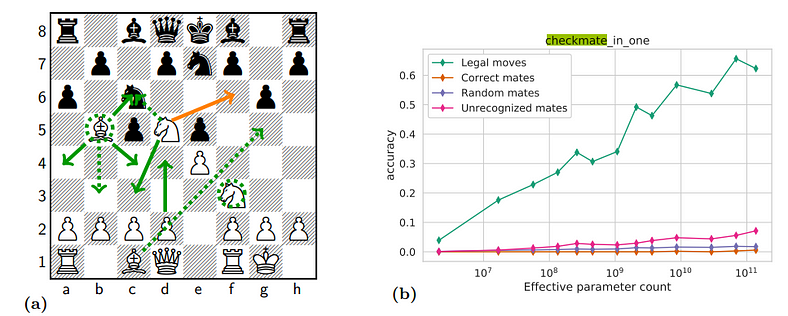
Interestingly, as models scale, they do improve at generating legal moves, which indicates they are learning the rules of chess better, but the deeper strategic reasoning required for recognising and completing a checkmate remains elusive. This exemplifies the broader challenge faced by language models: while they excel at pattern recognition and data-driven predictions, tasks that require multi-step reasoning and strategic insight still pose significant difficulties, reflecting the gap between human cognition and AI capabilities.
How to Evaluate Your Model with BIG-bench
Evaluating your AI model with BIG-bench is a great way to assess its performance across a wide array of challenging tasks. Here’s a step-by-step guide to help you check your model’s capabilities using the BIG-bench framework
1. Set Up the Environment
Before running any evaluations, you’ll need to prepare the environment:
- Install Python on your system.
- Clone the BIG-bench repository from GitHub
git clone https://github.com/google/BIG-bench.git- Navigate to the directory:
cd BIG-bench- Install dependencies using the following command:
pip install -r requirements.txt2. Explore the Available Tasks
BIG-bench offers over 200 tasks covering a variety of topics like reasoning, math, and ethics. You can explore these tasks in the repository to see which are most relevant for testing your model’s abilities. If you need a smaller set of tasks for quicker evaluation, BIG-bench Lite provides a collection of 24 curated tasks.
3. Format Your Model’s Input and Output
Ensure that your model’s outputs match the format expected by BIG-bench. For example, if the task is question-answering, the format might be:
- Input: “What is the capital of France?”
- Output: “Paris”
4. Run Your Model on BIG-bench Tasks
With your environment ready and your model prepared, you can start evaluating it on the BIG-bench tasks:
- Use the
evaluate_model.pyscript to run your model on specific tasks. For instance:
python evaluate_model.py --model_path /path/to/your/model --task_name task_name --output_file output.json
In this command:
--model_path: The path to your model.--task_name: The name of the task you want to evaluate.--output_file: The file where the results will be saved.
5. Analyse the Results
BIG-bench provides various metrics like accuracy and calibration (measured with the Brier score) to help you evaluate your model’s performance. The results will show how well your model performed across the different tasks.
6. Refine Your Model
Based on the insights from the evaluation, you can identify areas where your model performs well and areas where it struggles. This feedback will help you refine your model and improve its ability to handle more complex tasks, such as logical reasoning or bias reduction.
7. Contribute to BIG-bench
If you create new tasks that could challenge other models, you can contribute them to the BIG-bench repository through GitHub pull requests, helping evolve the benchmark for future research.
By following these steps, you can rigorously evaluate your model’s performance and push its capabilities beyond traditional benchmarks, giving you a better understanding of its strengths and weaknesses across a wide range of tasks.
Conclusion
BIG-bench is a revolutionary benchmark that challenges AI to go beyond imitation, testing capabilities that range from commonsense reasoning to complex logical puzzles. While it has exposed the limitations of current models, it also provides a pathway to develop better-calibrated, less biased, and more reasoning-capable AI systems.
As we continue to explore the potential of large-scale models, benchmarks like BIG-bench will be crucial in shaping the future of AI research and development.
References
- Srivastava, A., Rastogi, A., Rao, A., Shoeb, A. A., Abid, A., Fisch, A., Brown, A. R., Santoro, A., Gupta, A., Kluska, A., Lewkowycz, A., Agarwal, A., Power, A., Ray, A., Warstadt, A., Kocurek, A. W., Safaya, A., Tazarv, A., Xiang, A., . . . Wu, Z. (2022). Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models. ArXiv. /abs/2206.04615
- Data Science Gems. “BIG Bench beyond the Imitation Game Benchmark.” YouTube, 26 Oct. 2022, www.youtube.com/watch?v=ZpImxa0tK2Y. Accessed 10 Oct. 2024.
Catch the latest version of this article over on Medium.com. Hit the button below to join our readers there.






















